 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring
Nov 21, 2019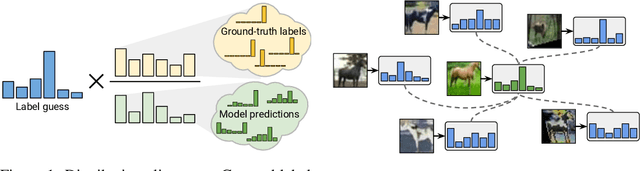
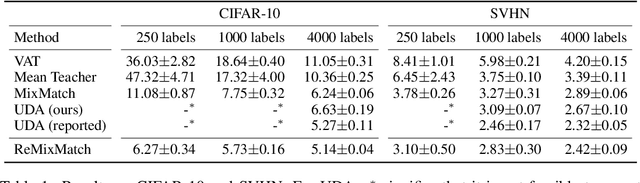
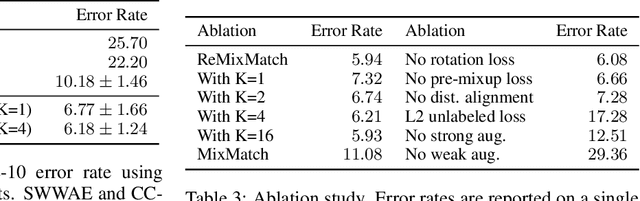
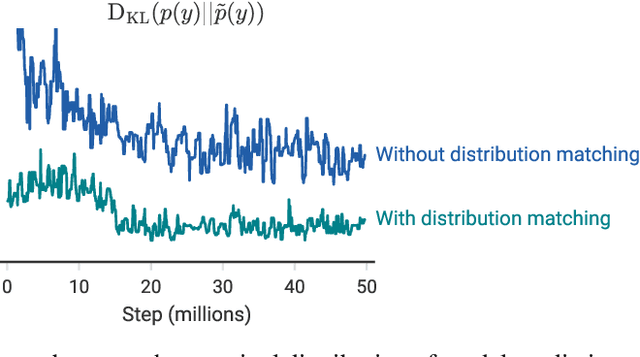
We improve the recently-proposed "MixMatch" semi-supervised learning algorithm by introducing two new techniques: distribution alignment and augmentation anchoring. Distribution alignment encourages the marginal distribution of predictions on unlabeled data to be close to the marginal distribution of ground-truth labels. Augmentation anchoring feeds multiple strongly augmented versions of an input into the model and encourages each output to be close to the prediction for a weakly-augmented version of the same input. To produce strong augmentations, we propose a variant of AutoAugment which learns the augmentation policy while the model is being trained. Our new algorithm, dubbed ReMixMatch, is significantly more data-efficient than prior work, requiring between $5\times$ and $16\times$ less data to reach the same accuracy. For example, on CIFAR-10 with 250 labeled examples we reach $93.73\%$ accuracy (compared to MixMatch's accuracy of $93.58\%$ with $4{,}000$ examples) and a median accuracy of $84.92\%$ with just four labels per class. We make our code and data open-source at https://github.com/google-research/remixmatch.
High-Fidelity Extraction of Neural Network Models
Sep 03, 2019
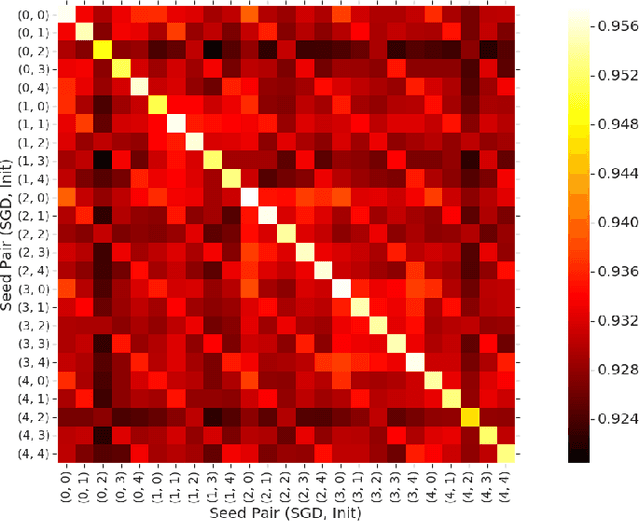

