 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Prioritized Experience Replay
Mar 02, 2018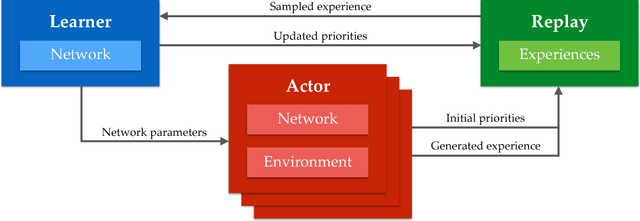
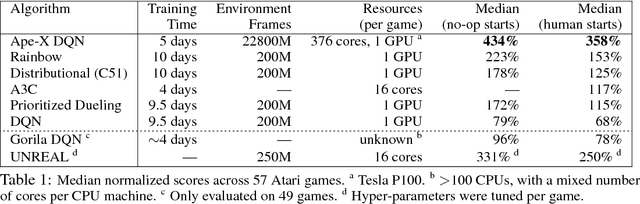
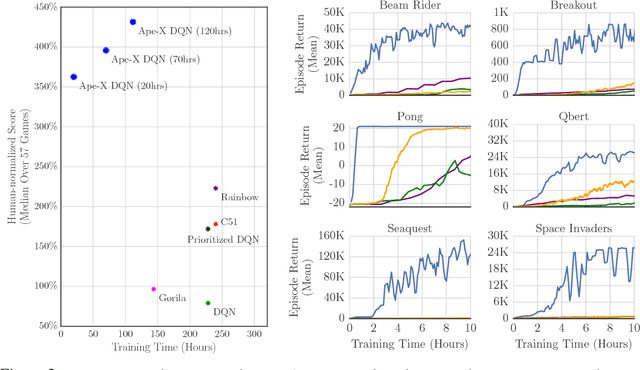
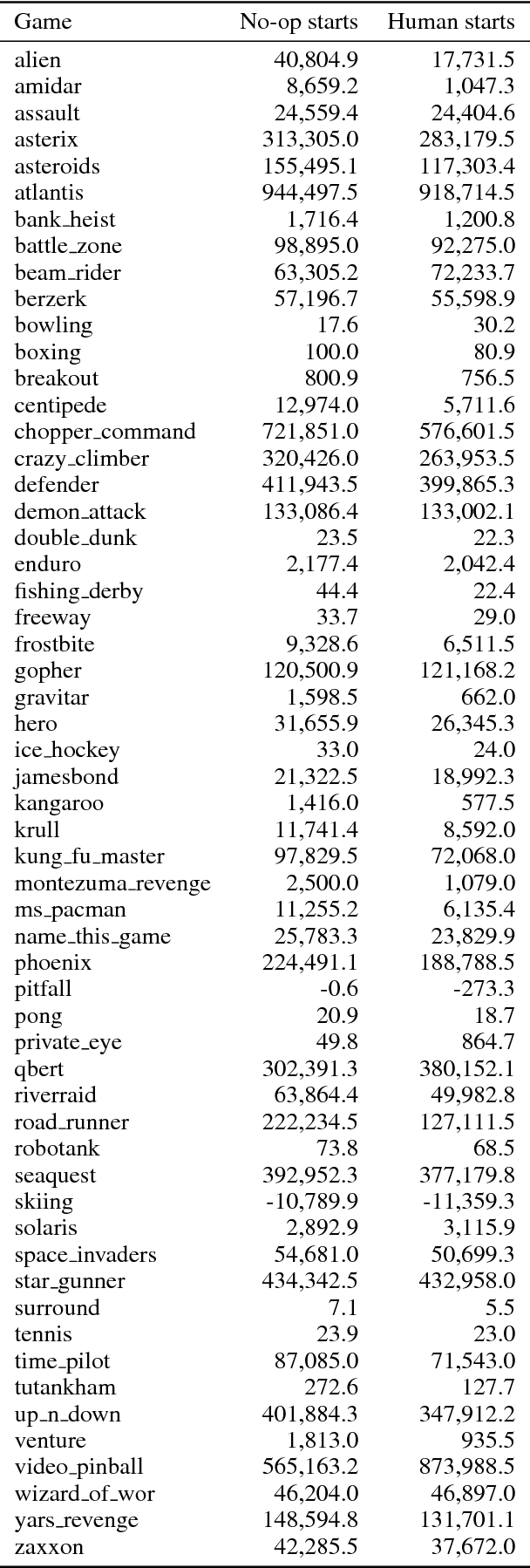
We propose a distributed architecture for deep reinforcement learning at scale, that enables agents to learn effectively from orders of magnitude more data than previously possible. The algorithm decouples acting from learning: the actors interact with their own instances of the environment by selecting actions according to a shared neural network, and accumulate the resulting experience in a shared experience replay memory; the learner replays samples of experience and updates the neural network. The architecture relies on prioritized experience replay to focus only on the most significant data generated by the actors. Our architecture substantially improves the state of the art on the Arcade Learning Environment, achieving better final performance in a fraction of the wall-clock training time.
