 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Variational Model-Based Reinforcement Learning for Complex Observations
Aug 06, 2020
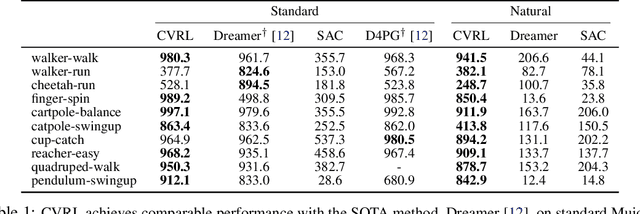
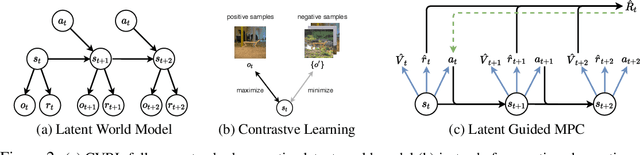
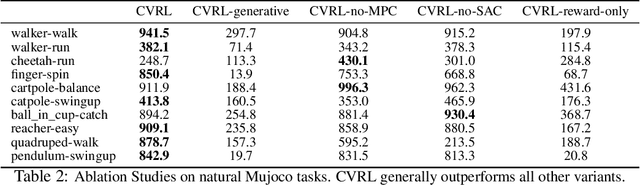
Deep model-based reinforcement learning (MBRL) has achieved great sample-efficiency and generalization in decision making for sophisticated simulated tasks, such as Atari games. However, real-world robot decision making requires reasoning with complex natural visual observations. This paper presents Contrastive Variational Reinforcement Learning (CVRL), an MBRL framework for complex natural observations. In contrast to the commonly used generative world models, CVRL learns a contrastive variational world model by maximizing the mutual information between latent states and observations discriminatively by contrastive learning. Contrastive learning avoids modeling the complex observation space and is significantly more robust than the standard generative world models. For decision making, CVRL discovers long-horizon behavior by online search guided by an actor-critic. CVRL achieves comparable performance with the state-of-the-art (SOTA) generative MBRL approaches on a series of Mujoco tasks, and significantly outperforms SOTAs on Natural Mujoco tasks, a new, more challenging continuous control RL benchmark with complex observations introduced in this paper.
DinerDash Gym: A Benchmark for Policy Learning in High-Dimensional Action Space
Jul 13, 2020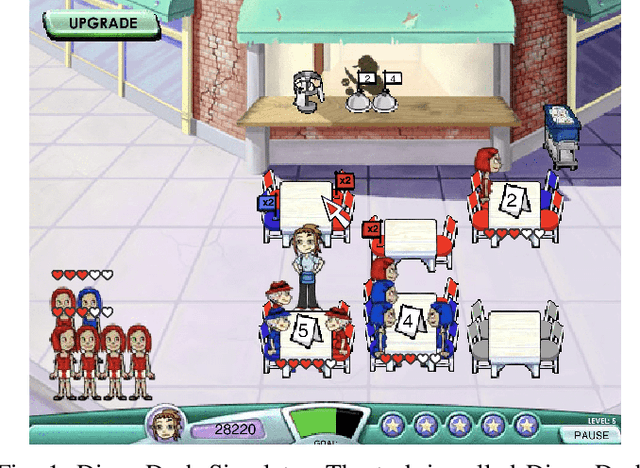
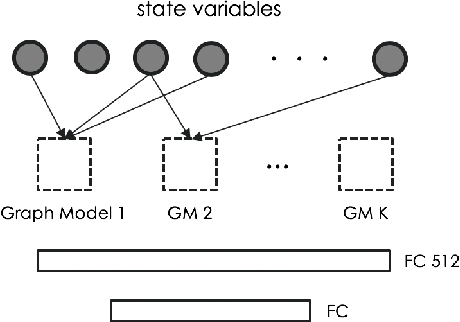
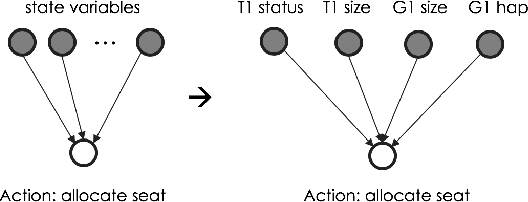
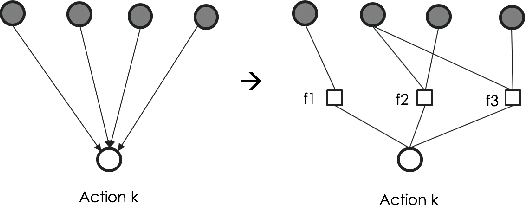
It has been arduous to assess the progress of a policy learning algorithm in the domain of hierarchical task with high dimensional action space due to the lack of a commonly accepted benchmark. In this work, we propose a new light-weight benchmark task called Diner Dash for evaluating the performance in a complicated task with high dimensional action space. In contrast to the traditional Atari games that only have a flat structure of goals and very few actions, the proposed benchmark task has a hierarchical task structure and size of 57 for the action space and hence can facilitate the development of policy learning in complicated tasks. On top of that, we introduce Decomposed Policy Graph Modelling (DPGM), an algorithm that combines both graph modelling and deep learning to allow explicit domain knowledge embedding and achieves significant improvement comparing to the baseline. In the experiments, we have shown the effectiveness of the domain knowledge injection via a specially designed imitation algorithm as well as results of other popular algorithms.
