 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Continuous Control Policies by Stochastic Value Gradients
Paper and Code
Oct 30, 2015
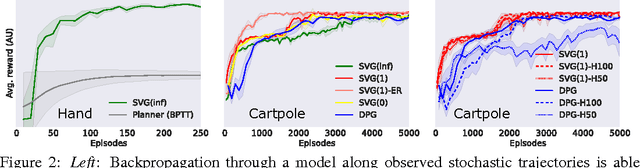
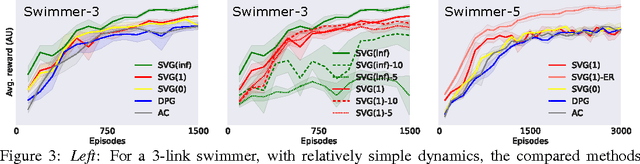
We present a unified framework for learning continuous control policies using backpropagation. It supports stochastic control by treating stochasticity in the Bellman equation as a deterministic function of exogenous noise. The product is a spectrum of general policy gradient algorithms that range from model-free methods with value functions to model-based methods without value functions. We use learned models but only require observations from the environment in- stead of observations from model-predicted trajectories, minimizing the impact of compounded model errors. We apply these algorithms first to a toy stochastic control problem and then to several physics-based control problems in simulation. One of these variants, SVG(1), shows the effectiveness of learning models, value functions, and policies simultaneously in continuous domains.