 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Variation in Subpopulation Susceptibility to Poisoning Attacks
Nov 20, 2023Machine learning is susceptible to poisoning attacks, in which an attacker controls a small fraction of the training data and chooses that data with the goal of inducing some behavior unintended by the model developer in the trained model. We consider a realistic setting in which the adversary with the ability to insert a limited number of data points attempts to control the model's behavior on a specific subpopulation. Inspired by previous observations on disparate effectiveness of random label-flipping attacks on different subpopulations, we investigate the properties that can impact the effectiveness of state-of-the-art poisoning attacks against different subpopulations. For a family of 2-dimensional synthetic datasets, we empirically find that dataset separability plays a dominant role in subpopulation vulnerability for less separable datasets. However, well-separated datasets exhibit more dependence on individual subpopulation properties. We further discover that a crucial subpopulation property is captured by the difference in loss on the clean dataset between the clean model and a target model that misclassifies the subpopulation, and a subpopulation is much easier to attack if the loss difference is small. This property also generalizes to high-dimensional benchmark datasets. For the Adult benchmark dataset, we show that we can find semantically-meaningful subpopulation properties that are related to the susceptibilities of a selected group of subpopulations. The results in this paper are accompanied by a fully interactive web-based visualization of subpopulation poisoning attacks found at https://uvasrg.github.io/visualizing-poisoning
SoK: Pitfalls in Evaluating Black-Box Attacks
Oct 26, 2023
Numerous works study black-box attacks on image classifiers. However, these works make different assumptions on the adversary's knowledge and current literature lacks a cohesive organization centered around the threat model. To systematize knowledge in this area, we propose a taxonomy over the threat space spanning the axes of feedback granularity, the access of interactive queries, and the quality and quantity of the auxiliary data available to the attacker. Our new taxonomy provides three key insights. 1) Despite extensive literature, numerous under-explored threat spaces exist, which cannot be trivially solved by adapting techniques from well-explored settings. We demonstrate this by establishing a new state-of-the-art in the less-studied setting of access to top-k confidence scores by adapting techniques from well-explored settings of accessing the complete confidence vector, but show how it still falls short of the more restrictive setting that only obtains the prediction label, highlighting the need for more research. 2) Identification the threat model of different attacks uncovers stronger baselines that challenge prior state-of-the-art claims. We demonstrate this by enhancing an initially weaker baseline (under interactive query access) via surrogate models, effectively overturning claims in the respective paper. 3) Our taxonomy reveals interactions between attacker knowledge that connect well to related areas, such as model inversion and extraction attacks. We discuss how advances in other areas can enable potentially stronger black-box attacks. Finally, we emphasize the need for a more realistic assessment of attack success by factoring in local attack runtime. This approach reveals the potential for certain attacks to achieve notably higher success rates and the need to evaluate attacks in diverse and harder settings, highlighting the need for better selection criteria.
SoK: Memorization in General-Purpose Large Language Models
Oct 24, 2023
Large Language Models (LLMs) are advancing at a remarkable pace, with myriad applications under development. Unlike most earlier machine learning models, they are no longer built for one specific application but are designed to excel in a wide range of tasks. A major part of this success is due to their huge training datasets and the unprecedented number of model parameters, which allow them to memorize large amounts of information contained in the training data. This memorization goes beyond mere language, and encompasses information only present in a few documents. This is often desirable since it is necessary for performing tasks such as question answering, and therefore an important part of learning, but also brings a whole array of issues, from privacy and security to copyright and beyond. LLMs can memorize short secrets in the training data, but can also memorize concepts like facts or writing styles that can be expressed in text in many different ways. We propose a taxonomy for memorization in LLMs that covers verbatim text, facts, ideas and algorithms, writing styles, distributional properties, and alignment goals. We describe the implications of each type of memorization - both positive and negative - for model performance, privacy, security and confidentiality, copyright, and auditing, and ways to detect and prevent memorization. We further highlight the challenges that arise from the predominant way of defining memorization with respect to model behavior instead of model weights, due to LLM-specific phenomena such as reasoning capabilities or differences between decoding algorithms. Throughout the paper, we describe potential risks and opportunities arising from memorization in LLMs that we hope will motivate new research directions.
When Can Linear Learners be Robust to Indiscriminate Poisoning Attacks?
Jul 03, 2023



