 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Methods for Deep Reinforcement Learning
Jun 16, 2016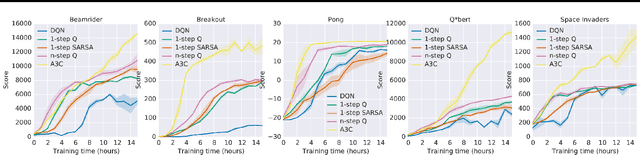

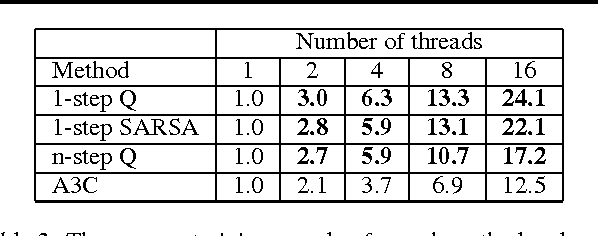
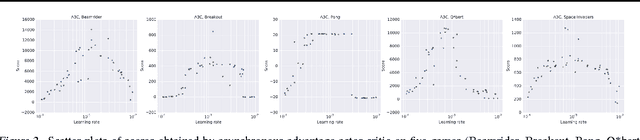
We propose a conceptually simple and lightweight framework for deep reinforcement learning that uses asynchronous gradient descent for optimization of deep neural network controllers. We present asynchronous variants of four standard reinforcement learning algorithms and show that parallel actor-learners have a stabilizing effect on training allowing all four methods to successfully train neural network controllers. The best performing method, an asynchronous variant of actor-critic, surpasses the current state-of-the-art on the Atari domain while training for half the time on a single multi-core CPU instead of a GPU. Furthermore, we show that asynchronous actor-critic succeeds on a wide variety of continuous motor control problems as well as on a new task of navigating random 3D mazes using a visual input.
Continuous control with deep reinforcement learning
Feb 29, 2016
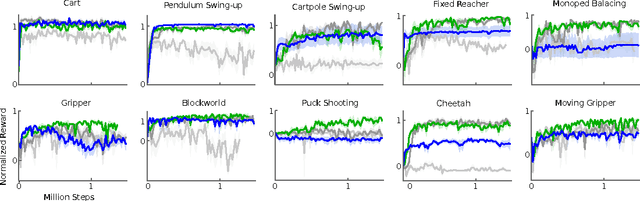
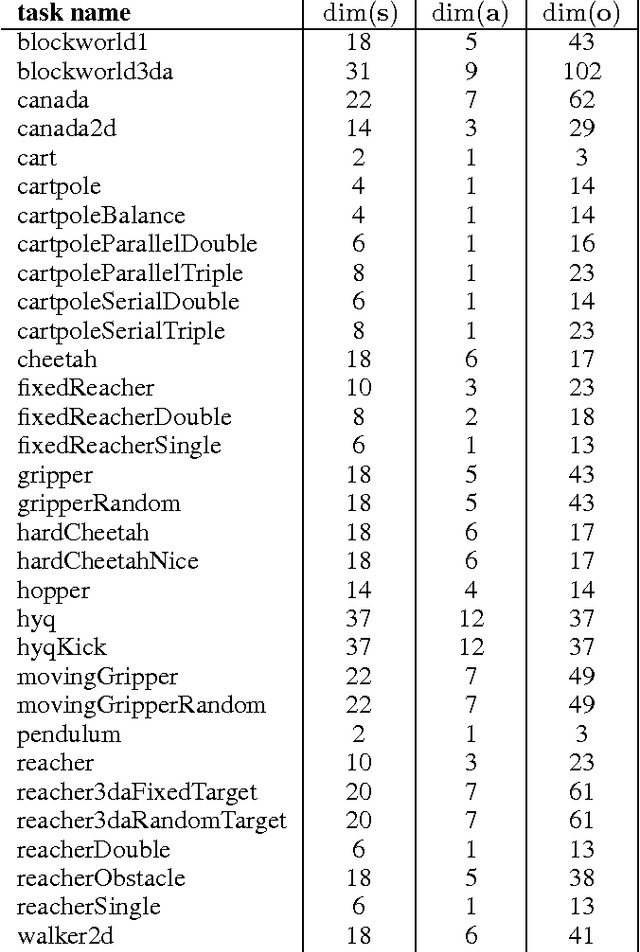
We adapt the ideas underlying the success of Deep Q-Learning to the continuous action domain. We present an actor-critic, model-free algorithm based on the deterministic policy gradient that can operate over continuous action spaces. Using the same learning algorithm, network architecture and hyper-parameters, our algorithm robustly solves more than 20 simulated physics tasks, including classic problems such as cartpole swing-up, dexterous manipulation, legged locomotion and car driving. Our algorithm is able to find policies whose performance is competitive with those found by a planning algorithm with full access to the dynamics of the domain and its derivatives. We further demonstrate that for many of the tasks the algorithm can learn policies end-to-end: directly from raw pixel inputs.
