 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Curvature Activations Reduce Overfitting in Adversarial Training
Feb 15, 2021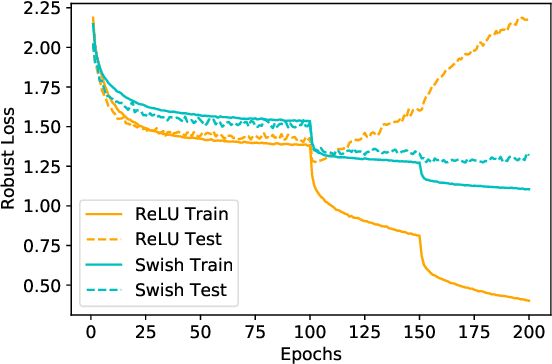

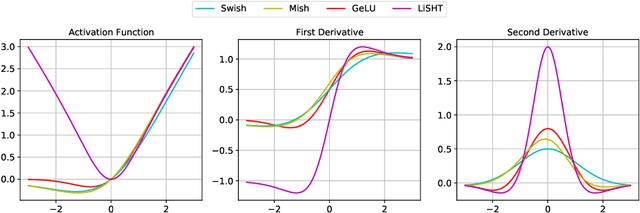
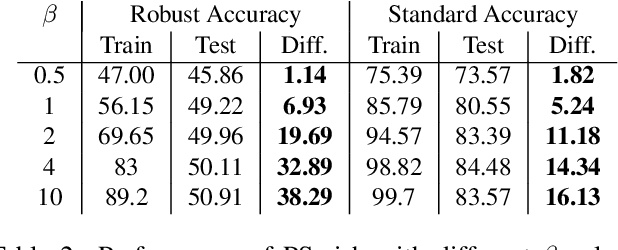
Adversarial training is one of the most effective defenses against adversarial attacks. Previous works suggest that overfitting is a dominant phenomenon in adversarial training leading to a large generalization gap between test and train accuracy in neural networks. In this work, we show that the observed generalization gap is closely related to the choice of the activation function. In particular, we show that using activation functions with low (exact or approximate) curvature values has a regularization effect that significantly reduces both the standard and robust generalization gaps in adversarial training. We observe this effect for both differentiable/smooth activations such as Swish as well as non-differentiable/non-smooth activations such as LeakyReLU. In the latter case, the approximate curvature of the activation is low. Finally, we show that for activation functions with low curvature, the double descent phenomenon for adversarially trained models does not occur.
Learning Visual Representations for Transfer Learning by Suppressing Texture
Nov 04, 2020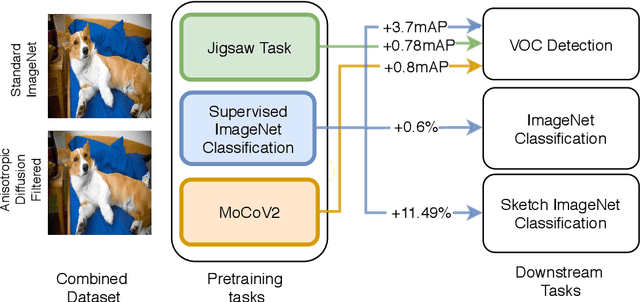
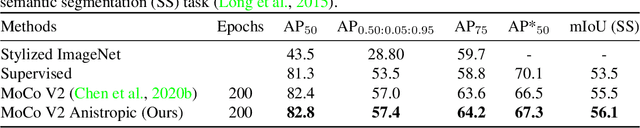

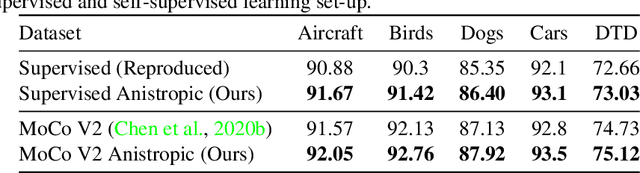
Recent literature has shown that features obtained from supervised training of CNNs may over-emphasize texture rather than encoding high-level information. In self-supervised learning in particular, texture as a low-level cue may provide shortcuts that prevent the network from learning higher level representations. To address these problems we propose to use classic methods based on anisotropic diffusion to augment training using images with suppressed texture. This simple method helps retain important edge information and suppress texture at the same time. We empirically show that our method achieves state-of-the-art results on object detection and image classification with eight diverse datasets in either supervised or self-supervised learning tasks such as MoCoV2 and Jigsaw. Our method is particularly effective for transfer learning tasks and we observed improved performance on five standard transfer learning datasets. The large improvements (up to 11.49\%) on the Sketch-ImageNet dataset, DTD dataset and additional visual analyses with saliency maps suggest that our approach helps in learning better representations that better transfer.