We study indiscriminate poisoning for linear learners where an adversary injects a few crafted examples into the training data with the goal of forcing the induced model to incur higher test error. Inspired by the observation that linear learners on some datasets are able to resist the best known attacks even without any defenses, we further investigate whether datasets can be inherently robust to indiscriminate poisoning attacks for linear learners. For theoretical Gaussian distributions, we rigorously characterize the behavior of an optimal poisoning attack, defined as the poisoning strategy that attains the maximum risk of the induced model at a given poisoning budget. Our results prove that linear learners can indeed be robust to indiscriminate poisoning if the class-wise data distributions are well-separated with low variance and the size of the constraint set containing all permissible poisoning points is also small. These findings largely explain the drastic variation in empirical attack performance of the state-of-the-art poisoning attacks on linear learners across benchmark datasets, making an important initial step towards understanding the underlying reasons some learning tasks are vulnerable to data poisoning attacks.
Manipulating Transfer Learning for Property Inference
Mar 21, 2023



Transfer learning is a popular method for tuning pretrained (upstream) models for different downstream tasks using limited data and computational resources. We study how an adversary with control over an upstream model used in transfer learning can conduct property inference attacks on a victim's tuned downstream model. For example, to infer the presence of images of a specific individual in the downstream training set. We demonstrate attacks in which an adversary can manipulate the upstream model to conduct highly effective and specific property inference attacks (AUC score $> 0.9$), without incurring significant performance loss on the main task. The main idea of the manipulation is to make the upstream model generate activations (intermediate features) with different distributions for samples with and without a target property, thus enabling the adversary to distinguish easily between downstream models trained with and without training examples that have the target property. Our code is available at https://github.com/yulongt23/Transfer-Inference.
GlucoSynth: Generating Differentially-Private Synthetic Glucose Traces
Mar 02, 2023In this paper we focus on the problem of generating high-quality, private synthetic glucose traces, a task generalizable to many other time series sources. Existing methods for time series data synthesis, such as those using Generative Adversarial Networks (GANs), are not able to capture the innate characteristics of glucose data and, in terms of privacy, either do not include any formal privacy guarantees or, in order to uphold a strong formal privacy guarantee, severely degrade the utility of the synthetic data. Therefore, in this paper we present GlucoSynth, a novel privacy-preserving GAN framework to generate synthetic glucose traces. The core intuition in our approach is to conserve relationships amongst motifs (glucose events) within the traces, in addition to typical temporal dynamics. Moreover, we integrate differential privacy into the framework to provide strong formal privacy guarantees. Finally, we provide a comprehensive evaluation on the real-world utility of the data using 1.2 million glucose traces
TrojanPuzzle: Covertly Poisoning Code-Suggestion Models
Jan 06, 2023



With tools like GitHub Copilot, automatic code suggestion is no longer a dream in software engineering. These tools, based on large language models, are typically trained on massive corpora of code mined from unvetted public sources. As a result, these models are susceptible to data poisoning attacks where an adversary manipulates the model's training or fine-tuning phases by injecting malicious data. Poisoning attacks could be designed to influence the model's suggestions at run time for chosen contexts, such as inducing the model into suggesting insecure code payloads. To achieve this, prior poisoning attacks explicitly inject the insecure code payload into the training data, making the poisoning data detectable by static analysis tools that can remove such malicious data from the training set. In this work, we demonstrate two novel data poisoning attacks, COVERT and TROJANPUZZLE, that can bypass static analysis by planting malicious poisoning data in out-of-context regions such as docstrings. Our most novel attack, TROJANPUZZLE, goes one step further in generating less suspicious poisoning data by never including certain (suspicious) parts of the payload in the poisoned data, while still inducing a model that suggests the entire payload when completing code (i.e., outside docstrings). This makes TROJANPUZZLE robust against signature-based dataset-cleansing methods that identify and filter out suspicious sequences from the training data. Our evaluation against two model sizes demonstrates that both COVERT and TROJANPUZZLE have significant implications for how practitioners should select code used to train or tune code-suggestion models.
SoK: Let The Privacy Games Begin! A Unified Treatment of Data Inference Privacy in Machine Learning
Dec 21, 2022


Deploying machine learning models in production may allow adversaries to infer sensitive information about training data. There is a vast literature analyzing different types of inference risks, ranging from membership inference to reconstruction attacks. Inspired by the success of games (i.e., probabilistic experiments) to study security properties in cryptography, some authors describe privacy inference risks in machine learning using a similar game-based style. However, adversary capabilities and goals are often stated in subtly different ways from one presentation to the other, which makes it hard to relate and compose results. In this paper, we present a game-based framework to systematize the body of knowledge on privacy inference risks in machine learning.
Dissecting Distribution Inference
Dec 15, 2022



