 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Task Planning for Mobile Manipulation: a Virtual Kinematic Chain Perspective
Aug 03, 2021
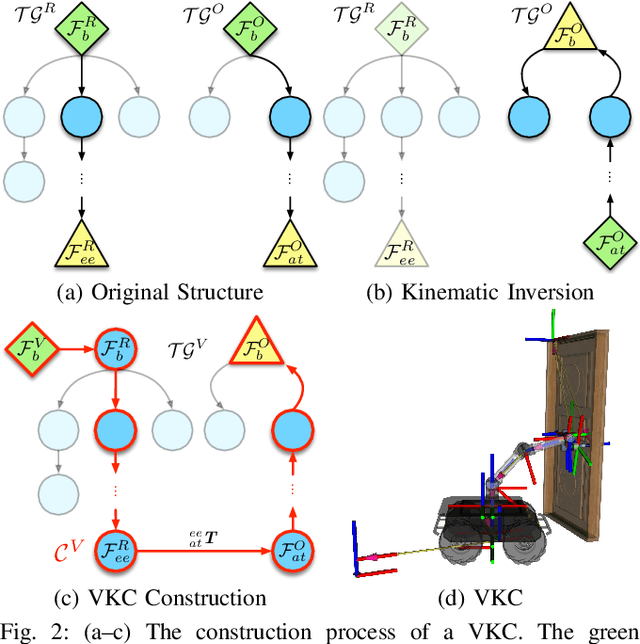
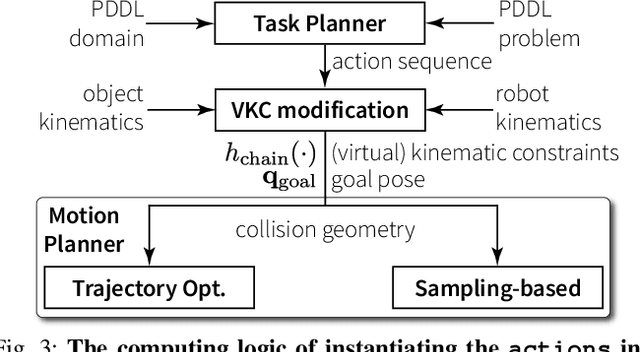
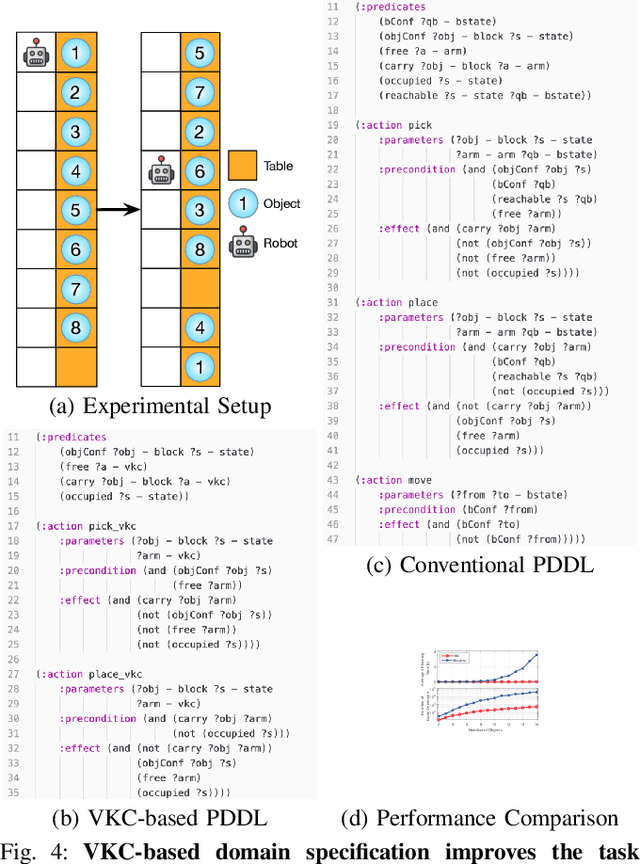
We present a Virtual Kinematic Chain (VKC) perspective, a simple yet effective method, to improve task planning efficacy for mobile manipulation. By consolidating the kinematics of the mobile base, the arm, and the object being manipulated collectively as a whole, this novel VKC perspective naturally defines abstract actions and eliminates unnecessary predicates in describing intermediate poses. As a result, these advantages simplify the design of the planning domain and significantly reduce the search space and branching factors in solving planning problems. In experiments, we implement a task planner using Planning Domain Definition Language (PDDL) with VKC. Compared with conventional domain definition, our VKC-based domain definition is more efficient in both planning time and memory. In addition, abstract actions perform better in producing feasible motion plans and trajectories. We further scale up the VKC-based task planner in complex mobile manipulation tasks. Taken together, these results demonstrate that task planning using VKC for mobile manipulation is not only natural and effective but also introduces new capabilities.
