 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy is Winoground Hard? Investigating Failures in Visuolinguistic Compositionality
Nov 11, 2022



Recent visuolinguistic pre-trained models show promising progress on various end tasks such as image retrieval and video captioning. Yet, they fail miserably on the recently proposed Winoground dataset, which challenges models to match paired images and English captions, with items constructed to overlap lexically but differ in meaning (e.g., "there is a mug in some grass" vs. "there is some grass in a mug"). By annotating the dataset using new fine-grained tags, we show that solving the Winoground task requires not just compositional language understanding, but a host of other abilities like commonsense reasoning or locating small, out-of-focus objects in low-resolution images. In this paper, we identify the dataset's main challenges through a suite of experiments on related tasks (probing task, image retrieval task), data augmentation, and manual inspection of the dataset. Our analysis suggests that a main challenge in visuolinguistic models may lie in fusing visual and textual representations, rather than in compositional language understanding. We release our annotation and code at https://github.com/ajd12342/why-winoground-hard .
Phoneme Segmentation Using Self-Supervised Speech Models
Nov 02, 2022



We apply transfer learning to the task of phoneme segmentation and demonstrate the utility of representations learned in self-supervised pre-training for the task. Our model extends transformer-style encoders with strategically placed convolutions that manipulate features learned in pre-training. Using the TIMIT and Buckeye corpora we train and test the model in the supervised and unsupervised settings. The latter case is accomplished by furnishing a noisy label-set with the predictions of a separate model, it having been trained in an unsupervised fashion. Results indicate our model eclipses previous state-of-the-art performance in both settings and on both datasets. Finally, following observations during published code review and attempts to reproduce past segmentation results, we find a need to disambiguate the definition and implementation of widely-used evaluation metrics. We resolve this ambiguity by delineating two distinct evaluation schemes and describing their nuances.
M-SpeechCLIP: Leveraging Large-Scale, Pre-Trained Models for Multilingual Speech to Image Retrieval
Nov 02, 2022



This work investigates the use of large-scale, pre-trained models (CLIP and HuBERT) for multilingual speech-image retrieval. For non-English speech-image retrieval, we outperform the current state-of-the-art performance by a wide margin when training separate models for each language, and show that a single model which processes speech in all three languages still achieves retrieval scores comparable with the prior state-of-the-art. We identify key differences in model behavior and performance between English and non-English settings, presumably attributable to the English-only pre-training of CLIP and HuBERT. Finally, we show that our models can be used for mono- and cross-lingual speech-text retrieval and cross-lingual speech-speech retrieval, despite never having seen any parallel speech-text or speech-speech data during training.
C2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Oct 07, 2022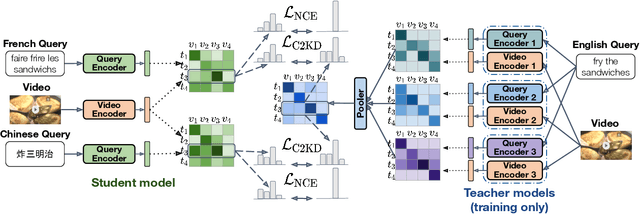
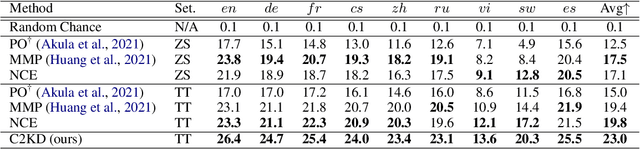

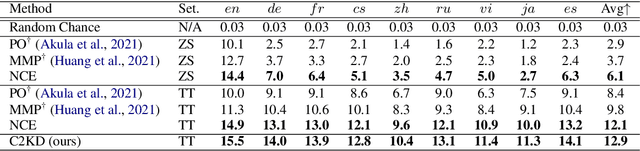
Multilingual text-video retrieval methods have improved significantly in recent years, but the performance for other languages lags behind English. We propose a Cross-Lingual Cross-Modal Knowledge Distillation method to improve multilingual text-video retrieval. Inspired by the fact that English text-video retrieval outperforms other languages, we train a student model using input text in different languages to match the cross-modal predictions from teacher models using input text in English. We propose a cross entropy based objective which forces the distribution over the student's text-video similarity scores to be similar to those of the teacher models. We introduce a new multilingual video dataset, Multi-YouCook2, by translating the English captions in the YouCook2 video dataset to 8 other languages. Our method improves multilingual text-video retrieval performance on Multi-YouCook2 and several other datasets such as Multi-MSRVTT and VATEX. We also conducted an analysis on the effectiveness of different multilingual text models as teachers.