Discriminative Particle Filter Reinforcement Learning for Complex Partial Observations
Feb 23, 2020
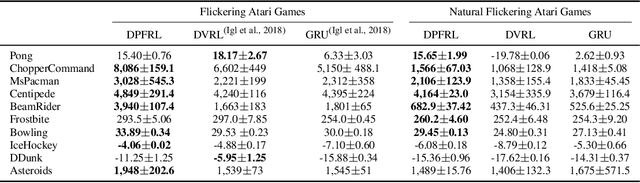
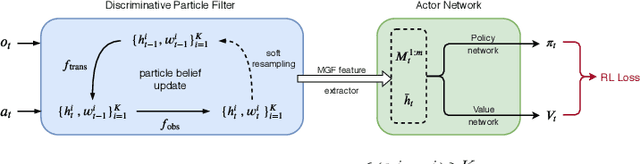

Deep reinforcement learning is successful in decision making for sophisticated games, such as Atari, Go, etc. However, real-world decision making often requires reasoning with partial information extracted from complex visual observations. This paper presents Discriminative Particle Filter Reinforcement Learning (DPFRL), a new reinforcement learning framework for complex partial observations. DPFRL encodes a differentiable particle filter in the neural network policy for explicit reasoning with partial observations over time. The particle filter maintains a belief using learned discriminative update, which is trained end-to-end for decision making. We show that using the discriminative update instead of standard generative models results in significantly improved performance, especially for tasks with complex visual observations, because they circumvent the difficulty of modeling complex observations that are irrelevant to decision making. In addition, to extract features from the particle belief, we propose a new type of belief feature based on the moment generating function. DPFRL outperforms state-of-the-art POMDP RL models in Flickering Atari Games, an existing POMDP RL benchmark, and in Natural Flickering Atari Games, a new, more challenging POMDP RL benchmark introduced in this paper. Further, DPFRL performs well for visual navigation with real-world data in the Habitat environment.