On the Similarity between the Laplace and Neural Tangent Kernels
Jul 03, 2020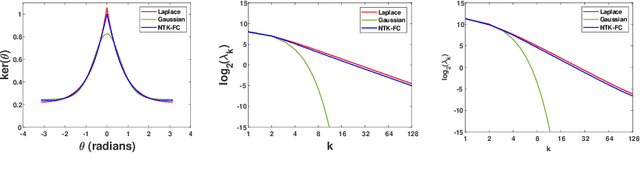
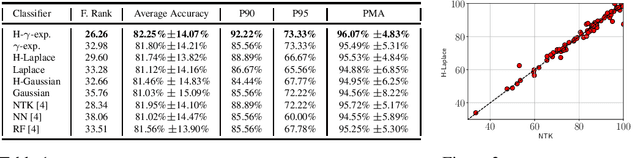
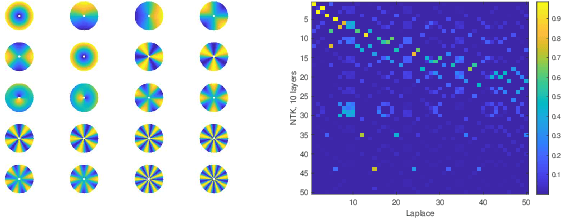
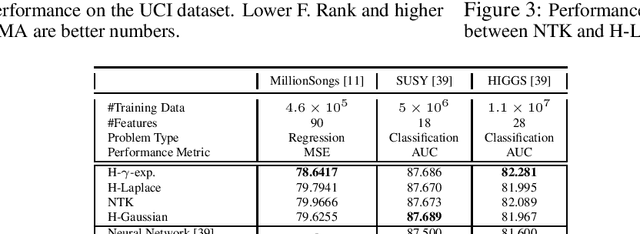
Recent theoretical work has shown that massively overparameterized neural networks are equivalent to kernel regressors that use Neural Tangent Kernels(NTK). Experiments show that these kernel methods perform similarly to real neural networks. Here we show that NTK for fully connected networks is closely related to the standard Laplace kernel. We show theoretically that for normalized data on the hypersphere both kernels have the same eigenfunctions and their eigenvalues decay polynomially at the same rate, implying that their Reproducing Kernel Hilbert Spaces (RKHS) include the same sets of functions. This means that both kernels give rise to classes of functions with the same smoothness properties. The two kernels differ for data off the hypersphere, but experiments indicate that when data is properly normalized these differences are not significant. Finally, we provide experiments on real data comparing NTK and the Laplace kernel, along with a larger class of{\gamma}-exponential kernels. We show that these perform almost identically. Our results suggest that much insight about neural networks can be obtained from analysis of the well-known Laplace kernel, which has a simple closed-form.