DeepMind Control Suite
Jan 02, 2018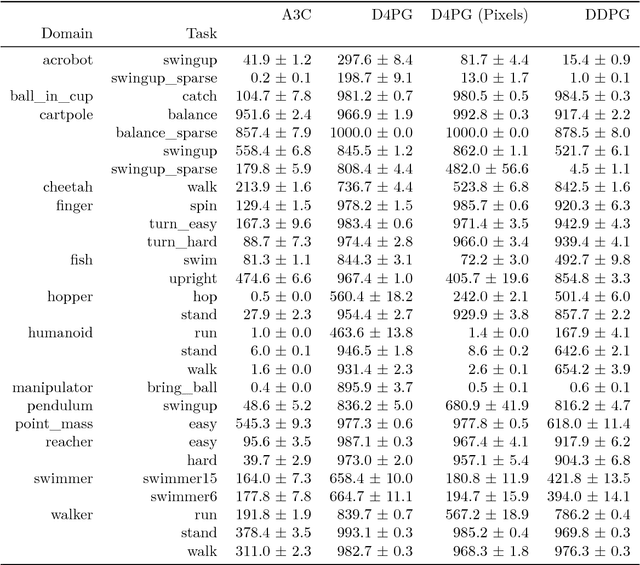
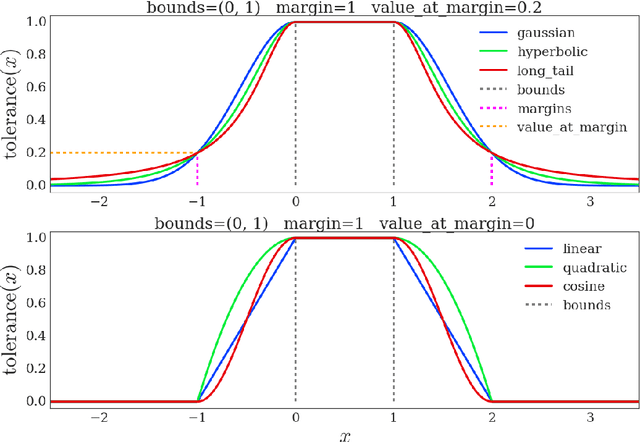
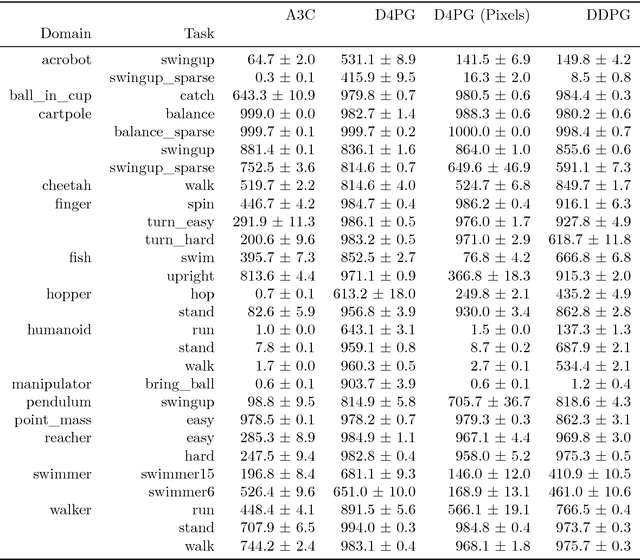
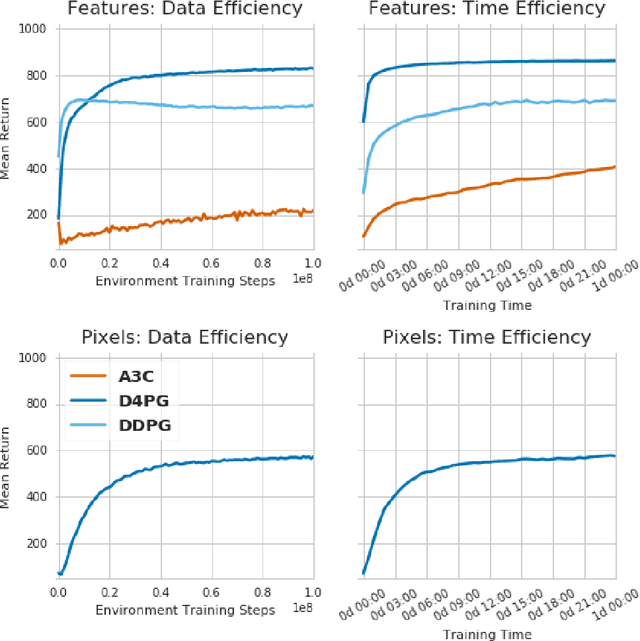
The DeepMind Control Suite is a set of continuous control tasks with a standardised structure and interpretable rewards, intended to serve as performance benchmarks for reinforcement learning agents. The tasks are written in Python and powered by the MuJoCo physics engine, making them easy to use and modify. We include benchmarks for several learning algorithms. The Control Suite is publicly available at https://www.github.com/deepmind/dm_control . A video summary of all tasks is available at http://youtu.be/rAai4QzcYbs .
Deep Tensor Convolution on Multicores
Jun 11, 2017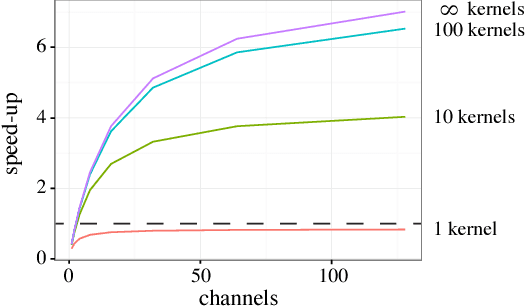
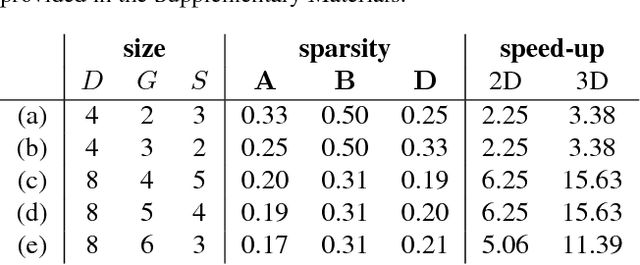
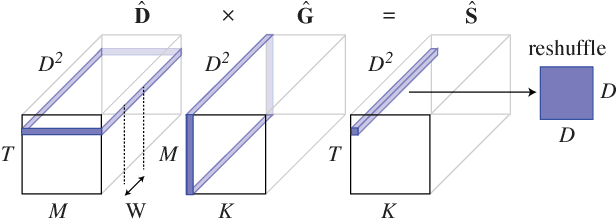
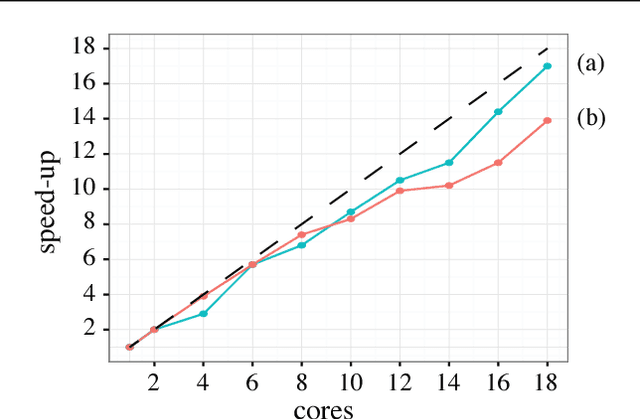
Deep convolutional neural networks (ConvNets) of 3-dimensional kernels allow joint modeling of spatiotemporal features. These networks have improved performance of video and volumetric image analysis, but have been limited in size due to the low memory ceiling of GPU hardware. Existing CPU implementations overcome this constraint but are impractically slow. Here we extend and optimize the faster Winograd-class of convolutional algorithms to the $N$-dimensional case and specifically for CPU hardware. First, we remove the need to manually hand-craft algorithms by exploiting the relaxed constraints and cheap sparse access of CPU memory. Second, we maximize CPU utilization and multicore scalability by transforming data matrices to be cache-aware, integer multiples of AVX vector widths. Treating 2-dimensional ConvNets as a special (and the least beneficial) case of our approach, we demonstrate a 5 to 25-fold improvement in throughput compared to previous state-of-the-art.