SUMMIT: A Simulator for Urban Driving in Massive Mixed Traffic
Nov 11, 2019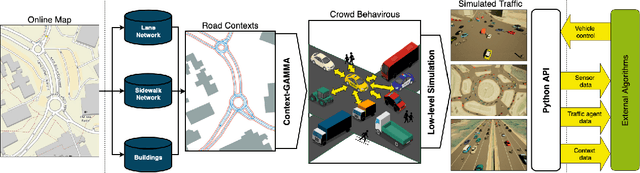
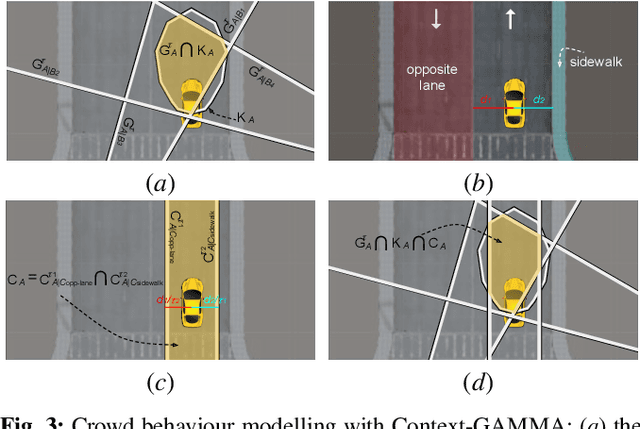
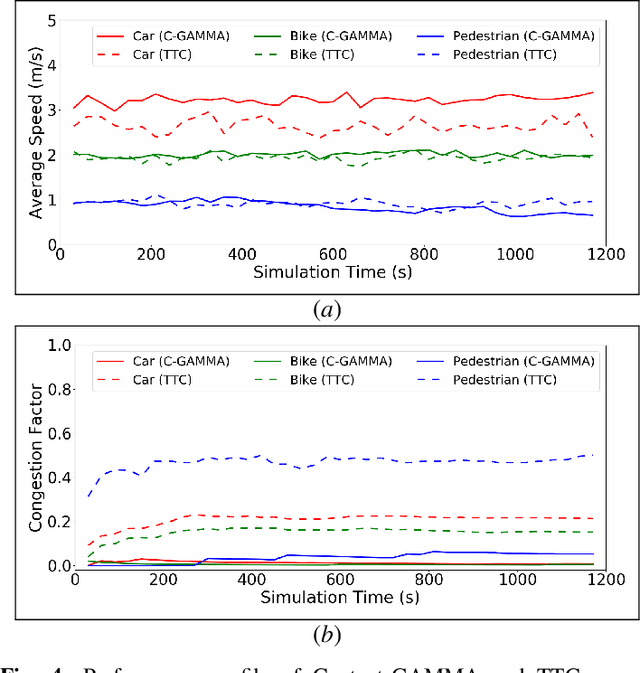

Autonomous driving in an unregulated urban crowd is an outstanding challenge, especially, in the presence of many aggressive, high-speed traffic participants. This paper presents SUMMIT, a high-fidelity simulator that facilitates the development and testing of crowd-driving algorithms. By leveraging the open-source OpenStreetMap map database and a heterogeneous multi-agent motion prediction model developed in our earlier work, SUMMIT simulates dense, unregulated urban traffic for heterogeneous agents at any worldwide locations that OpenStreetMap supports. SUMMIT is built as an extension of CARLA and inherits from it the physical and visual realism for autonomous driving simulation. SUMMIT supports a wide range of applications, including perception, vehicle control, planning, and end-to-end learning. We provide a context-aware planner together with benchmark scenarios and show that SUMMIT generates complex, realistic traffic behaviors in challenging crowd-driving settings.
Robot Capability and Intention in Trust-based Decisions across Tasks
Sep 03, 2019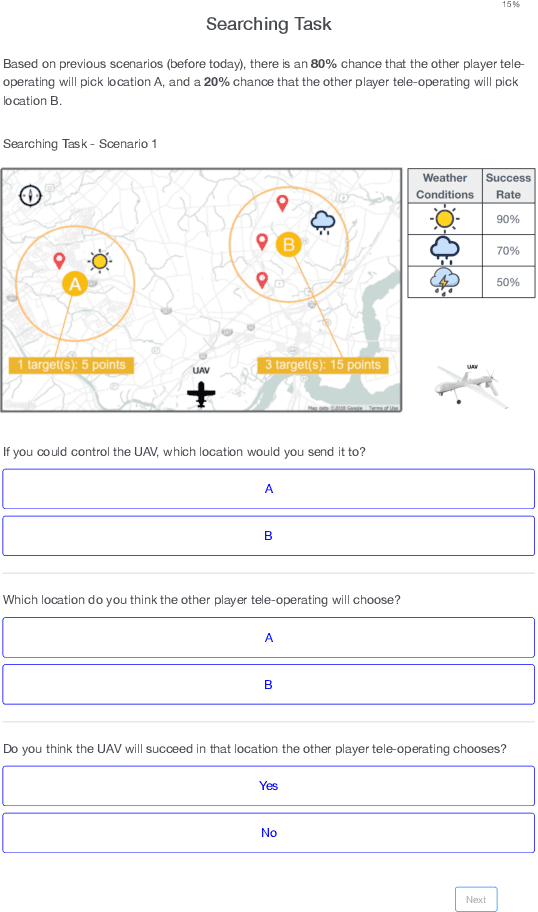

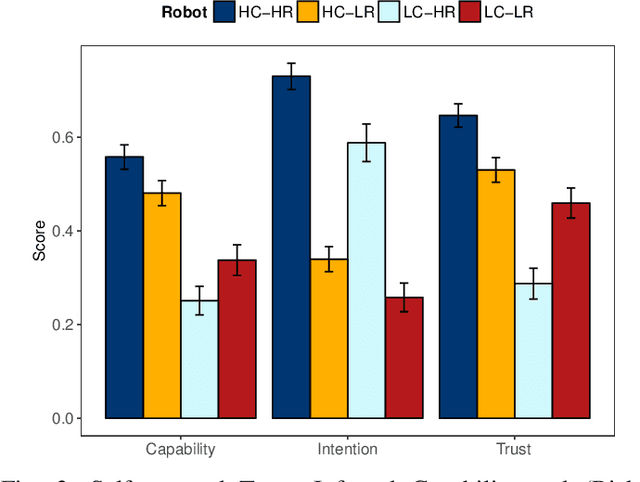
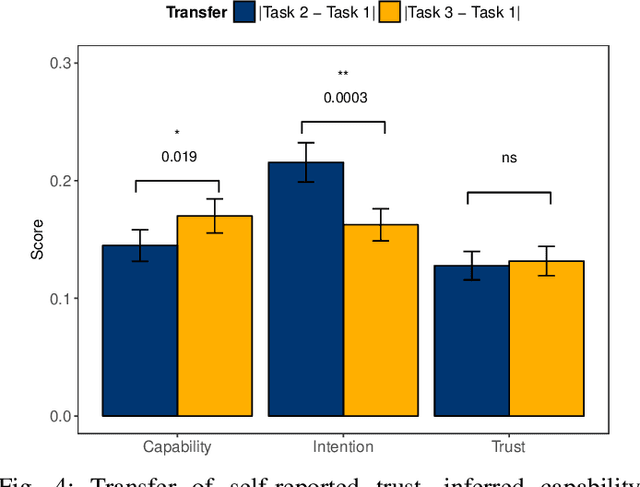
In this paper, we present results from a human-subject study designed to explore two facets of human mental models of robots---inferred capability and intention---and their relationship to overall trust and eventual decisions. In particular, we examine delegation situations characterized by uncertainty, and explore how inferred capability and intention are applied across