 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Position Bias for Robust Aspect Sentiment Classification
May 29, 2021
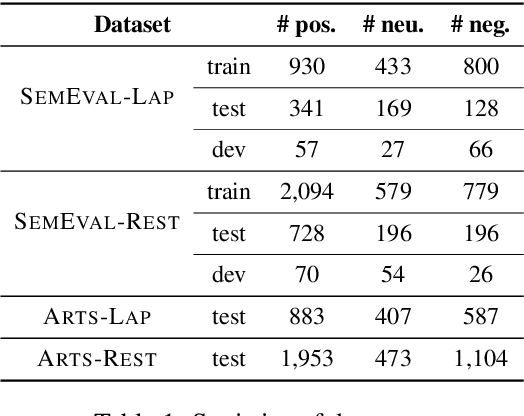
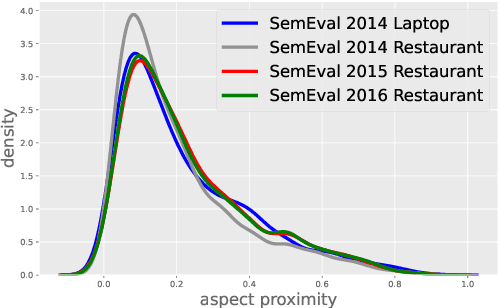
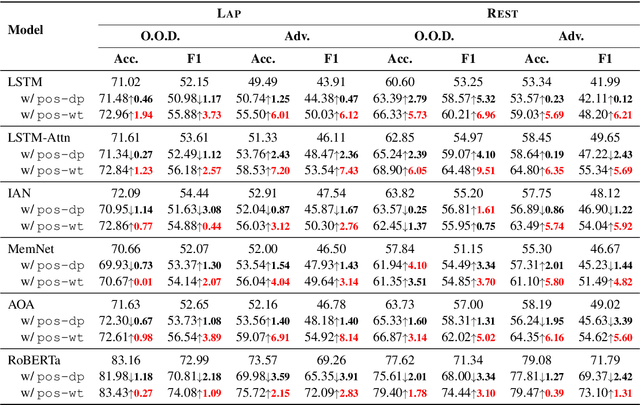
Aspect sentiment classification (ASC) aims at determining sentiments expressed towards different aspects in a sentence. While state-of-the-art ASC models have achieved remarkable performance, they are recently shown to suffer from the issue of robustness. Particularly in two common scenarios: when domains of test and training data are different (out-of-domain scenario) or test data is adversarially perturbed (adversarial scenario), ASC models may attend to irrelevant words and neglect opinion expressions that truly describe diverse aspects. To tackle the challenge, in this paper, we hypothesize that position bias (i.e., the words closer to a concerning aspect would carry a higher degree of importance) is crucial for building more robust ASC models by reducing the probability of mis-attending. Accordingly, we propose two mechanisms for capturing position bias, namely position-biased weight and position-biased dropout, which can be flexibly injected into existing models to enhance representations for classification. Experiments conducted on out-of-domain and adversarial datasets demonstrate that our proposed approaches largely improve the robustness and effectiveness of current models.