Generative Compression
Jun 04, 2017
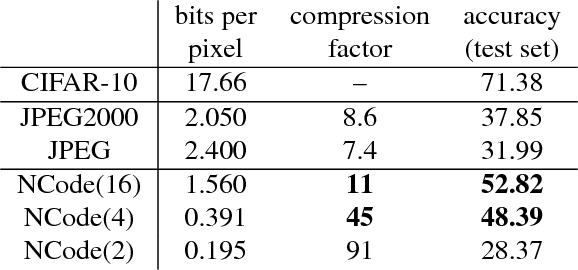
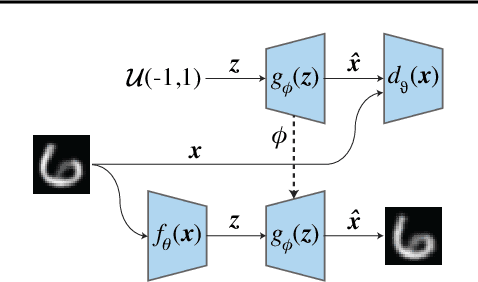
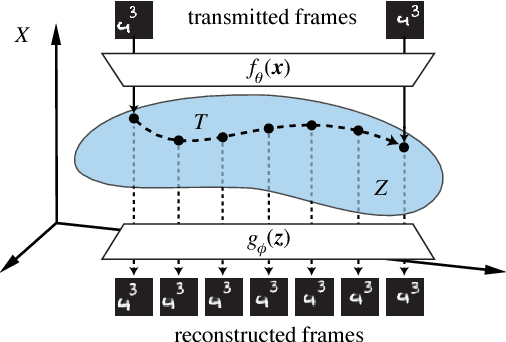
Traditional image and video compression algorithms rely on hand-crafted encoder/decoder pairs (codecs) that lack adaptability and are agnostic to the data being compressed. Here we describe the concept of generative compression, the compression of data using generative models, and suggest that it is a direction worth pursuing to produce more accurate and visually pleasing reconstructions at much deeper compression levels for both image and video data. We also demonstrate that generative compression is orders-of-magnitude more resilient to bit error rates (e.g. from noisy wireless channels) than traditional variable-length coding schemes.
Toward Streaming Synapse Detection with Compositional ConvNets
Feb 23, 2017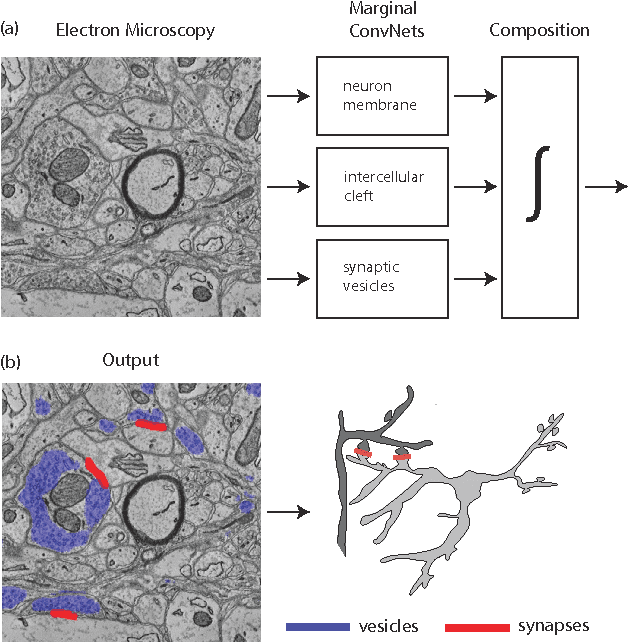
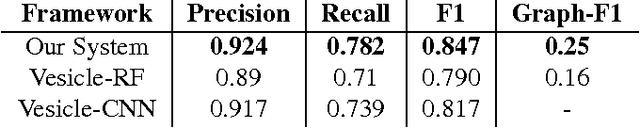
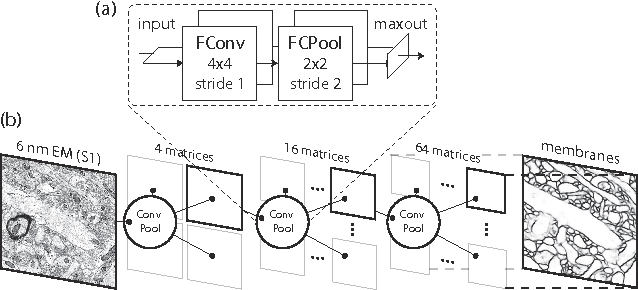
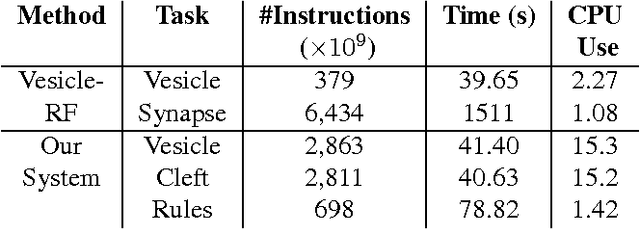
Connectomics is an emerging field in neuroscience that aims to reconstruct the 3-dimensional morphology of neurons from electron microscopy (EM) images. Recent studies have successfully demonstrated the use of convolutional neural networks (ConvNets) for segmenting cell membranes to individuate neurons. However, there has been comparatively little success in