different tasks. We develop an online survey where human participants decide whether to delegate control to a simulated UAV agent. Our study shows that human estimations of robot capability and intent correlate strongly with overall self-reported trust. However, overall trust is not independently sufficient to determine whether a human will decide to trust (delegate) a given task to a robot. Instead, our study reveals that estimations of robot intention, capability, and overall trust are integrated when deciding to delegate. From a broader perspective, these results suggest that calibrating overall trust alone is insufficient; to make correct decisions, humans need (and use) multi-faceted mental models when collaborating with robots across multiple contexts.
Particle Filter Recurrent Neural Networks
May 30, 2019
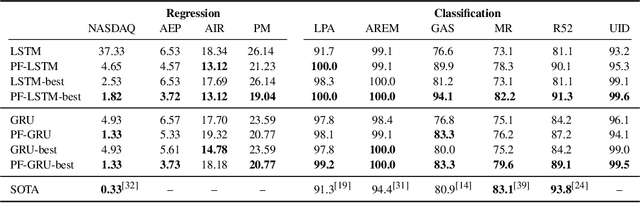
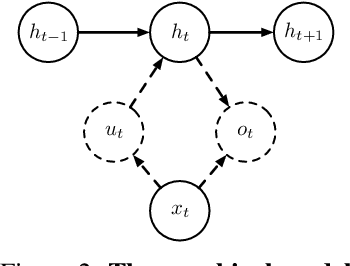

Recurrent neural networks (RNNs) have been extraordinarily successful for prediction with sequential data. To tackle highly variable and noisy real-world data, we introduce Particle Filter Recurrent Neural Networks (PF-RNNs), a new RNN family that explicitly models uncertainty in its internal structure: while an RNN relies on a long, deterministic latent state vector, a PF-RNN maintains a latent state distribution, approximated as a set of particles. For effective learning, we provide a fully differentiable particle filter algorithm that updates the PF-RNN latent state distribution according to the Bayes rule. Experiments demonstrate that the proposed PF-RNNs outperform the corresponding standard gated RNNs on a synthetic robot localization dataset and 10 real-world sequence prediction datasets for text classification, stock price prediction, etc.