Quantum Cognitively Motivated Decision Fusion for Video Sentiment Analysis
Jan 12, 2021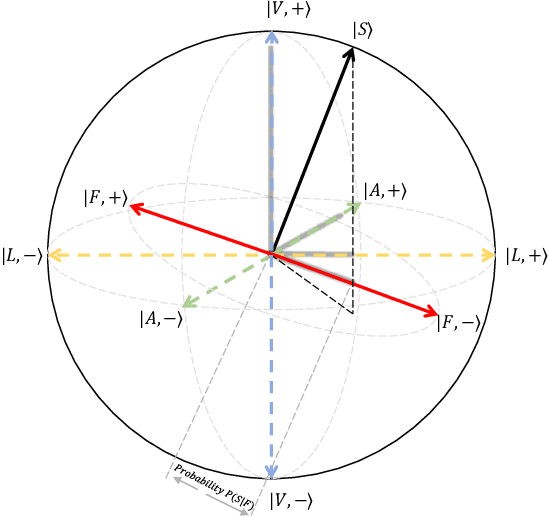
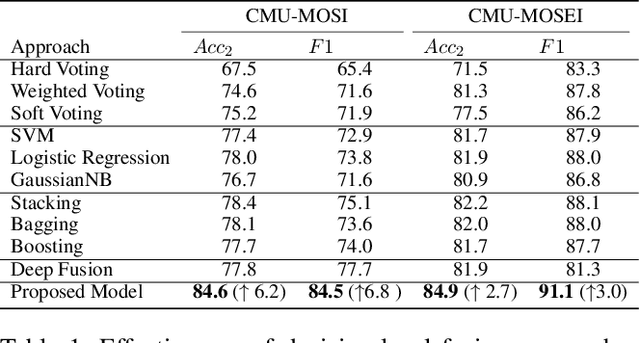
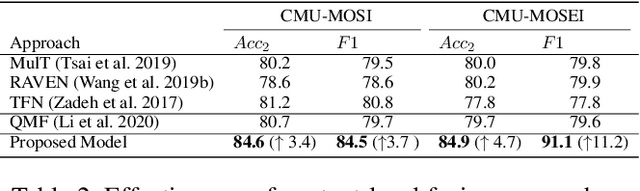
Video sentiment analysis as a decision-making process is inherently complex, involving the fusion of decisions from multiple modalities and the so-caused cognitive biases. Inspired by recent advances in quantum cognition, we show that the sentiment judgment from one modality could be incompatible with the judgment from another, i.e., the order matters and they cannot be jointly measured to produce a final decision. Thus the cognitive process exhibits "quantum-like" biases that cannot be captured by classical probability theories. Accordingly, we propose a fundamentally new, quantum cognitively motivated fusion strategy for predicting sentiment judgments. In particular, we formulate utterances as quantum superposition states of positive and negative sentiment judgments, and uni-modal classifiers as mutually incompatible observables, on a complex-valued Hilbert space with positive-operator valued measures. Experiments on two benchmarking datasets illustrate that our model significantly outperforms various existing decision level and a range of state-of-the-art content-level fusion approaches. The results also show that the concept of incompatibility allows effective handling of all combination patterns, including those extreme cases that are wrongly predicted by all uni-modal classifiers.
A Multi-task Learning Framework for Opinion Triplet Extraction
Oct 04, 2020
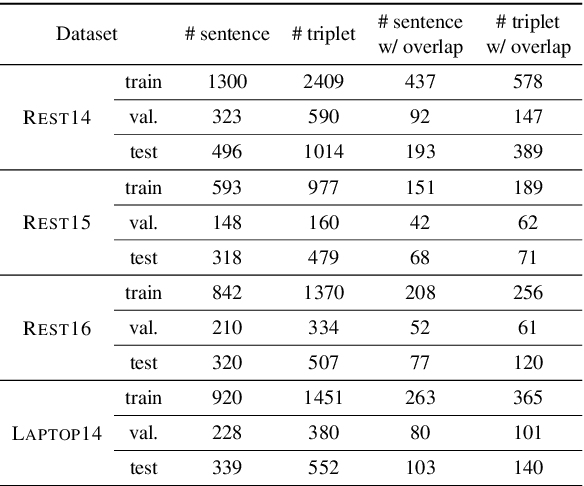
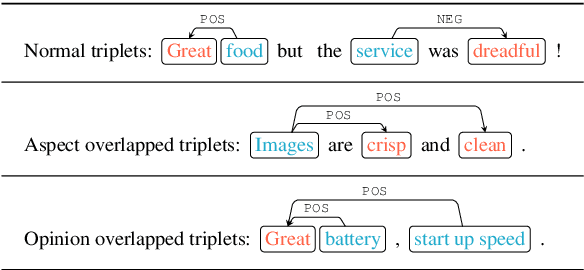
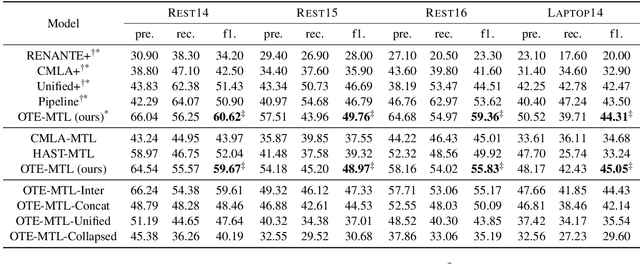
The state-of-the-art Aspect-based Sentiment Analysis (ABSA) approaches are mainly based on either detecting aspect terms and their corresponding sentiment polarities, or co-extracting aspect and opinion terms. However, the extraction of aspect-sentiment pairs lacks opinion terms as a reference, while co-extraction of aspect and opinion terms would not lead to meaningful pairs without determining their sentiment dependencies. To address the issue, we present a novel view of ABSA as an opinion triplet extraction task, and propose a multi-task learning framework to jointly extract aspect terms and opinion terms, and simultaneously parses sentiment dependencies between them with a biaffine scorer. At inference phase, the extraction of triplets is facilitated by a triplet decoding method based on the above outputs. We evaluate the proposed framework on four SemEval benchmarks for ASBA. The results demonstrate that our approach significantly outperforms a range of strong baselines and state-of-the-art approaches.