Prioritized Experience Replay
Feb 25, 2016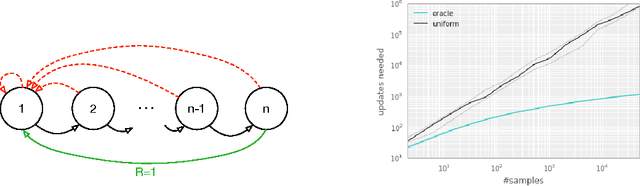
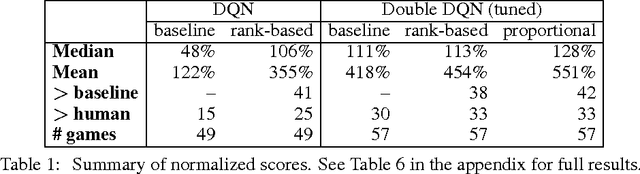
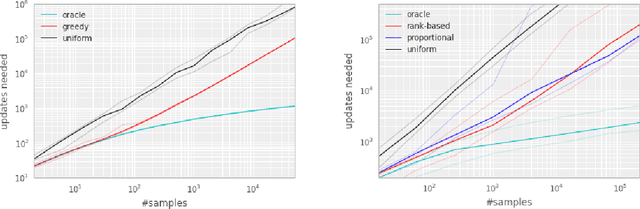

Experience replay lets online reinforcement learning agents remember and reuse experiences from the past. In prior work, experience transitions were uniformly sampled from a replay memory. However, this approach simply replays transitions at the same frequency that they were originally experienced, regardless of their significance. In this paper we develop a framework for prioritizing experience, so as to replay important transitions more frequently, and therefore learn more efficiently. We use prioritized experience replay in Deep Q-Networks (DQN), a reinforcement learning algorithm that achieved human-level performance across many Atari games. DQN with prioritized experience replay achieves a new state-of-the-art, outperforming DQN with uniform replay on 41 out of 49 games.