SpeechCLIP: Integrating Speech with Pre-Trained Vision and Language Model
Oct 03, 2022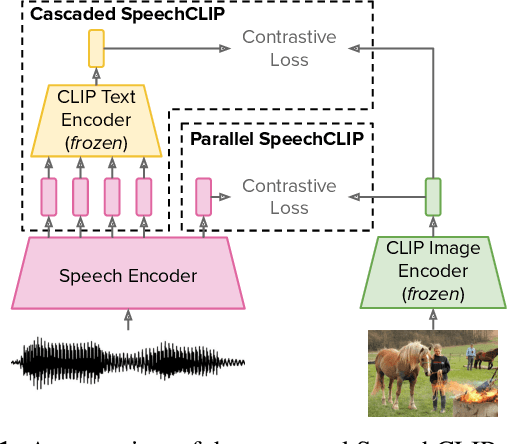

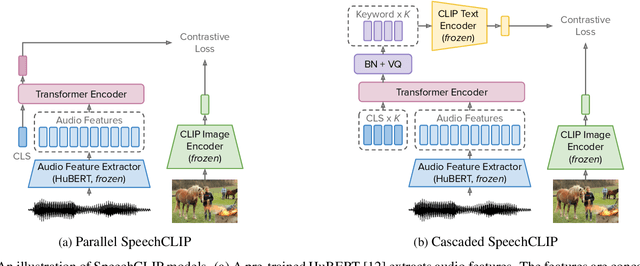
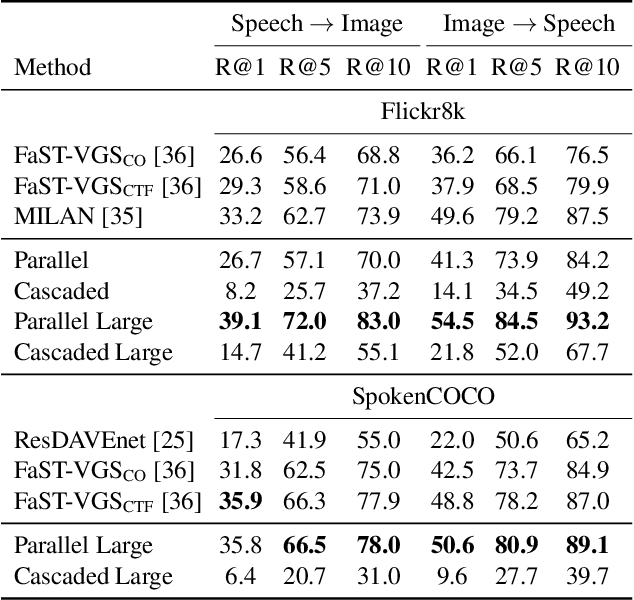
Data-driven speech processing models usually perform well with a large amount of text supervision, but collecting transcribed speech data is costly. Therefore, we propose SpeechCLIP, a novel framework bridging speech and text through images to enhance speech models without transcriptions. We leverage state-of-the-art pre-trained HuBERT and CLIP, aligning them via paired images and spoken captions with minimal fine-tuning. SpeechCLIP outperforms prior state-of-the-art on image-speech retrieval and performs zero-shot speech-text retrieval without direct supervision from transcriptions. Moreover, SpeechCLIP can directly retrieve semantically related keywords from speech.
