 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Word Clusters Using Signed Normalized Graph Cuts
Jan 20, 2016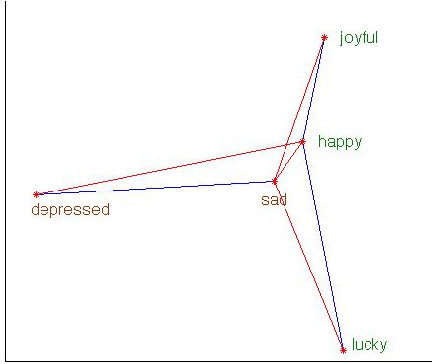
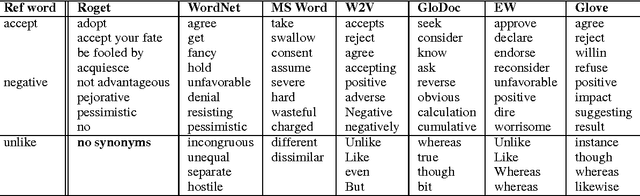
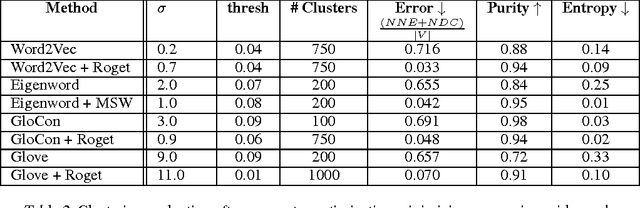
Vector space representations of words capture many aspects of word similarity, but such methods tend to make vector spaces in which antonyms (as well as synonyms) are close to each other. We present a new signed spectral normalized graph cut algorithm, signed clustering, that overlays existing thesauri upon distributionally derived vector representations of words, so that antonym relationships between word pairs are represented by negative weights. Our signed clustering algorithm produces clusters of words which simultaneously capture distributional and synonym relations. We evaluate these clusters against the SimLex-999 dataset (Hill et al.,2014) of human judgments of word pair similarities, and also show the benefit of using our clusters to predict the sentiment of a given text.
Spectral Theory of Unsigned and Signed Graphs. Applications to Graph Clustering: a Survey
Jan 18, 2016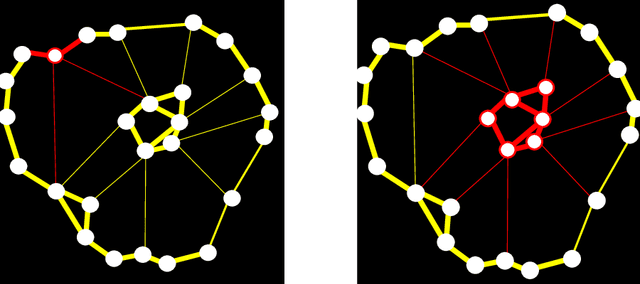
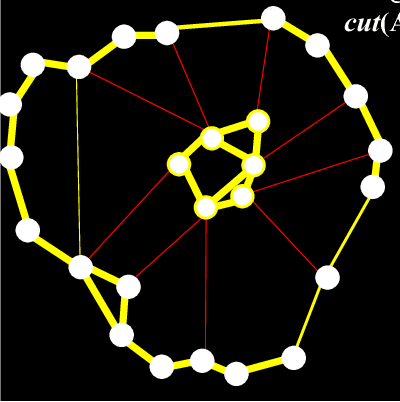
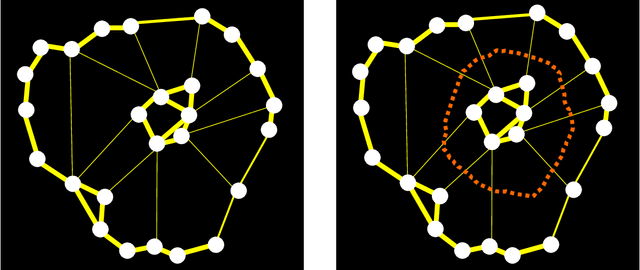
This is a survey of the method of graph cuts and its applications to graph clustering of weighted unsigned and signed graphs. I provide a fairly thorough treatment of the method of normalized graph cuts, a deeply original method due to Shi and Malik, including complete proofs. The main thrust of this paper is the method of normalized cuts. I give a detailed account for K = 2 clusters, and also for K > 2 clusters, based on the work of Yu and Shi. I also show how both graph drawing and normalized cut K-clustering can be easily generalized to handle signed graphs, which are weighted graphs in which the weight matrix W may have negative coefficients. Intuitively, negative coefficients indicate distance or dissimilarity. The solution is to replace the degree matrix by the matrix in which absolute values of the weights are used, and to replace the Laplacian by the Laplacian with the new degree matrix of absolute values. As far as I know, the generalization of K-way normalized clustering to signed graphs is new. Finally, I show how the method of ratio cuts, in which a cut is normalized by the size of the cluster rather than its volume, is just a special case of normalized cuts.