Memory-based control with recurrent neural networks
Dec 14, 2015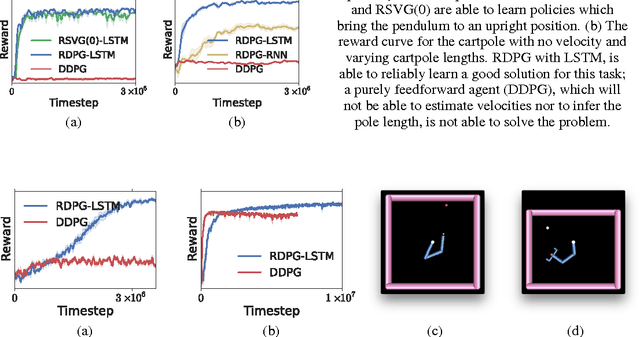
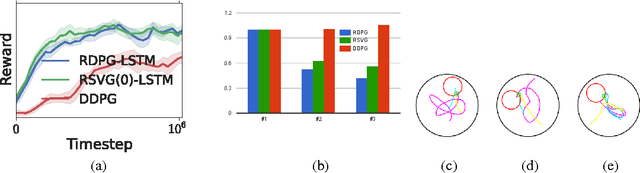
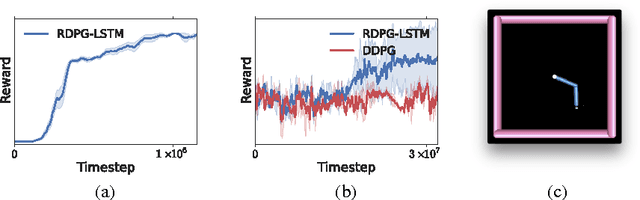
Partially observed control problems are a challenging aspect of reinforcement learning. We extend two related, model-free algorithms for continuous control -- deterministic policy gradient and stochastic value gradient -- to solve partially observed domains using recurrent neural networks trained with backpropagation through time. We demonstrate that this approach, coupled with long-short term memory is able to solve a variety of physical control problems exhibiting an assortment of memory requirements. These include the short-term integration of information from noisy sensors and the identification of system parameters, as well as long-term memory problems that require preserving information over many time steps. We also demonstrate success on a combined exploration and memory problem in the form of a simplified version of the well-known Morris water maze task. Finally, we show that our approach can deal with high-dimensional observations by learning directly from pixels. We find that recurrent deterministic and stochastic policies are able to learn similarly good solutions to these tasks, including the water maze where the agent must learn effective search strategies.