high-throughput identification of the intercellular synaptic connections required for deriving connectivity graphs. In this study, we take a compositional approach to segmenting synapses, modeling them explicitly as an intercellular cleft co-located with an asymmetric vesicle density along a cell membrane. Instead of requiring a deep network to learn all natural combinations of this compositionality, we train lighter networks to model the simpler marginal distributions of membranes, clefts and vesicles from just 100 electron microscopy samples. These feature maps are then combined with simple rules-based heuristics derived from prior biological knowledge. Our approach to synapse detection is both more accurate than previous state-of-the-art (7% higher recall and 5% higher F1-score) and yields a 20-fold speed-up compared to the previous fastest implementations. We demonstrate by reconstructing the first complete, directed connectome from the largest available anisotropic microscopy dataset (245 GB) of mouse somatosensory cortex (S1) in just 9.7 hours on a single shared-memory CPU system. We believe that this work marks an important step toward the goal of a microscope-pace streaming connectomics pipeline.
A Multi-Pass Approach to Large-Scale Connectomics
Dec 07, 2016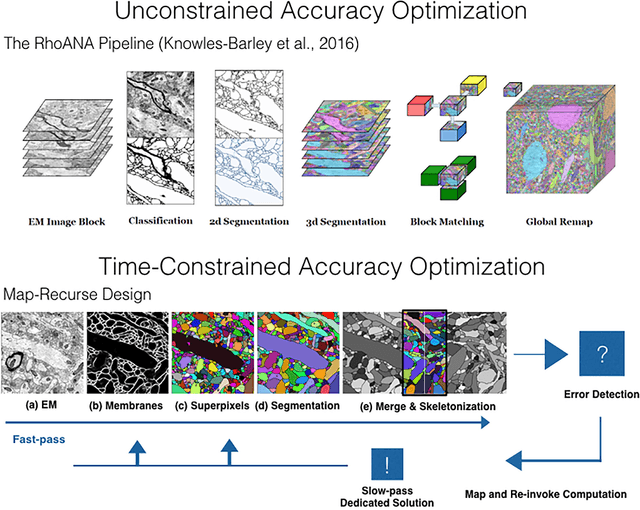
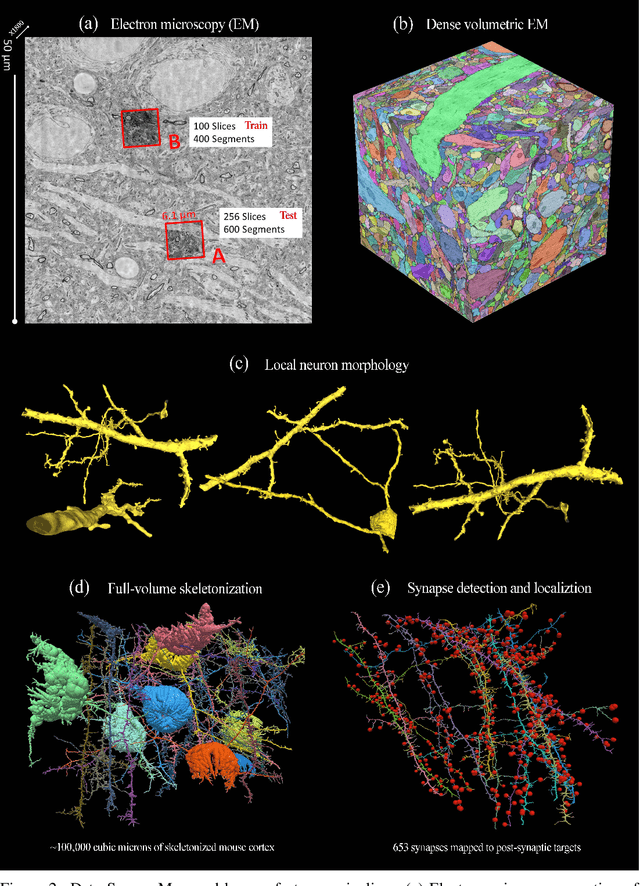
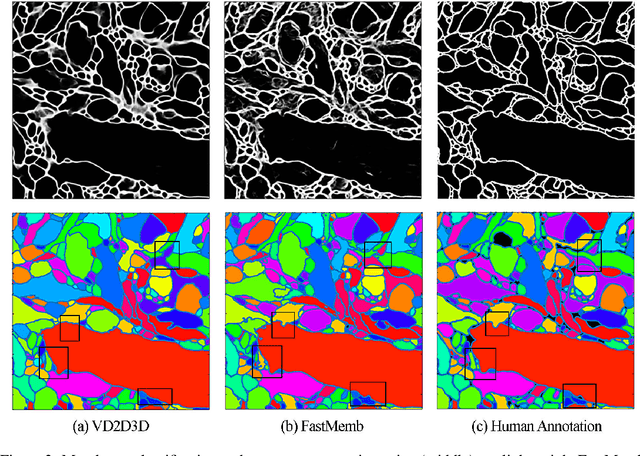