Redundancy of Hidden Layers in Deep Learning: An Information Perspective
Sep 19, 2020
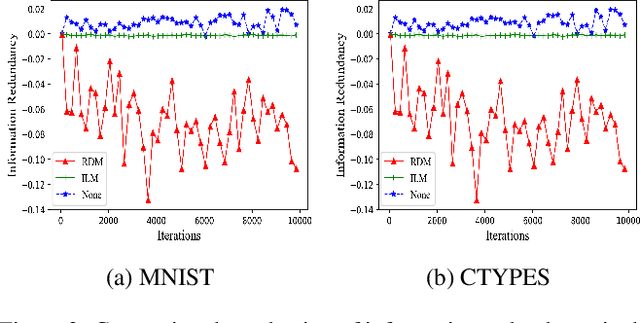
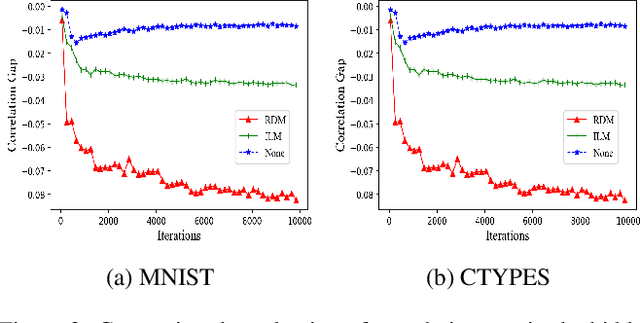
Although the deep structure guarantees the powerful expressivity of deep networks (DNNs), it also triggers serious overfitting problem. To improve the generalization capacity of DNNs, many strategies were developed to improve the diversity among hidden units. However, most of these strategies are empirical and heuristic in absence of either a theoretical derivation of the diversity measure or a clear connection from the diversity to the generalization capacity. In this paper, from an information theoretic perspective, we introduce a new definition of redundancy to describe the diversity of hidden units under supervised learning settings by formalizing the effect of hidden layers on the generalization capacity as the mutual information. We prove an opposite relationship existing between the defined redundancy and the generalization capacity, i.e., the decrease of redundancy generally improving the generalization capacity. The experiments show that the DNNs using the redundancy as the regularizer can effectively reduce the overfitting and decrease the generalization error, which well supports above points.