Deep Reinforcement Learning with Double Q-learning
Dec 08, 2015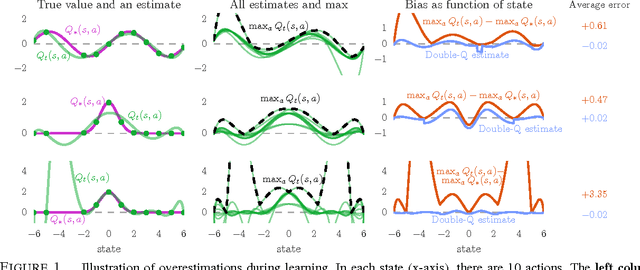
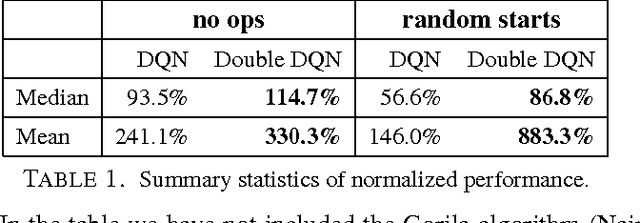
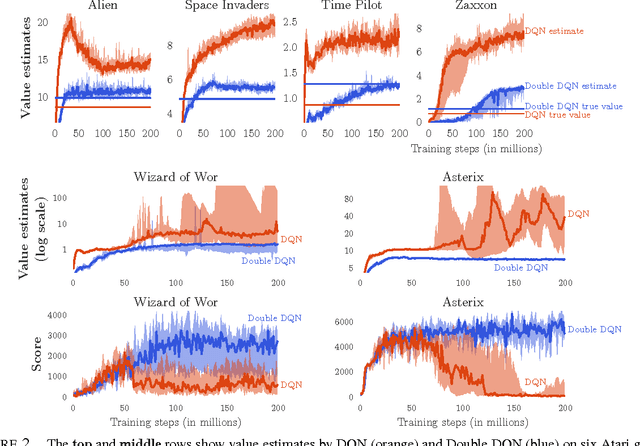
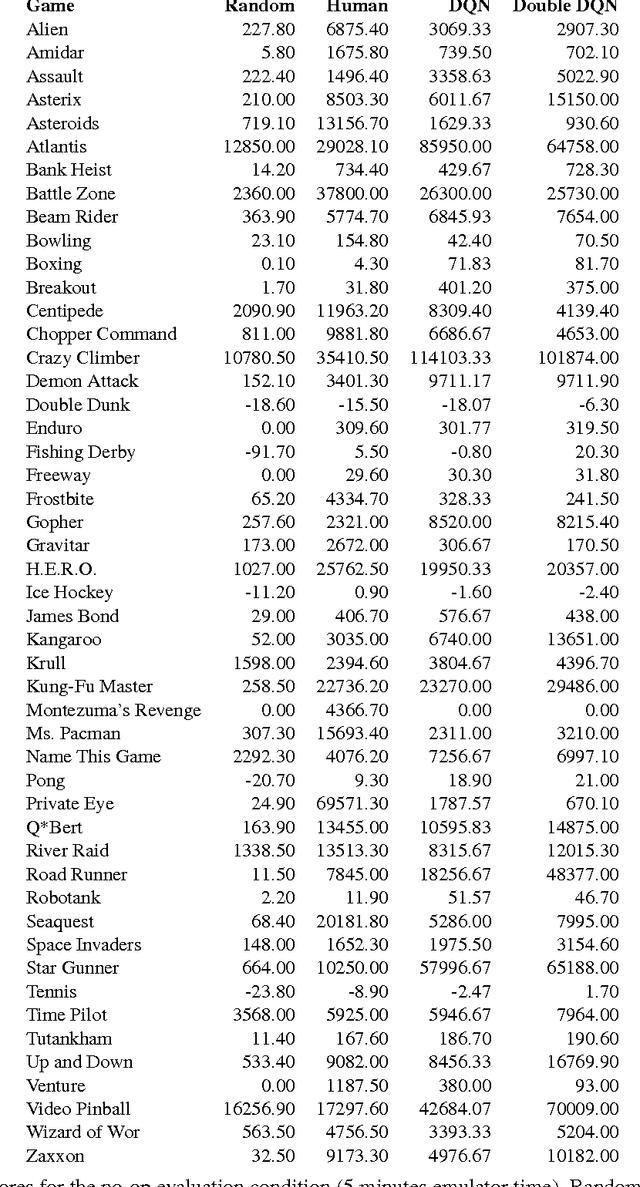
The popular Q-learning algorithm is known to overestimate action values under certain conditions. It was not previously known whether, in practice, such overestimations are common, whether they harm performance, and whether they can generally be prevented. In this paper, we answer all these questions affirmatively. In particular, we first show that the recent DQN algorithm, which combines Q-learning with a deep neural network, suffers from substantial overestimations in some games in the Atari 2600 domain. We then show that the idea behind the Double Q-learning algorithm, which was introduced in a tabular setting, can be generalized to work with large-scale function approximation. We propose a specific adaptation to the DQN algorithm and show that the resulting algorithm not only reduces the observed overestimations, as hypothesized, but that this also leads to much better performance on several games.