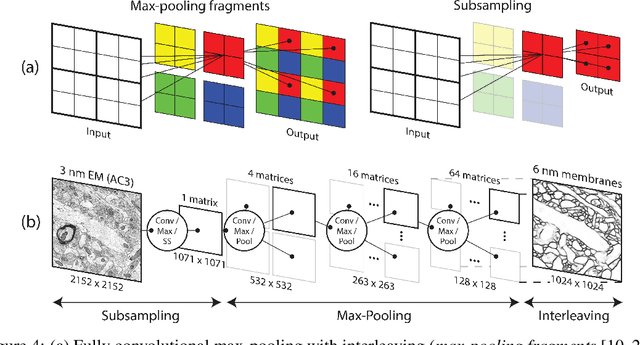
The field of connectomics faces unprecedented "big data" challenges. To reconstruct neuronal connectivity, automated pixel-level segmentation is required for petabytes of streaming electron microscopy data. Existing algorithms provide relatively good accuracy but are unacceptably slow, and would require years to extract connectivity graphs from even a single cubic millimeter of neural tissue. Here we present a viable real-time solution, a multi-pass pipeline optimized for shared-memory multicore systems, capable of processing data at near the terabyte-per-hour pace of multi-beam electron microscopes. The pipeline makes an initial fast-pass over the data, and then makes a second slow-pass to iteratively correct errors in the output of the fast-pass. We demonstrate the accuracy of a sparse slow-pass reconstruction algorithm and suggest new methods for detecting morphological errors. Our fast-pass approach provided many algorithmic challenges, including the design and implementation of novel shallow convolutional neural nets and the parallelization of watershed and object-merging techniques. We use it to reconstruct, from image stack to skeletons, the full dataset of Kasthuri et al. (463 GB capturing 120,000 cubic microns) in a matter of hours on a single multicore machine rather than the weeks it has taken in the past on much larger distributed systems.