Notes on Elementary Spectral Graph Theory. Applications to Graph Clustering Using Normalized Cuts
Nov 11, 2013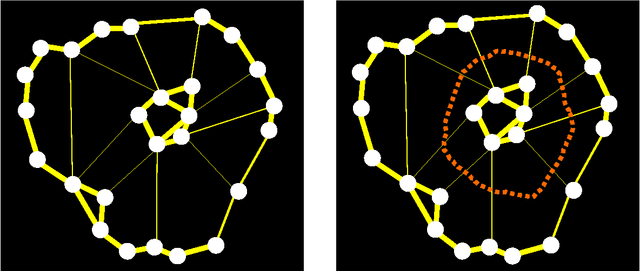
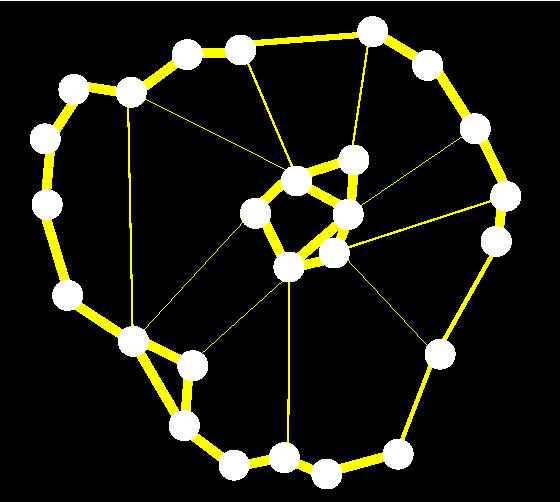
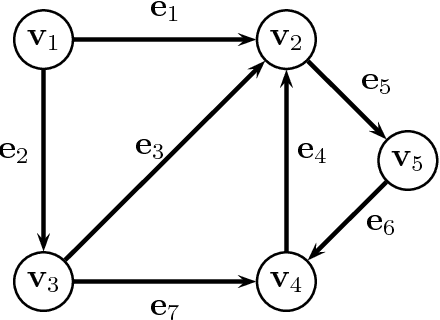
These are notes on the method of normalized graph cuts and its applications to graph clustering. I provide a fairly thorough treatment of this deeply original method due to Shi and Malik, including complete proofs. I include the necessary background on graphs and graph Laplacians. I then explain in detail how the eigenvectors of the graph Laplacian can be used to draw a graph. This is an attractive application of graph Laplacians. The main thrust of this paper is the method of normalized cuts. I give a detailed account for K = 2 clusters, and also for K > 2 clusters, based on the work of Yu and Shi. Three points that do not appear to have been clearly articulated before are elaborated: 1. The solutions of the main optimization problem should be viewed as tuples in the K-fold cartesian product of projective space RP^{N-1}. 2. When K > 2, the solutions of the relaxed problem should be viewed as elements of the Grassmannian G(K,N). 3. Two possible Riemannian distances are available to compare the closeness of solutions: (a) The distance on (RP^{N-1})^K. (b) The distance on the Grassmannian. I also clarify what should be the necessary and sufficient conditions for a matrix to represent a partition of the vertices of a graph to be clustered.
The Completeness of Propositional Resolution: A Simple and Constructive<br> Proof
Nov 07, 2006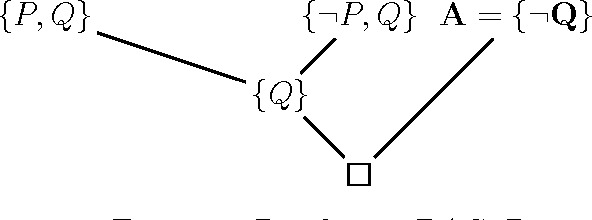
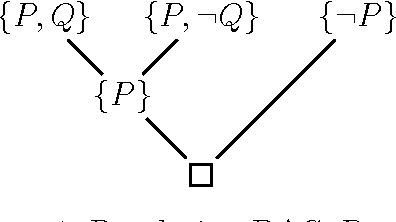
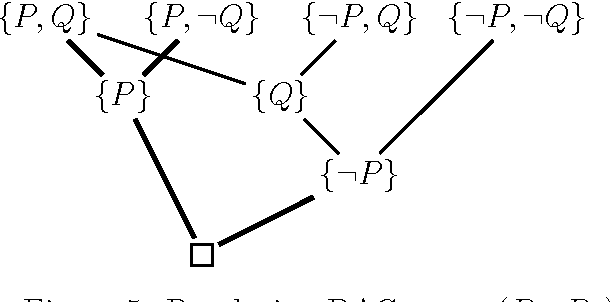
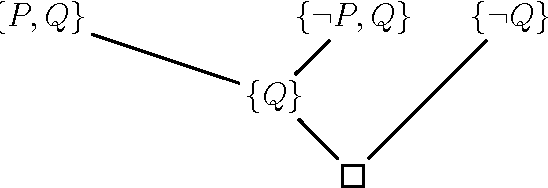
It is well known that the resolution method (for propositional logic) is complete. However, completeness proofs found in the literature use an argument by contradiction showing that if a set of clauses is unsatisfiable, then it must have a resolution refutation. As a consequence, none of these proofs actually gives an algorithm for producing a resolution refutation from an unsatisfiable set of clauses. In this note, we give a simple and constructive proof of the completeness of propositional resolution which consists of an algorithm together with a proof of its correctness.
* 7 pages, submitted to LMCS