Learning Continuous Control Policies by Stochastic Value Gradients
Oct 30, 2015
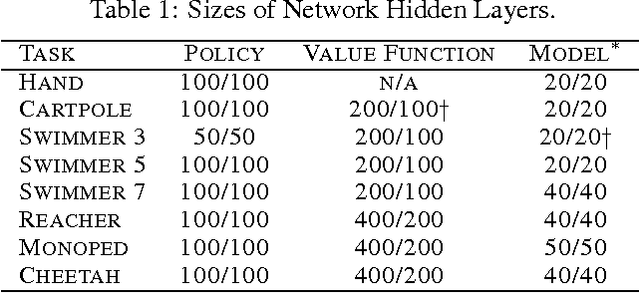
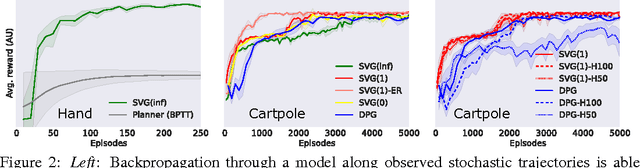
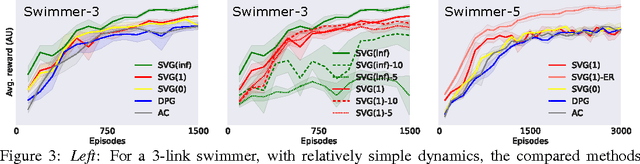
We present a unified framework for learning continuous control policies using backpropagation. It supports stochastic control by treating stochasticity in the Bellman equation as a deterministic function of exogenous noise. The product is a spectrum of general policy gradient algorithms that range from model-free methods with value functions to model-based methods without value functions. We use learned models but only require observations from the environment in- stead of observations from model-predicted trajectories, minimizing the impact of compounded model errors. We apply these algorithms first to a toy stochastic control problem and then to several physics-based control problems in simulation. One of these variants, SVG(1), shows the effectiveness of learning models, value functions, and policies simultaneously in continuous domains.