Addressing the non-functional requirements of computer vision systems: A case study
Oct 31, 2014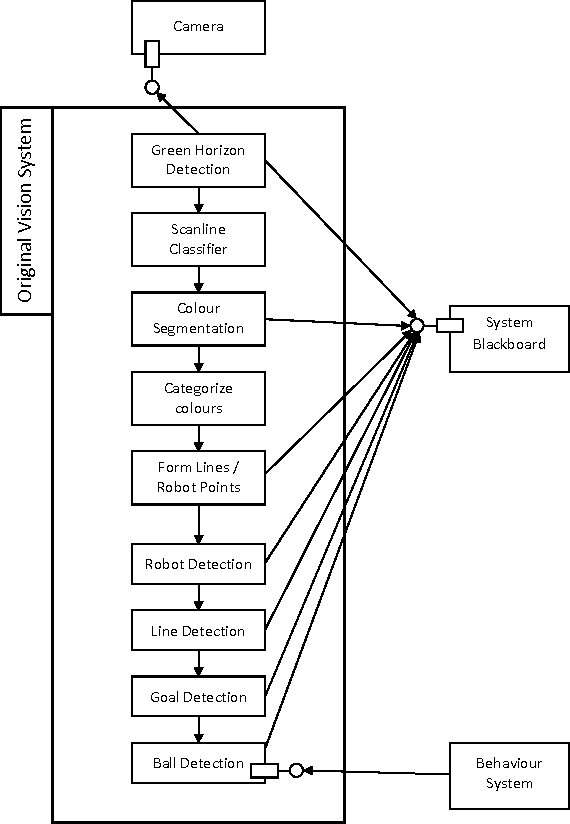
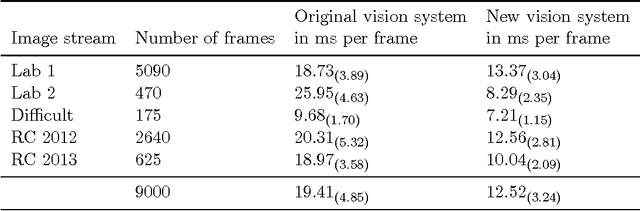
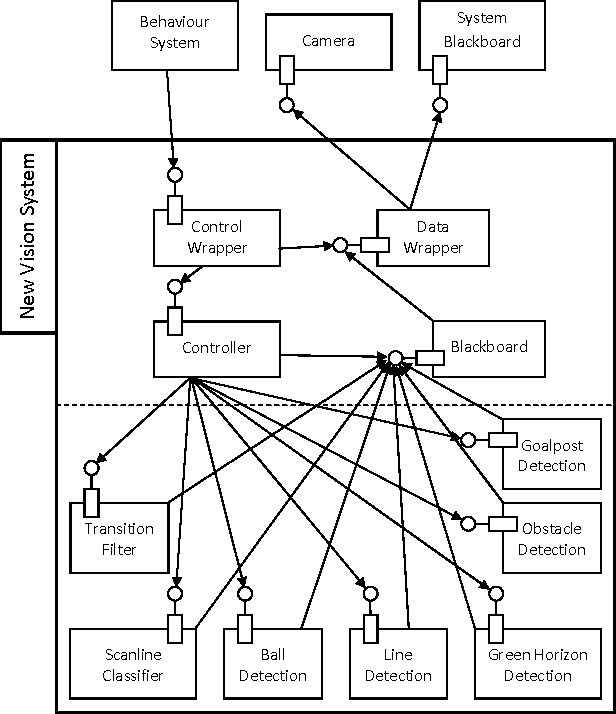
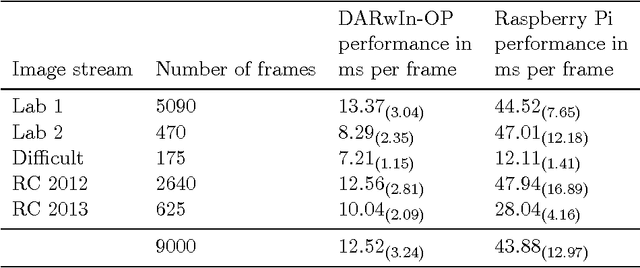
Computer vision plays a major role in the robotics industry, where vision data is frequently used for navigation and high-level decision making. Although there is significant research in algorithms and functional requirements, there is a comparative lack of emphasis on how best to map these abstract concepts onto an appropriate software architecture. In this study, we distinguish between the functional and non-functional requirements of a computer vision system. Using a RoboCup humanoid robot system as a case study, we propose and develop a software architecture that fulfills the latter criteria. The modifiability of the proposed architecture is demonstrated by detailing a number of feature detection algorithms and emphasizing which aspects of the underlying framework were modified to support their integration. To demonstrate portability, we port our vision system (designed for an application-specific DARwIn-OP humanoid robot) to a general-purpose, Raspberry Pi computer. We evaluate performance on both platforms and compare them to a vision system optimised for functional requirements only. The architecture and implementation presented in this study provide a highly generalisable framework for computer vision system design that is of particular benefit in research and development, competition and other environments in which rapid system evolution is necessary.