LeTS-Drive: Driving in a Crowd by Learning from Tree Search
May 29, 2019
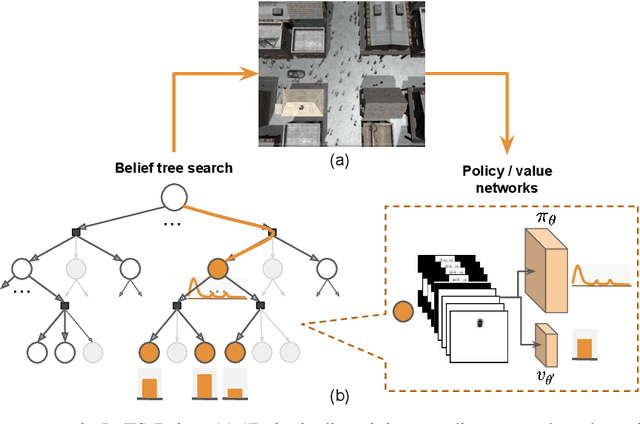

Autonomous driving in a crowded environment, e.g., a busy traffic intersection, is an unsolved challenge for robotics. The robot vehicle must contend with a dynamic and partially observable environment, noisy sensors, and many agents. A principled approach is to formalize it as a Partially Observable Markov Decision Process (POMDP) and solve it through online belief-tree search. To handle a large crowd and achieve real-time performance in this very challenging setting, we propose LeTS-Drive, which integrates online POMDP planning and deep learning. It consists of two phases. In the offline phase, we learn a policy and the corresponding value function by imitating the belief tree search. In the online phase, the learned policy and value function guide the belief tree search. LeTS-Drive leverages the robustness of planning and the runtime efficiency of learning to enhance the performance of both. Experimental results in simulation show that LeTS-Drive outperforms either planning or imitation learning alone and develops sophisticated driving skills.
Differentiable Algorithm Networks for Composable Robot Learning
May 28, 2019

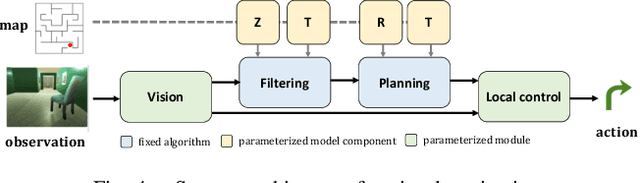
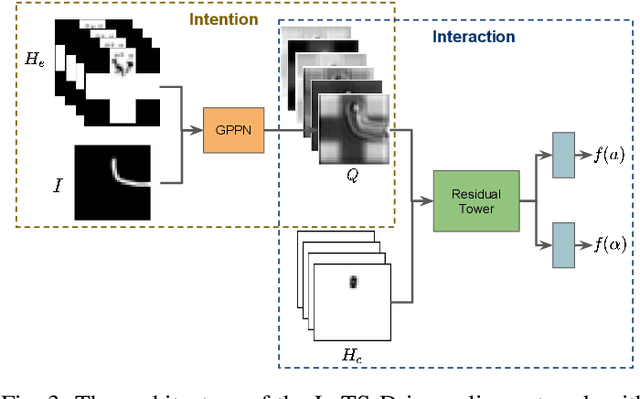
This paper introduces the Differentiable Algorithm Network (DAN), a composable architecture for robot learning systems. A DAN is composed of neural network modules, each encoding a differentiable robot algorithm and an associated model; and it is trained end-to-end from data. DAN combines the strengths of model-driven modular system design and data-driven end-to-end learning. The algorithms and models act as structural assumptions to reduce the data requirements for learning; end-to-end learning allows the modules to adapt to one another and compensate for imperfect models and algorithms, in order to achieve the best overall system performance. We illustrate the DAN methodology through a case study on a simulated robot system, which learns to navigate in complex 3-D environments with only local visual observations and an image of a partially correct 2-D floor map.