End-to-end Emotion-Cause Pair Extraction via Learning to Link
Feb 25, 2020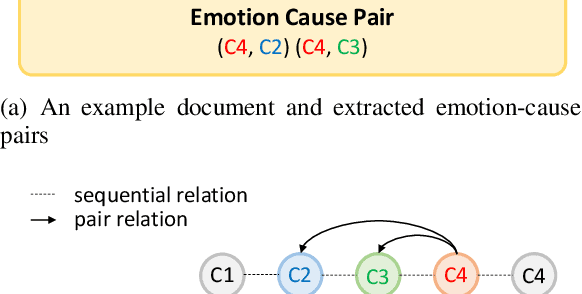
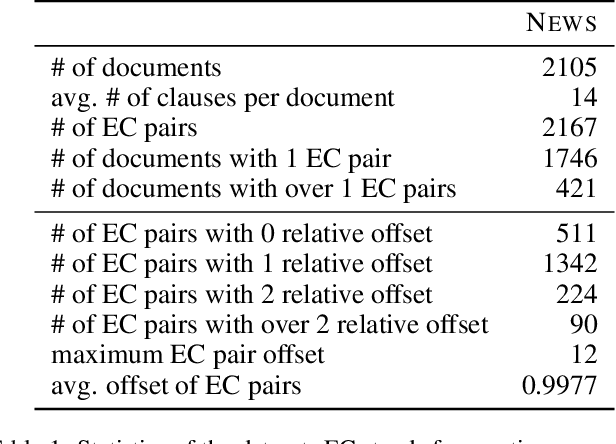
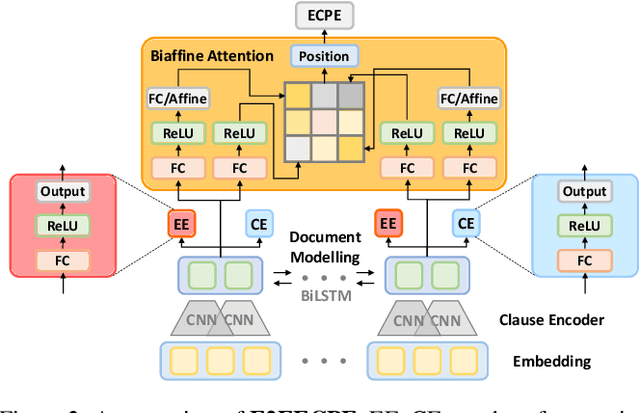
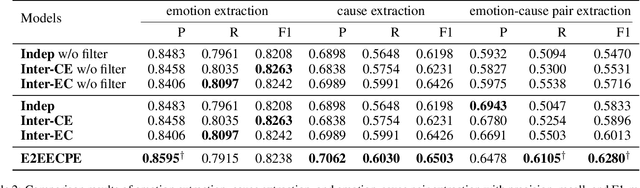
Emotion-cause pair extraction (ECPE), as an emergent natural language processing task, aims at jointly investigating emotions and their underlying causes in documents. It extends the previous emotion cause extraction (ECE) task, yet without requiring a set of pre-given emotion clauses as in ECE. Existing approaches to ECPE generally adopt a two-stage method, i.e., (1) emotion and cause detection, and then (2) pairing the detected emotions and causes. Such pipeline method, while intuitive, suffers from two critical issues, including error propagation across stages that may hinder the effectiveness, and high computational cost that would limit the practical application of the method. To tackle these issues, we propose a multi-task learning model that can extract emotions, causes and emotion-cause pairs simultaneously in an end-to-end manner. Specifically, our model regards pair extraction as a link prediction task, and learns to link from emotion clauses to cause clauses, i.e., the links are directional. Emotion extraction and cause extraction are incorporated into the model as auxiliary tasks, which further boost the pair extraction. Experiments are conducted on an ECPE benchmarking dataset. The results show that our proposed model outperforms a range of state-of-the-art approaches in terms of both effectiveness and efficiency.