Simulation leagues: Analysis of competition formats
Jun 26, 2014
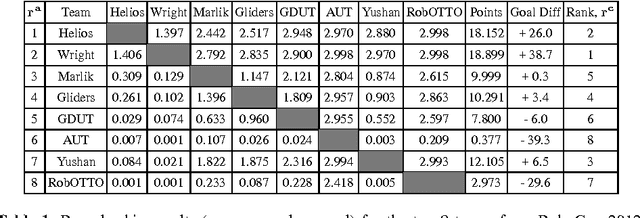
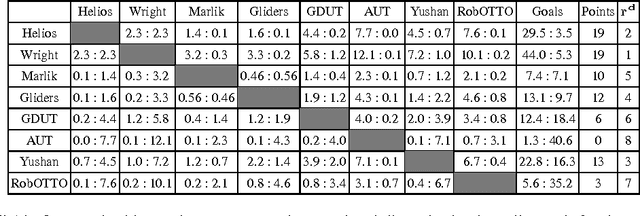
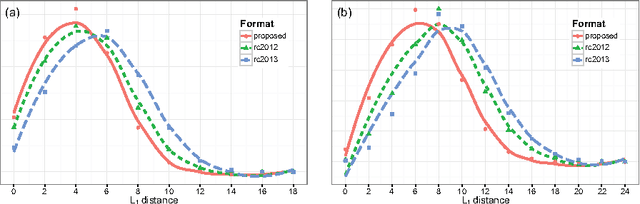
The selection of an appropriate competition format is critical for both the success and credibility of any competition, both real and simulated. In this paper, the automated parallelism offered by the RoboCupSoccer 2D simulation league is leveraged to conduct a 28,000 game round-robin between the top 8 teams from RoboCup 2012 and 2013. A proposed new competition format is found to reduce variation from the resultant statistically significant team performance rankings by 75% and 67%, when compared to the actual competition results from RoboCup 2012 and 2013 respectively. These results are statistically validated by generating 10,000 random tournaments for each of the three considered formats and comparing the respective distributions of ranking discrepancy.
RANSAC: Identification of Higher-Order Geometric Features and Applications in Humanoid Robot Soccer
Oct 22, 2013
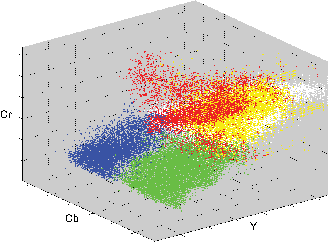
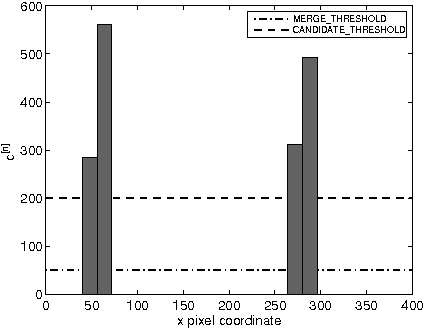

The ability for an autonomous agent to self-localise is directly proportional to the accuracy and precision with which it can perceive salient features within its local environment. The identification of such features by recognising geometric profile allows robustness against lighting variations, which is necessary in most industrial robotics applications. This paper details a framework by which the random sample consensus (RANSAC) algorithm, often applied to parameter fitting in linear models, can be extended to identify higher-order geometric features. Goalpost identification within humanoid robot soccer is investigated as an application, with the developed system yielding an order-of-magnitude improvement in classification performance relative to a traditional histogramming methodology.