Factored Contextual Policy Search with Bayesian Optimization
Apr 26, 2019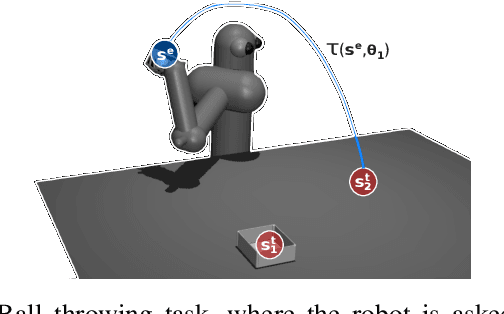
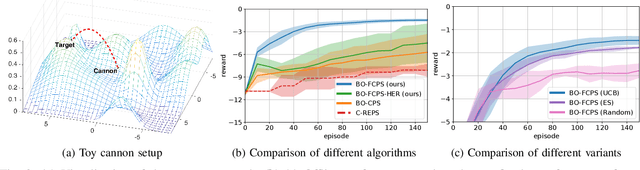
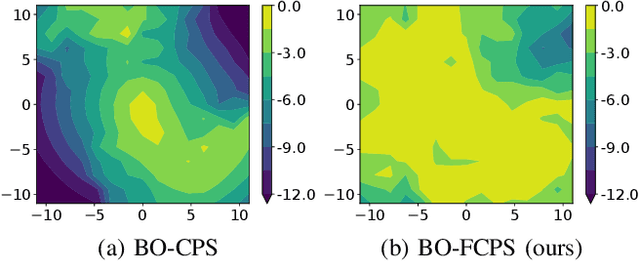
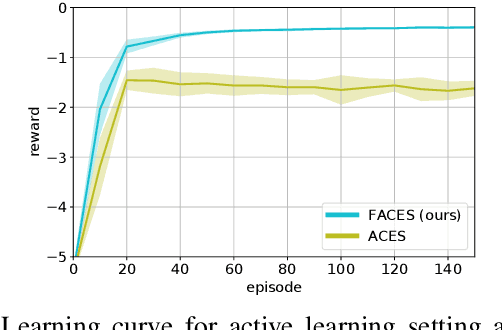
Scarce data is a major challenge to scaling robot learning to truly complex tasks, as we need to generalize locally learned policies over different task contexts. Contextual policy search offers data-efficient learning and generalization by explicitly conditioning the policy on a parametric context space. In this paper, we further structure the contextual policy representation. We propose to factor contexts into two components: target contexts that describe the task objectives, e.g. target position for throwing a ball; and environment contexts that characterize the environment, e.g. initial position or mass of the ball. Our key observation is that experience can be directly generalized over target contexts. We show that this can be easily exploited in contextual policy search algorithms. In particular, we apply factorization to a Bayesian optimization approach to contextual policy search both in sampling-based and active learning settings. Our simulation results show faster learning and better generalization in various robotic domains. See our supplementary video: https://youtu.be/MNTbBAOufDY.
Guided Exploration of Human Intentions for Human-Robot Interaction
Jan 19, 2019
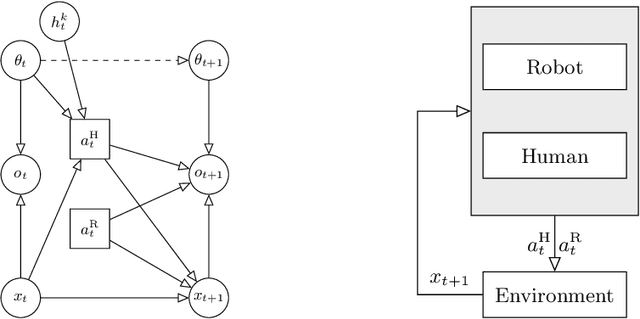
Robot understanding of human intentions is essential for fluid human-robot interaction. Intentions, however, cannot be directly observed and must be inferred from behaviors. We learn a model of adaptive human behavior conditioned on the intention as a latent variable. We then embed the human behavior model into a principled probabilistic decision model, which enables the robot to (i) explore actively in order to infer human intentions and (ii) choose actions that maximize its performance. Furthermore, the robot learns from the demonstrated actions of human experts to further improve exploration. Preliminary experiments in simulation indicate that our approach, when applied to autonomous driving, improves the efficiency and safety of driving in common interactive driving scenarios.