MAE-AST: Masked Autoencoding Audio Spectrogram Transformer
Mar 30, 2022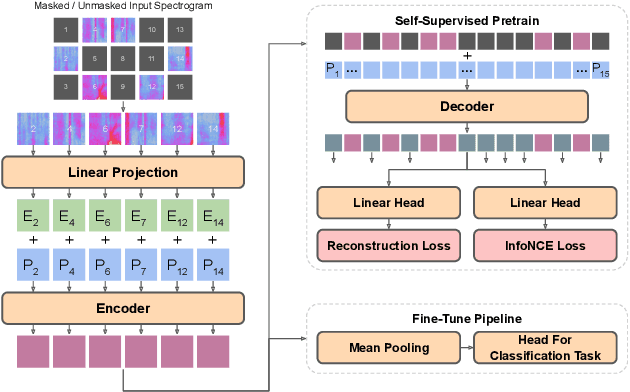
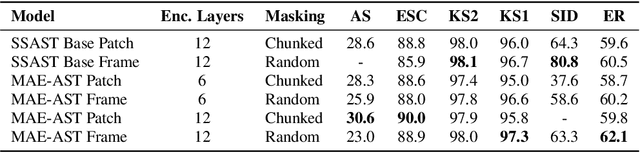
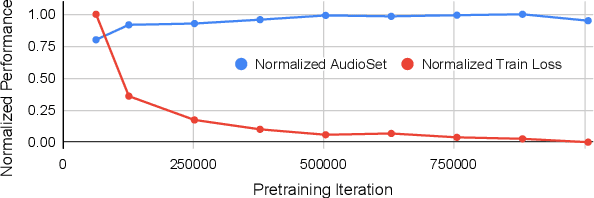
In this paper, we propose a simple yet powerful improvement over the recent Self-Supervised Audio Spectrogram Transformer (SSAST) model for speech and audio classification. Specifically, we leverage the insight that the SSAST uses a very high masking ratio (75%) during pretraining, meaning that the vast majority of self-attention compute is performed on mask tokens. We address this by integrating the encoder-decoder architecture from Masked Autoencoders are Scalable Vision Learners (MAE) into the SSAST, where a deep encoder operates on only unmasked input, and a shallow decoder operates on encoder outputs and mask tokens. We find that MAE-like pretraining can provide a 3x speedup and 2x memory usage reduction over the vanilla SSAST using current audio pretraining strategies with ordinary model and input sizes. When fine-tuning on downstream tasks, which only uses the encoder, we find that our approach outperforms the SSAST on a variety of downstream tasks. We further conduct comprehensive evaluations into different strategies of pretraining and explore differences in MAE-style pretraining between the visual and audio domains.
Word Discovery in Visually Grounded, Self-Supervised Speech Models
Mar 28, 2022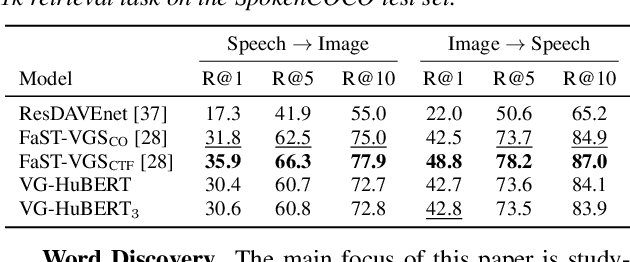

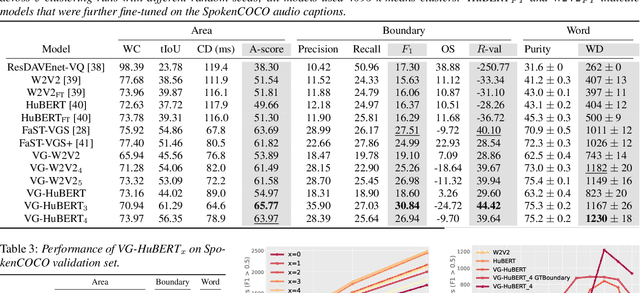
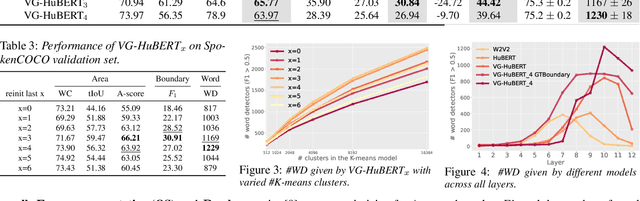
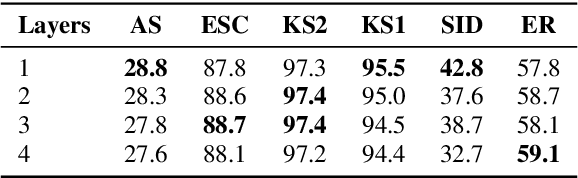
We present a method for visually-grounded spoken term discovery. After training either a HuBERT or wav2vec2.0 model to associate spoken captions with natural images, we show that powerful word segmentation and clustering capability emerges within the model's self-attention heads. Our experiments reveal that this ability is not present to nearly the same extent in the base HuBERT and wav2vec2.0 models, suggesting that the visual grounding task is a crucial component of the word discovery capability we observe. We also evaluate our method on the Buckeye word segmentation and ZeroSpeech spoken term discovery tasks, where we outperform all currently published methods on several metrics.