Massively Parallel Methods for Deep Reinforcement Learning
Jul 16, 2015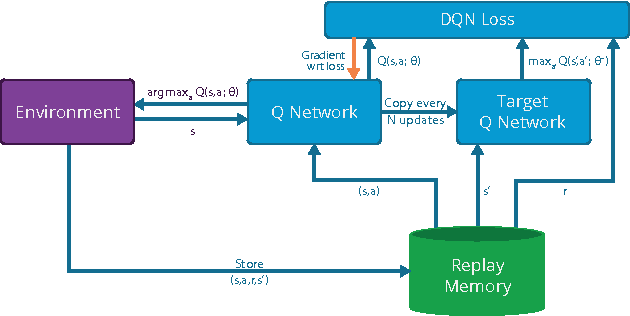
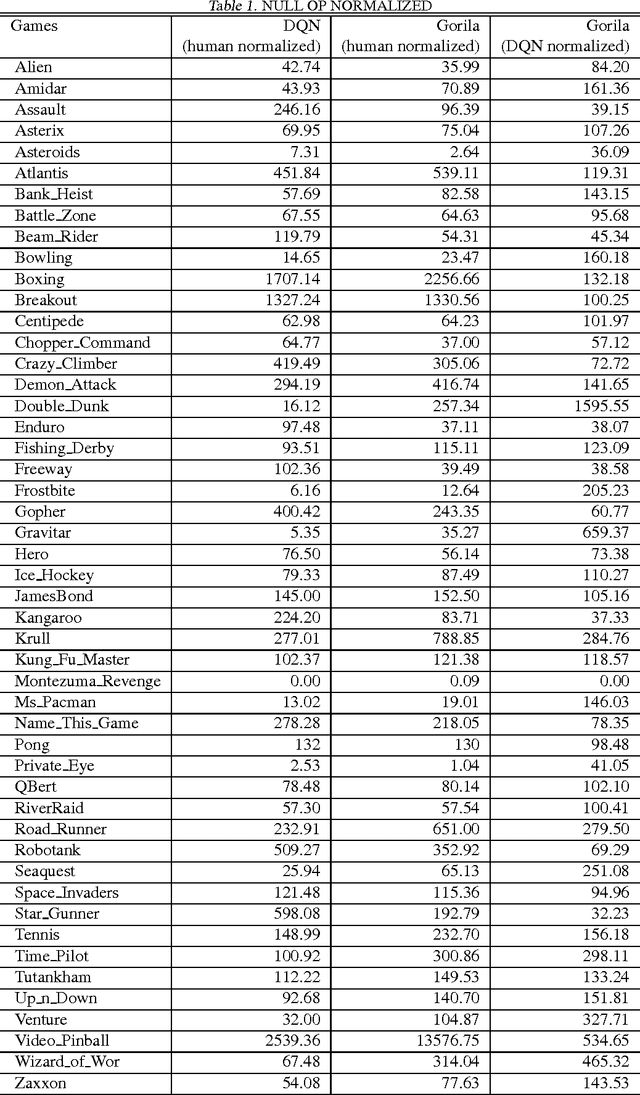
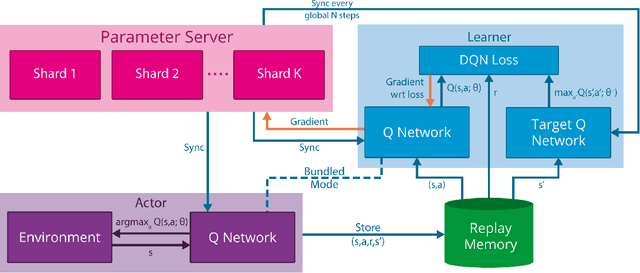
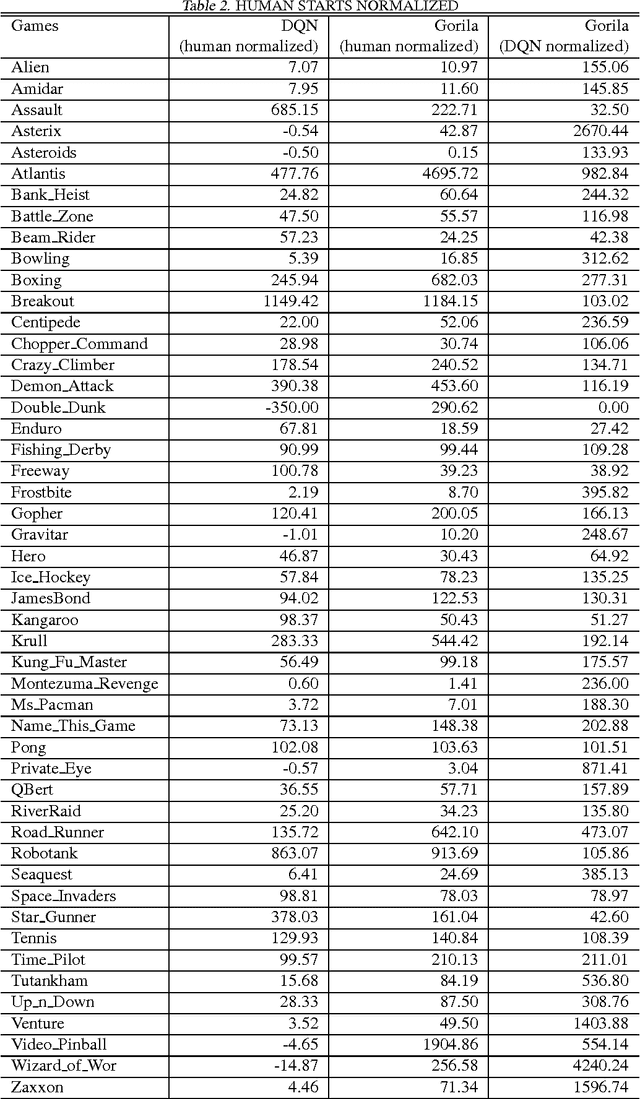
We present the first massively distributed architecture for deep reinforcement learning. This architecture uses four main components: parallel actors that generate new behaviour; parallel learners that are trained from stored experience; a distributed neural network to represent the value function or behaviour policy; and a distributed store of experience. We used our architecture to implement the Deep Q-Network algorithm (DQN). Our distributed algorithm was applied to 49 games from Atari 2600 games from the Arcade Learning Environment, using identical hyperparameters. Our performance surpassed non-distributed DQN in 41 of the 49 games and also reduced the wall-time required to achieve these results by an order of magnitude on most games.