SharinGAN: Combining Synthetic and Real Data for Unsupervised Geometry Estimation
Jun 07, 2020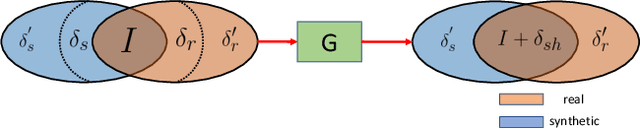
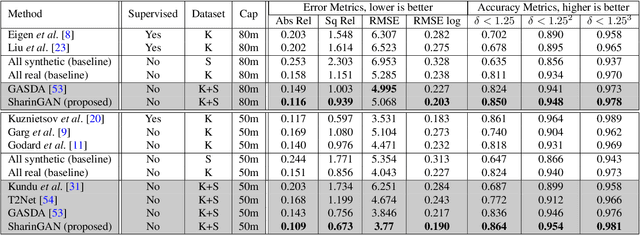
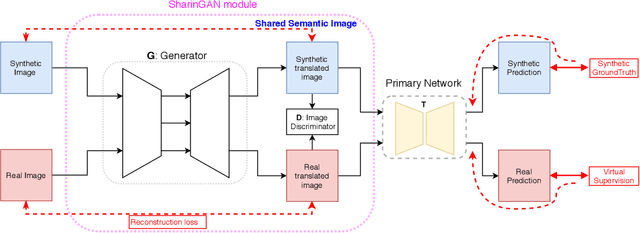
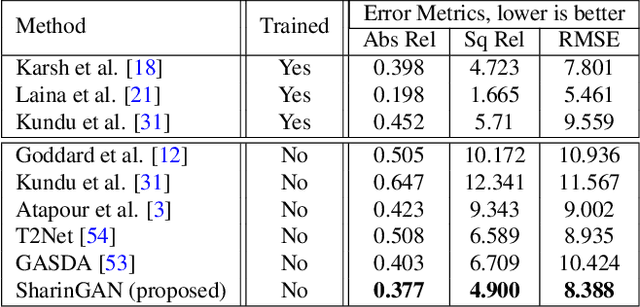
We propose a novel method for combining synthetic and real images when training networks to determine geometric information from a single image. We suggest a method for mapping both image types into a single, shared domain. This is connected to a primary network for end-to-end training. Ideally, this results in images from two domains that present shared information to the primary network. Our experiments demonstrate significant improvements over the state-of-the-art in two important domains, surface normal estimation of human faces and monocular depth estimation for outdoor scenes, both in an unsupervised setting.
Towards Automatic Generation of Questions from Long Answers
Apr 15, 2020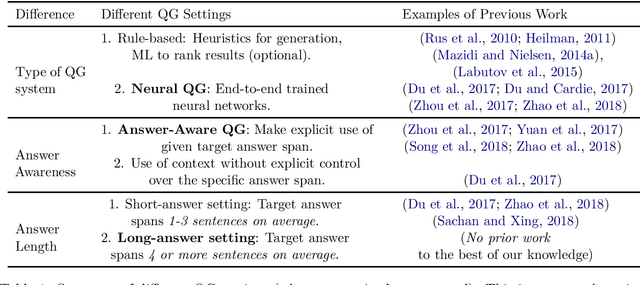

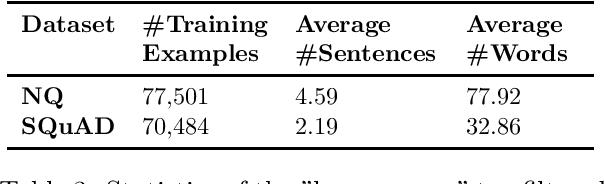
Automatic question generation (AQG) has broad applicability in domains such as tutoring systems, conversational agents, healthcare literacy, and information retrieval. Existing efforts at AQG have been limited to short answer lengths of up to two or three sentences. However, several real-world applications require question generation from answers that span several sentences. Therefore, we propose a novel evaluation benchmark to assess the performance of existing AQG systems for long-text answers. We leverage the large-scale open-source Google Natural Questions dataset to create the aforementioned long-answer AQG benchmark. We empirically demonstrate that the performance of existing AQG methods significantly degrades as the length of the answer increases. Transformer-based methods outperform other existing AQG methods on long answers in terms of automatic as well as human evaluation. However, we still observe degradation in the performance of our best performing models with increasing sentence length, suggesting that long answer QA is a challenging benchmark task for future research.