Self-Supervised Representation Learning for Speech Using Visual Grounding and Masked Language Modeling
Feb 07, 2022
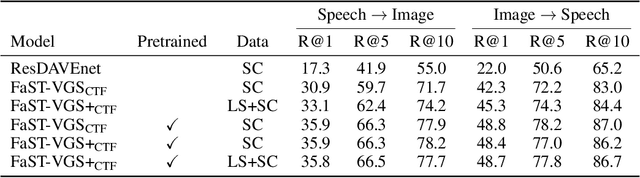
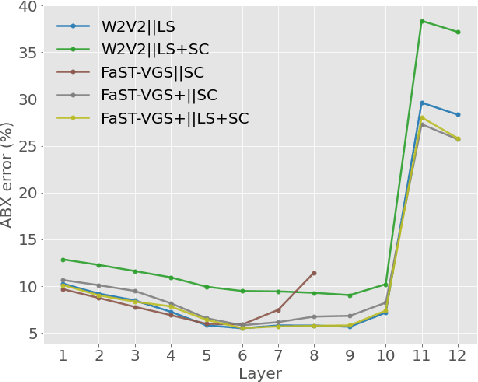
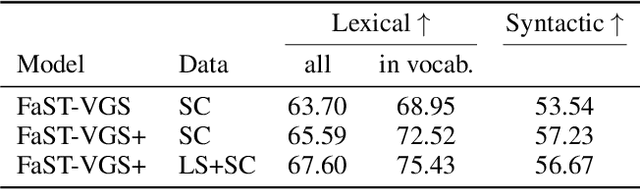
In this paper, we describe our submissions to the ZeroSpeech 2021 Challenge and SUPERB benchmark. Our submissions are based on the recently proposed FaST-VGS model, which is a Transformer-based model that learns to associate raw speech waveforms with semantically related images, all without the use of any transcriptions of the speech. Additionally, we introduce a novel extension of this model, FaST-VGS+, which is learned in a multi-task fashion with a masked language modeling objective in addition to the visual grounding objective. On ZeroSpeech 2021, we show that our models perform competitively on the ABX task, outperform all other concurrent submissions on the Syntactic and Semantic tasks, and nearly match the best system on the Lexical task. On the SUPERB benchmark, we show that our models also achieve strong performance, in some cases even outperforming the popular wav2vec2.0 model.
Everything at Once -- Multi-modal Fusion Transformer for Video Retrieval
Dec 08, 2021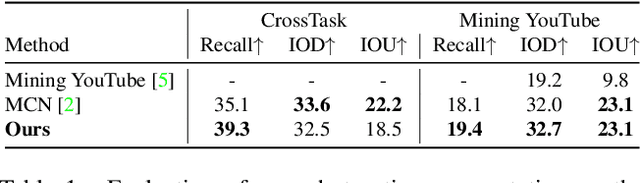

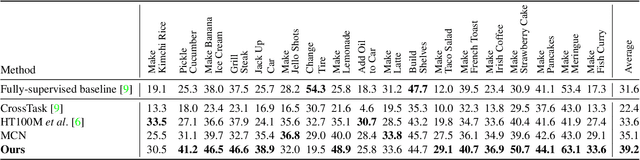
Multi-modal learning from video data has seen increased attention recently as it allows to train semantically meaningful embeddings without human annotation enabling tasks like zero-shot retrieval and classification. In this work, we present a multi-modal, modality agnostic fusion transformer approach that learns to exchange information between multiple modalities, such as video, audio, and text, and integrate them into a joined multi-modal representation to obtain an embedding that aggregates multi-modal temporal information. We propose to train the system with a combinatorial loss on everything at once, single modalities as well as pairs of modalities, explicitly leaving out any add-ons such as position or modality encoding. At test time, the resulting model can process and fuse any number of input modalities. Moreover, the implicit properties of the transformer allow to process inputs of different lengths. To evaluate the proposed approach, we train the model on the large scale HowTo100M dataset and evaluate the resulting embedding space on four challenging benchmark datasets obtaining state-of-the-art results in zero-shot video retrieval and zero-shot video action localization.