Move Evaluation in Go Using Deep Convolutional Neural Networks
Apr 10, 2015
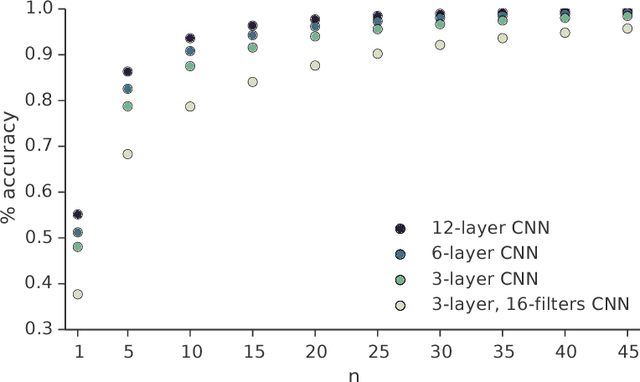
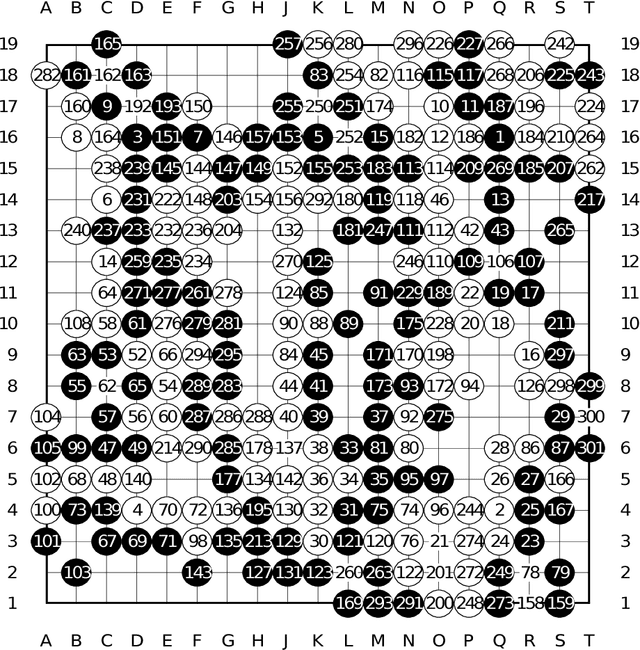
The game of Go is more challenging than other board games, due to the difficulty of constructing a position or move evaluation function. In this paper we investigate whether deep convolutional networks can be used to directly represent and learn this knowledge. We train a large 12-layer convolutional neural network by supervised learning from a database of human professional games. The network correctly predicts the expert move in 55% of positions, equalling the accuracy of a 6 dan human player. When the trained convolutional network was used directly to play games of Go, without any search, it beat the traditional search program GnuGo in 97% of games, and matched the performance of a state-of-the-art Monte-Carlo tree search that simulates a million positions per move.
Value Iteration with Options and State Aggregation
Jan 16, 2015
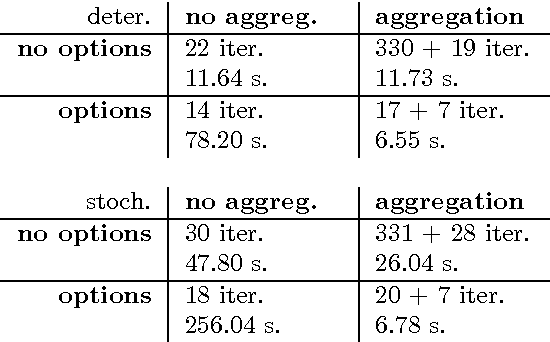
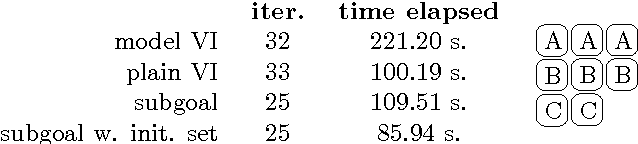
This paper presents a way of solving Markov Decision Processes that combines state abstraction and temporal abstraction. Specifically, we combine state aggregation with the options framework and demonstrate that they work well together and indeed it is only after one combines the two that the full benefit of each is realized. We introduce a hierarchical value iteration algorithm where we first coarsely solve subgoals and then use these approximate solutions to exactly solve the MDP. This algorithm solved several problems faster than vanilla value iteration.