Frequency Bias in Neural Networks for Input of Non-Uniform Density
Mar 10, 2020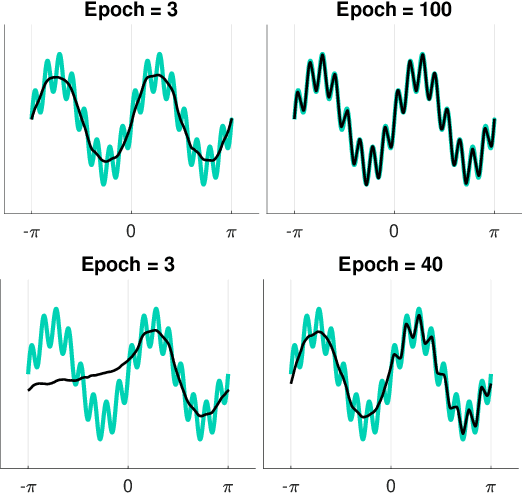
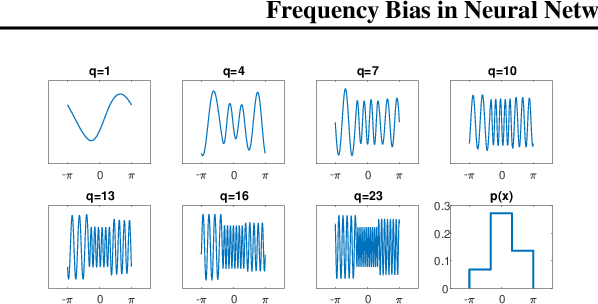
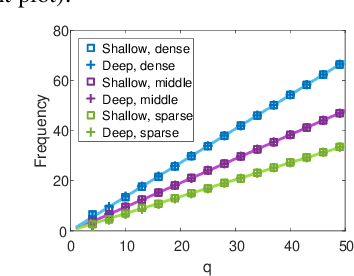
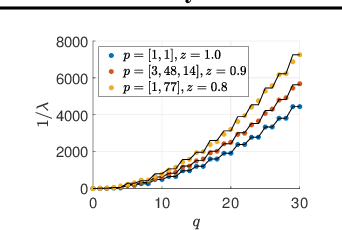
Recent works have partly attributed the generalization ability of over-parameterized neural networks to frequency bias -- networks trained with gradient descent on data drawn from a uniform distribution find a low frequency fit before high frequency ones. As realistic training sets are not drawn from a uniform distribution, we here use the Neural Tangent Kernel (NTK) model to explore the effect of variable density on training dynamics. Our results, which combine analytic and empirical observations, show that when learning a pure harmonic function of frequency $\kappa$, convergence at a point $\x \in \Sphere^{d-1}$ occurs in time $O(\kappa^d/p(\x))$ where $p(\x)$ denotes the local density at $\x$. Specifically, for data in $\Sphere^1$ we analytically derive the eigenfunctions of the kernel associated with the NTK for two-layer networks. We further prove convergence results for deep, fully connected networks with respect to the spectral decomposition of the NTK. Our empirical study highlights similarities and differences between deep and shallow networks in this model.
The Convergence Rate of Neural Networks for Learned Functions of Different Frequencies
Jun 02, 2019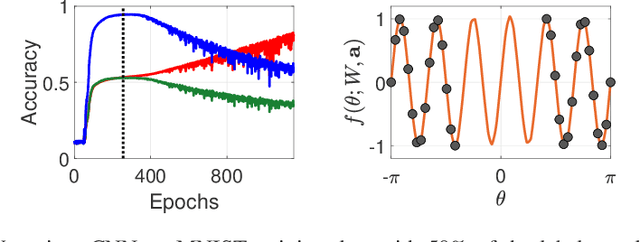
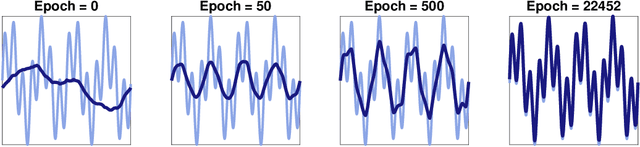
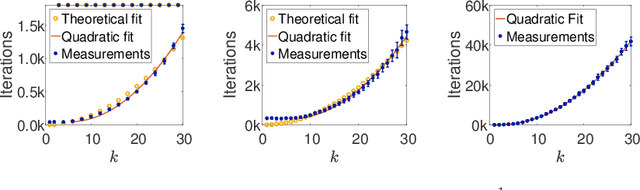
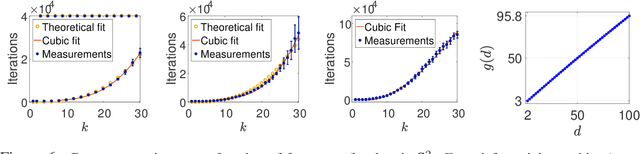
We study the relationship between the speed at which a neural network learns a function and the frequency of the function. We build on recent results that show that the dynamics of overparameterized neural networks trained with gradient descent can be well approximated by a linear system. When normalized training data is uniformly distributed on a hypersphere, the eigenfunctions of this linear system are spherical harmonic functions. We derive the corresponding eigenvalues for each frequency after introducing a bias term in the model. This bias term had been omitted from the linear network model without significantly affecting previous theoretical results. However, we show theoretically and experimentally that a shallow neural network without bias cannot learn simple, low frequency functions with odd frequencies, in the limit of large amounts of data. Our results enable us to make specific predictions of the time it will take a network with bias to learn functions of varying frequency. These predictions match the behavior of real shallow and deep networks.