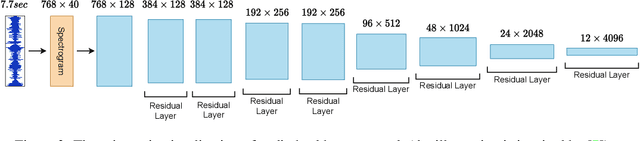
Routing with Self-Attention for Multimodal Capsule Networks
Dec 01, 2021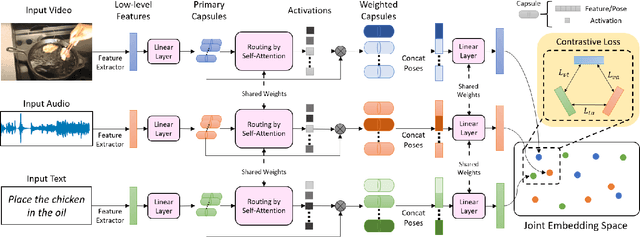
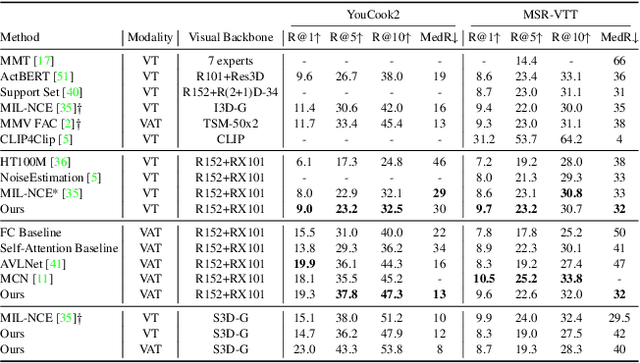
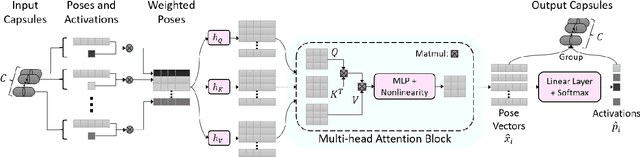
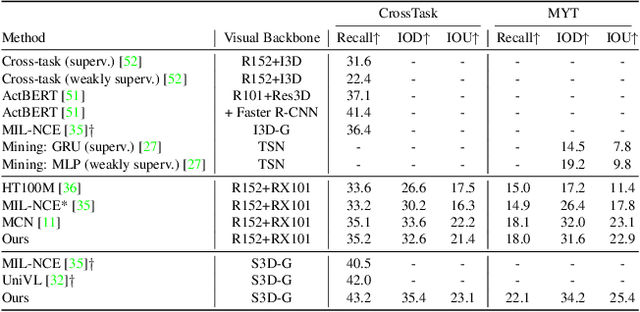
The task of multimodal learning has seen a growing interest recently as it allows for training neural architectures based on different modalities such as vision, text, and audio. One challenge in training such models is that they need to jointly learn semantic concepts and their relationships across different input representations. Capsule networks have been shown to perform well in context of capturing the relation between low-level input features and higher-level concepts. However, capsules have so far mainly been used only in small-scale fully supervised settings due to the resource demand of conventional routing algorithms. We present a new multimodal capsule network that allows us to leverage the strength of capsules in the context of a multimodal learning framework on large amounts of video data. To adapt the capsules to large-scale input data, we propose a novel routing by self-attention mechanism that selects relevant capsules which are then used to generate a final joint multimodal feature representation. This allows not only for robust training with noisy video data, but also to scale up the size of the capsule network compared to traditional routing methods while still being computationally efficient. We evaluate the proposed architecture by pretraining it on a large-scale multimodal video dataset and applying it on four datasets in two challenging downstream tasks. Results show that the proposed multimodal capsule network is not only able to improve results compared to other routing techniques, but also achieves competitive performance on the task of multimodal learning.