Unit Tests for Stochastic Optimization
Feb 25, 2014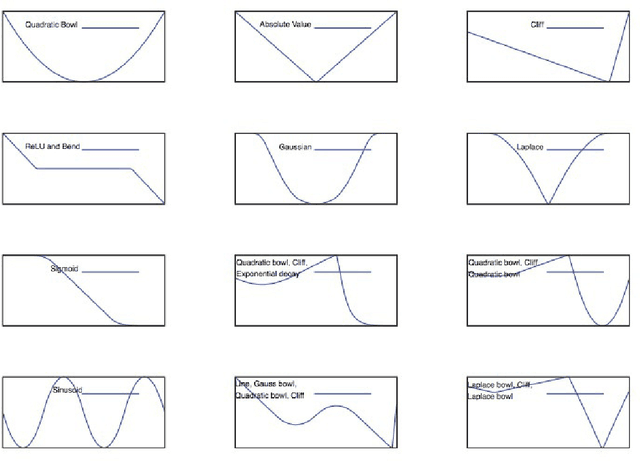
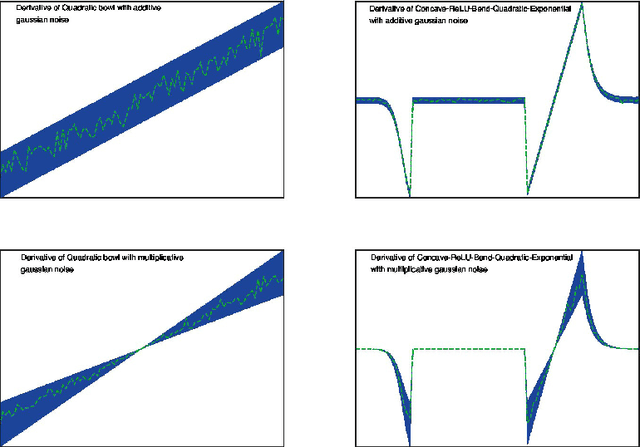
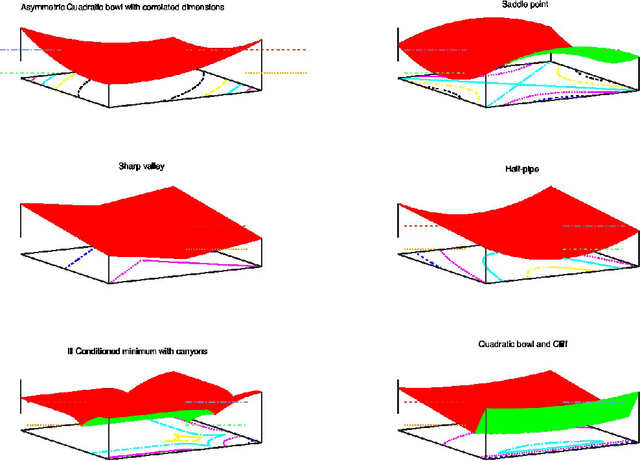

Optimization by stochastic gradient descent is an important component of many large-scale machine learning algorithms. A wide variety of such optimization algorithms have been devised; however, it is unclear whether these algorithms are robust and widely applicable across many different optimization landscapes. In this paper we develop a collection of unit tests for stochastic optimization. Each unit test rapidly evaluates an optimization algorithm on a small-scale, isolated, and well-understood difficulty, rather than in real-world scenarios where many such issues are entangled. Passing these unit tests is not sufficient, but absolutely necessary for any algorithms with claims to generality or robustness. We give initial quantitative and qualitative results on numerous established algorithms. The testing framework is open-source, extensible, and easy to apply to new algorithms.