A distribution inference attack aims to infer statistical properties of data used to train machine learning models. These attacks are sometimes surprisingly potent, but the factors that impact distribution inference risk are not well understood and demonstrated attacks often rely on strong and unrealistic assumptions such as full knowledge of training environments even in supposedly black-box threat scenarios. To improve understanding of distribution inference risks, we develop a new black-box attack that even outperforms the best known white-box attack in most settings. Using this new attack, we evaluate distribution inference risk while relaxing a variety of assumptions about the adversary's knowledge under black-box access, like known model architectures and label-only access. Finally, we evaluate the effectiveness of previously proposed defenses and introduce new defenses. We find that although noise-based defenses appear to be ineffective, a simple re-sampling defense can be highly effective. Code is available at https://github.com/iamgroot42/dissecting_distribution_inference
Are Attribute Inference Attacks Just Imputation?
Sep 02, 2022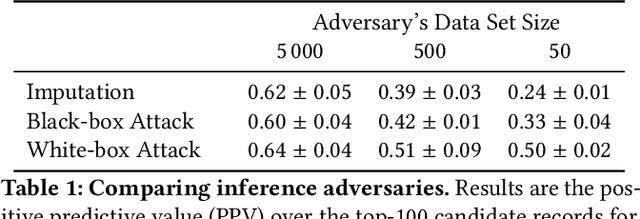
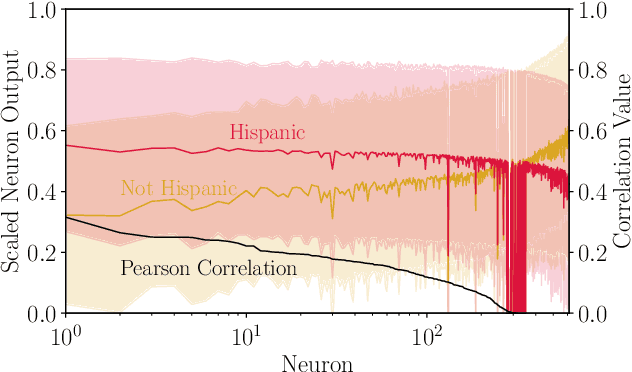
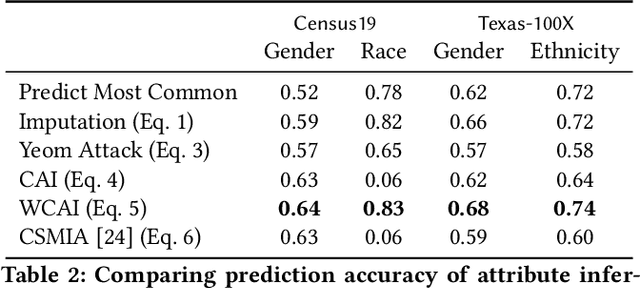
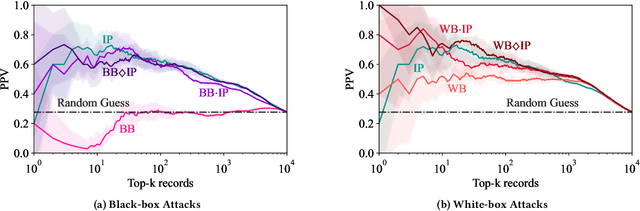
Models can expose sensitive information about their training data. In an attribute inference attack, an adversary has partial knowledge of some training records and access to a model trained on those records, and infers the unknown values of a sensitive feature of those records. We study a fine-grained variant of attribute inference we call \emph{sensitive value inference}, where the adversary's goal is to identify with high confidence some records from a candidate set where the unknown attribute has a particular sensitive value. We explicitly compare attribute inference with data imputation that captures the training distribution statistics, under various assumptions about the training data available to the adversary. Our main conclusions are: (1) previous attribute inference methods do not reveal more about the training data from the model than can be inferred by an adversary without access to the trained model, but with the same knowledge of the underlying distribution as needed to train the attribute inference attack; (2) black-box attribute inference attacks rarely learn anything that cannot be learned without the model; but (3) white-box attacks, which we introduce and evaluate in the paper, can reliably identify some records with the sensitive value attribute that would not be predicted without having access to the model. Furthermore, we show that proposed defenses such as differentially private training and removing vulnerable records from training do not mitigate this privacy risk. The code for our experiments is available at \url{https://github.com/bargavj/EvaluatingDPML}.