Assessing the Memory Ability of Recurrent Neural Networks
Feb 18, 2020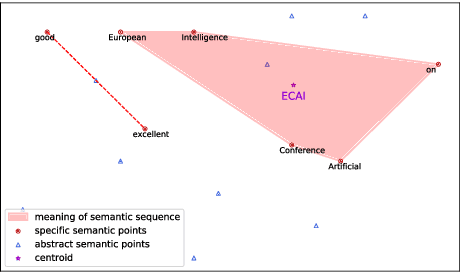
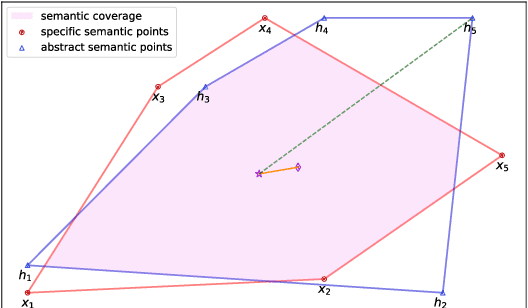
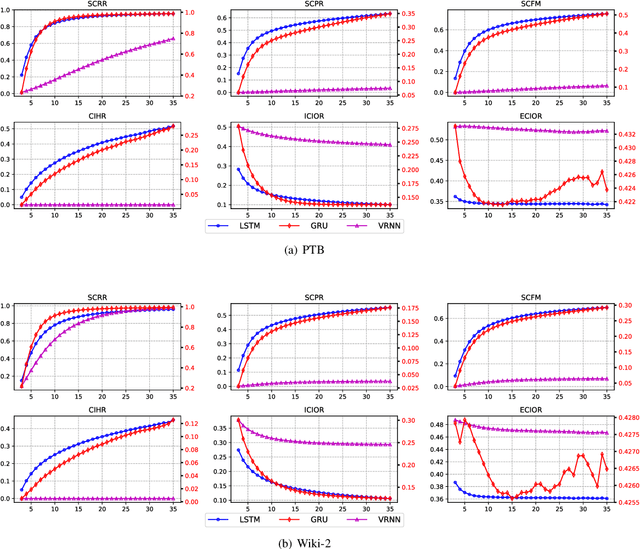
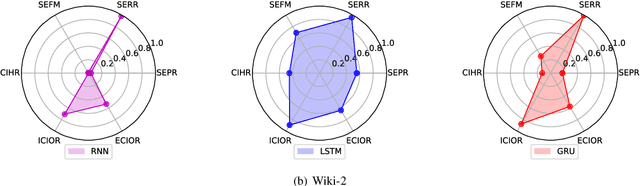
It is known that Recurrent Neural Networks (RNNs) can remember, in their hidden layers, part of the semantic information expressed by a sequence (e.g., a sentence) that is being processed. Different types of recurrent units have been designed to enable RNNs to remember information over longer time spans. However, the memory abilities of different recurrent units are still theoretically and empirically unclear, thus limiting the development of more effective and explainable RNNs. To tackle the problem, in this paper, we identify and analyze the internal and external factors that affect the memory ability of RNNs, and propose a Semantic Euclidean Space to represent the semantics expressed by a sequence. Based on the Semantic Euclidean Space, a series of evaluation indicators are defined to measure the memory abilities of different recurrent units and analyze their limitations. These evaluation indicators also provide a useful guidance to select suitable sequence lengths for different RNNs during training.
Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks
Oct 13, 2019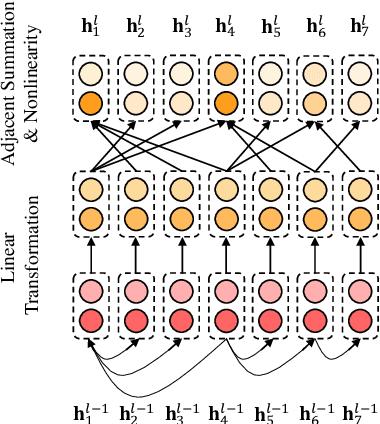
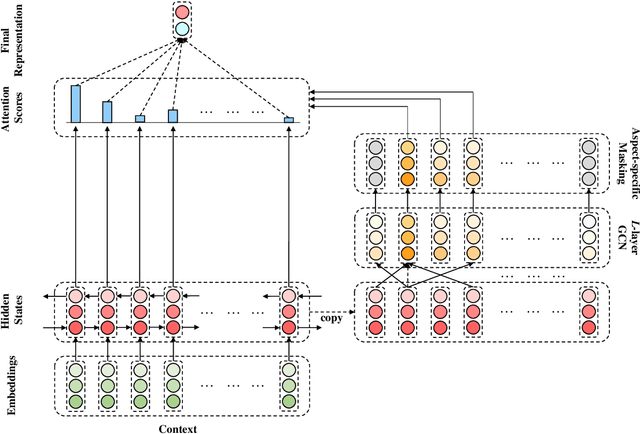
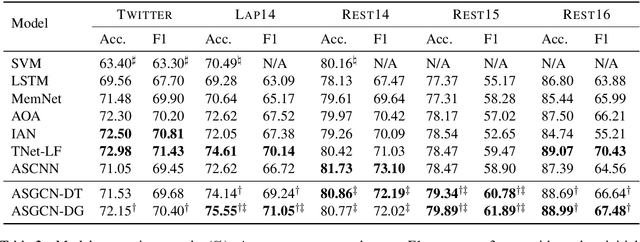
Due to their inherent capability in semantic alignment of aspects and their context words, attention mechanism and Convolutional Neural Networks (CNNs) are widely applied for aspect-based sentiment classification. However, these models lack a mechanism to account for relevant syntactical constraints and long-range word dependencies, and hence may mistakenly recognize syntactically irrelevant contextual