Adversarially robust transfer learning
May 20, 2019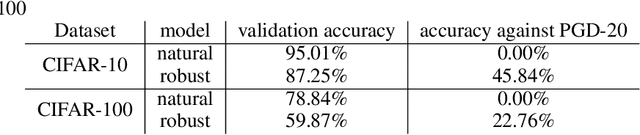
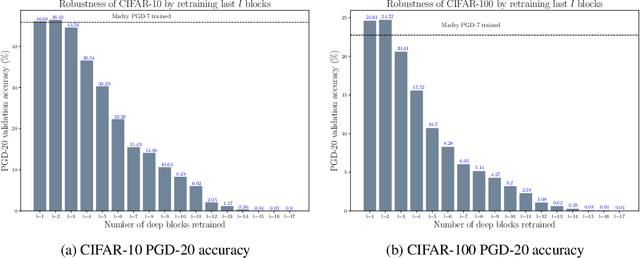
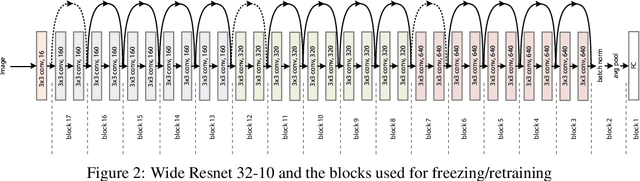
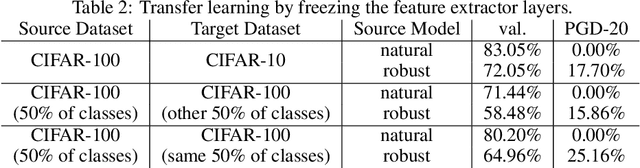
Transfer learning, in which a network is trained on one task and re-purposed on another, is often used to produce neural network classifiers when data is scarce or full-scale training is too costly. When the goal is to produce a model that is not only accurate but also adversarially robust, data scarcity and computational limitations become even more cumbersome. We consider robust transfer learning, in which we transfer not only performance but also robustness from a source model to a target domain. We start by observing that robust networks contain robust feature extractors. By training classifiers on top of these feature extractors, we produce new models that inherit the robustness of their parent networks. We then consider the case of fine-tuning a network by re-training end-to-end in the target domain. When using lifelong learning strategies, this process preserves the robustness of the source network while achieving high accuracy. By using such strategies, it is possible to produce accurate and robust models with little data, and without the cost of adversarial training.