A multi-center prospective evaluation of THEIA to detect diabetic retinopathy (DR) and diabetic macular edema (DME) in the New Zealand screening program
Jun 23, 2021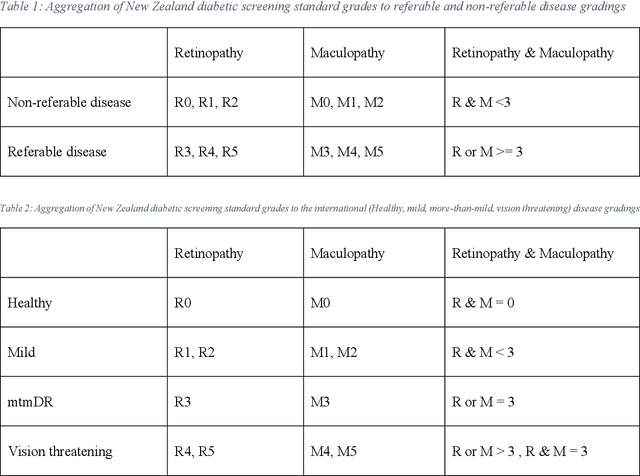
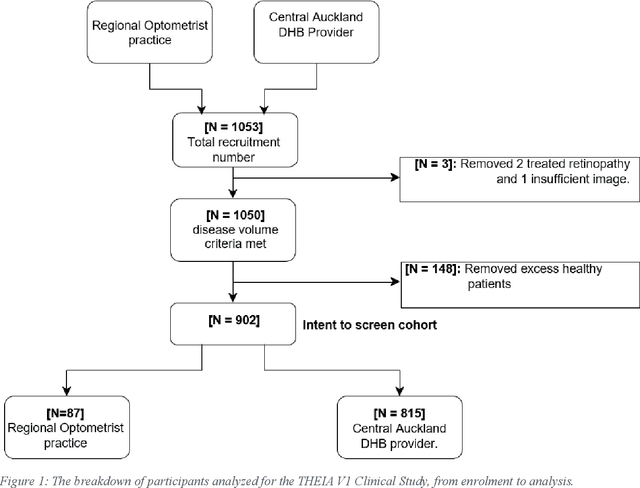
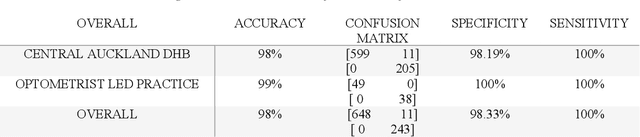
Purpose: to assess the efficacy of THEIA, an artificial intelligence for screening diabetic retinopathy in a multi-center prospective study. To validate the potential application of THEIA as clinical decision making assistant in a national screening program. Methods: 902 patients were recruited from either an urban large eye hospital, or a semi-rural optometrist led screening provider, as they were attending their appointment as part of New Zealand Diabetic Screening programme. These clinics used a variety of retinal cameras and a range of operators. The de-identified images were then graded independently by three senior retinal specialists, and final results were aggregated using New Zealand grading scheme, which is then converted to referable\non-referable and Healthy\mild\more than mild\vision threatening categories. Results: compared to ground truth, THEIA achieved 100% sensitivity and [95.35%-97.44%] specificity, and negative predictive value of 100%. THEIA also did not miss any patients with more than mild or vision threatening disease. The level of agreement between the clinicians and the aggregated results was (k value: 0.9881, 0.9557, and 0.9175), and the level of agreement between THEIA and the aggregated labels was (k value: 0.9515). Conclusion: Our multi-centre prospective trial showed that THEIA does not miss referable disease when screening for diabetic retinopathy and maculopathy. It also has a very high level of granularity in reporting the disease level. Since THEIA is being tested on a variety of cameras, operating in a range of clinics (rural\urban, ophthalmologist-led\optometrist-led), we believe that it will be a suitable addition to a public diabetic screening program.
A Statistician Teaches Deep Learning
Feb 03, 2021Deep learning (DL) has gained much attention and become increasingly popular in modern data science. Computer scientists led the way in developing deep learning techniques, so the ideas and perspectives can seem alien to statisticians. Nonetheless, it is important that statisticians become involved -- many of our students need this expertise for their careers. In this paper, developed as part of a program on DL held at the Statistical and Applied Mathematical Sciences Institute, we address this culture gap and provide tips on how to teach deep learning to statistics graduate students. After some background, we list ways in which DL and statistical perspectives differ, provide a recommended syllabus that evolved from teaching two iterations of a DL graduate course, offer examples of suggested homework assignments, give an annotated list of teaching resources, and discuss DL in the context of two research areas.