words as clues for judging aspect sentiment. To tackle this problem, we propose to build a Graph Convolutional Network (GCN) over the dependency tree of a sentence to exploit syntactical information and word dependencies. Based on it, a novel aspect-specific sentiment classification framework is raised. Experiments on three benchmarking collections illustrate that our proposed model has comparable effectiveness to a range of state-of-the-art models, and further demonstrate that both syntactical information and long-range word dependencies are properly captured by the graph convolution structure.
Syntax-Aware Aspect-Level Sentiment Classification with Proximity-Weighted Convolution Network
Sep 23, 2019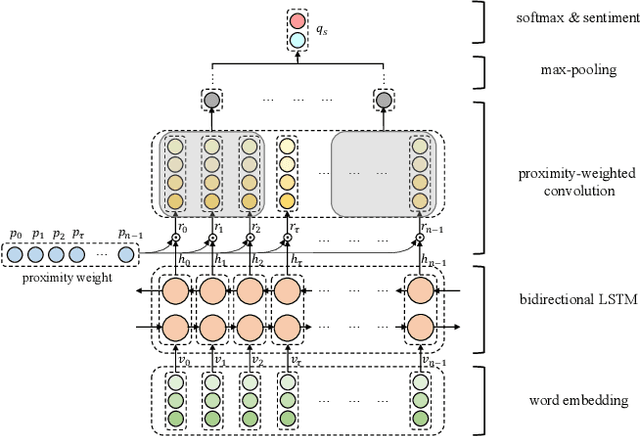
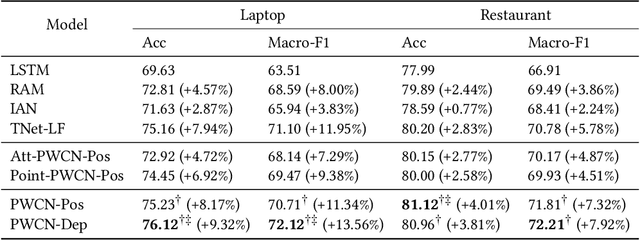


It has been widely accepted that Long Short-Term Memory (LSTM) network, coupled with attention mechanism and memory module, is useful for aspect-level sentiment classification. However, existing approaches largely rely on the modelling of semantic relatedness of an aspect with its context words, while to some extent ignore their syntactic dependencies within sentences. Consequently, this may lead to an undesirable result that the aspect attends on contextual words that are descriptive of other aspects. In this paper, we propose a proximity-weighted convolution network to offer an aspect-specific syntax-aware representation of contexts. In particular, two ways of determining proximity weight are explored, namely position proximity and dependency proximity. The representation is primarily abstracted by a bidirectional LSTM architecture and further enhanced by a proximity-weighted convolution. Experiments conducted on the SemEval 2014 benchmark demonstrate the effectiveness of our proposed approach compared with a range of state-of-the-art models.