Understanding the (un)interpretability of natural image distributions using generative models
Jan 06, 2019


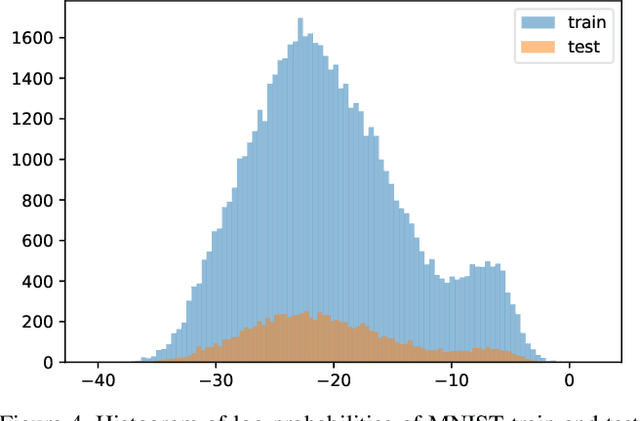
Probability density estimation is a classical and well studied problem, but standard density estimation methods have historically lacked the power to model complex and high-dimensional image distributions. More recent generative models leverage the power of neural networks to implicitly learn and represent probability models over complex images. We describe methods to extract explicit probability density estimates from GANs, and explore the properties of these image density functions. We perform sanity check experiments to provide evidence that these probabilities are reasonable. However, we also show that density functions of natural images are difficult to interpret and thus limited in use. We study reasons for this lack of interpretability, and show that we can get interpretability back by doing density estimation on latent representations of images.
SfSNet: Learning Shape, Reflectance and Illuminance of Faces in the Wild
Apr 19, 2018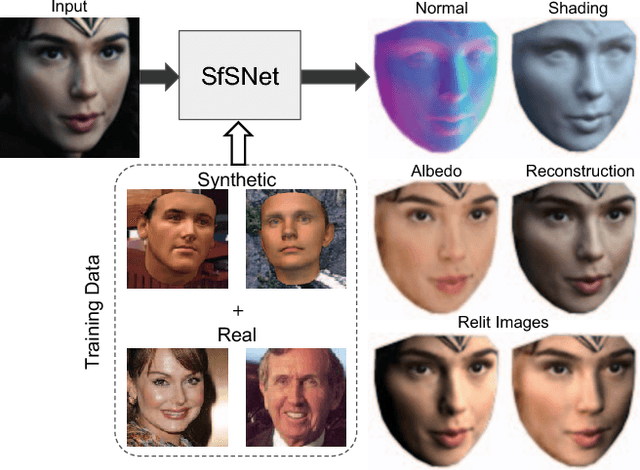
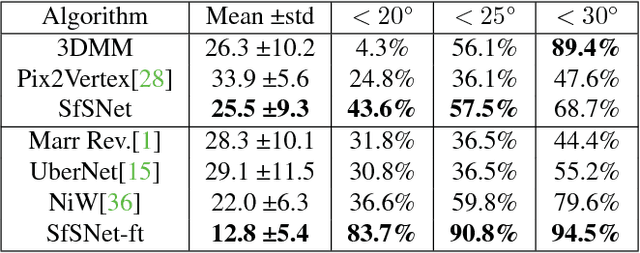
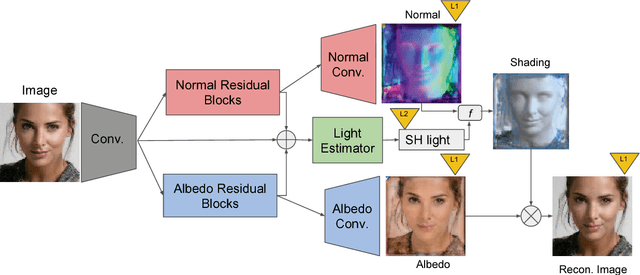
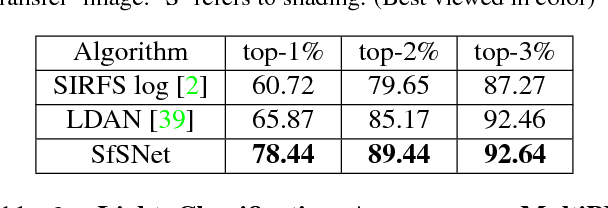
We present SfSNet, an end-to-end learning framework for producing an accurate decomposition of an unconstrained human face image into shape, reflectance and illuminance. SfSNet is designed to reflect a physical lambertian rendering model. SfSNet learns from a mixture of labeled synthetic and unlabeled real world images. This allows the network to capture low frequency variations from synthetic and high frequency details from real images through the photometric reconstruction loss. SfSNet consists of a new decomposition architecture with residual blocks that learns a complete separation of albedo and normal. This is used along with the original image to predict lighting. SfSNet produces significantly better quantitative and qualitative results than state-of-the-art methods for inverse rendering and independent normal and illumination estimation.