A Tensorized Transformer for Language Modeling
Aug 09, 2019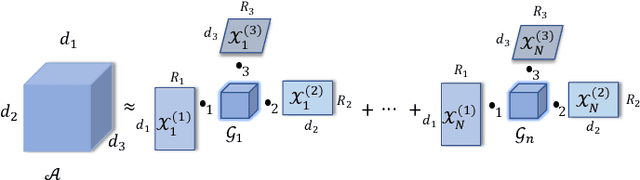
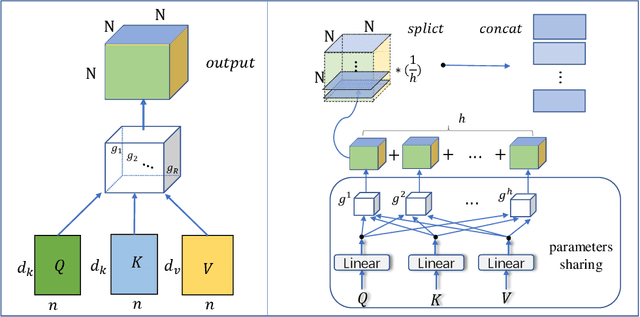
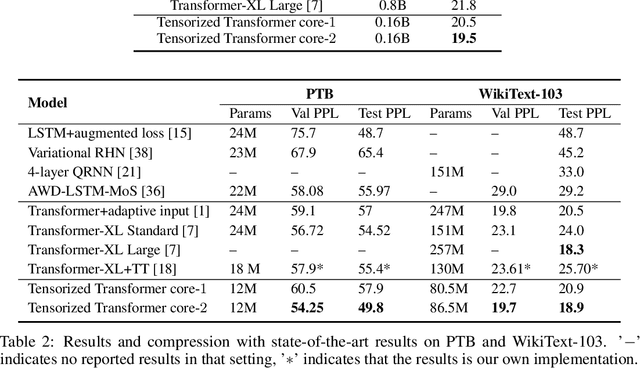

Latest development of neural models has connected the encoder and decoder through a self-attention mechanism. In particular, Transformer, which is solely based on self-attention, has led to breakthroughs in Natural Language Processing (NLP) tasks. However, the multi-head attention mechanism, as a key component of Transformer, limits the effective deployment of the model to a limited resource setting. In this paper, based on the ideas of tensor decomposition and parameters sharing, we propose a novel self-attention model (namely Multi-linear attention) with Block-Term Tensor Decomposition (BTD). We test and verify the proposed attention method on three language modeling tasks (i.e., PTB, WikiText-103 and One-billion) and a neural machine translation task (i.e., WMT-2016 English-German). Multi-linear attention can not only largely compress the model parameters but also obtain performance improvements, compared with a number of language modeling approaches, such as Transformer, Transformer-XL, and Transformer with tensor train decomposition.
ScenarioSA: A Large Scale Conversational Database for Interactive Sentiment Analysis
Jul 12, 2019
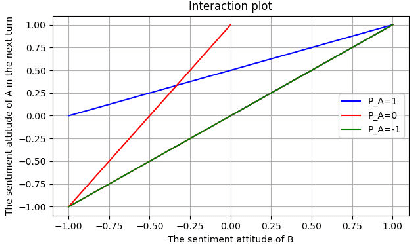
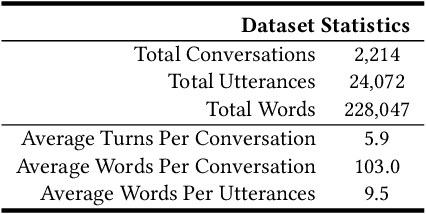
Interactive sentiment analysis is an emerging, yet challenging, subtask of the sentiment analysis problem. It aims to discover the affective state and sentimental change of each person in a conversation. Existing sentiment analysis approaches are insufficient in modelling the interactions among people. However, the development of new approaches are critically limited by the lack of labelled interactive sentiment datasets. In this paper, we present a new conversational emotion database that we have created and made publically available, namely ScenarioSA. We manually label 2,214 multi-turn English conversations collected from natural contexts. In comparison with existing sentiment datasets, ScenarioSA (1) covers a wide range of scenarios; (2) describes the interactions between two speakers; and (3) reflects the sentimental evolution of each speaker over the course of a conversation. Finally, we evaluate various state-of-the-art algorithms on ScenarioSA, demonstrating the need of novel interactive sentiment analysis models and the potential of ScenarioSA to facilitate the development of such models.