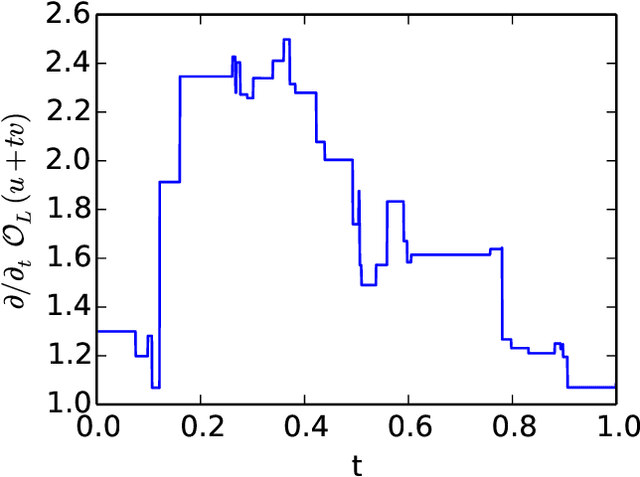
Model extraction allows an adversary to steal a copy of a remotely deployed machine learning model given access to its predictions. Adversaries are motivated to mount such attacks for a variety of reasons, ranging from reducing their computational costs, to eliminating the need to collect expensive training data, to obtaining a copy of a model in order to find adversarial examples, perform membership inference, or model inversion attacks. In this paper, we taxonomize the space of model extraction attacks around two objectives: \emph{accuracy}, i.e., performing well on the underlying learning task, and \emph{fidelity}, i.e., matching the predictions of the remote victim classifier on any input. To extract a high-accuracy model, we develop a learning-based attack which exploits the victim to supervise the training of an extracted model. Through analytical and empirical arguments, we then explain the inherent limitations that prevent any learning-based strategy from extracting a truly high-fidelity model---i.e., extracting a functionally-equivalent model whose predictions are identical to those of the victim model on all possible inputs. Addressing these limitations, we expand on prior work to develop the first practical functionally-equivalent extraction attack for direct extraction (i.e., without training) of a model's weights. We perform experiments both on academic datasets and a state-of-the-art image classifier trained with 1 billion proprietary images. In addition to broadening the scope of model extraction research, our work demonstrates the practicality of model extraction attacks against production-grade systems.
MixMatch: A Holistic Approach to Semi-Supervised Learning
May 06, 2019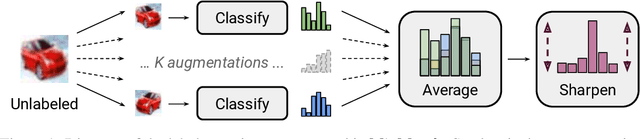

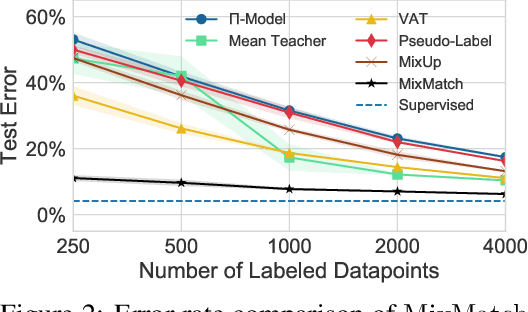

Semi-supervised learning has proven to be a powerful paradigm for leveraging unlabeled data to mitigate the reliance on large labeled datasets. In this work, we unify the current dominant approaches for semi-supervised learning to produce a new algorithm, MixMatch, that works by guessing low-entropy labels for data-augmented unlabeled examples and mixing labeled and unlabeled data using MixUp. We show that MixMatch obtains state-of-the-art results by a large margin across many datasets and labeled data amounts. For example, on CIFAR-10 with 250 labels, we reduce error rate by a factor of 4 (from 38% to 11%) and by a factor of 2 on STL-10. We also demonstrate how MixMatch can help achieve a dramatically better accuracy-privacy trade-off for differential privacy. Finally, we perform an ablation study to tease apart which components of MixMatch are most important for its success.
Understanding and Improving Interpolation in Autoencoders via an Adversarial Regularizer
Jul 23, 2018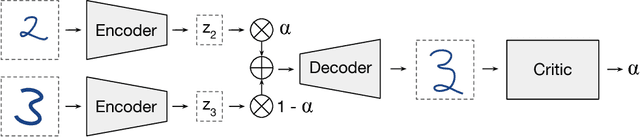
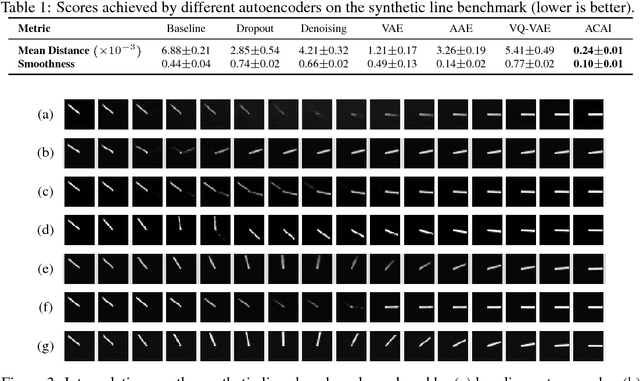

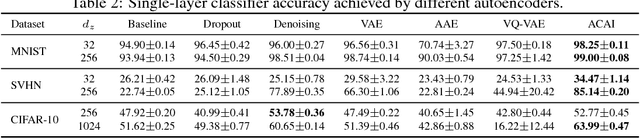
Autoencoders provide a powerful framework for learning compressed representations by encoding all of the information needed to reconstruct a data point in a latent code. In some cases, autoencoders can "interpolate": By decoding the convex combination of the latent codes for two datapoints, the autoencoder can produce an output which semantically mixes characteristics from the datapoints. In this paper, we propose a regularization procedure which encourages interpolated outputs to appear more realistic by fooling a critic network which has been trained to recover the mixing coefficient from interpolated data. We then develop a simple benchmark task where we can quantitatively measure the extent to which various autoencoders can interpolate and show that our regularizer dramatically improves interpolation in this setting. We also demonstrate empirically that our regularizer produces latent codes which are more effective on downstream tasks, suggesting a possible link between interpolation abilities and learning useful representations.
Technical Report on the CleverHans v2.1.0 Adversarial Examples Library
Jun 27, 2018CleverHans is a software library that provides standardized reference implementations of adversarial example construction techniques and adversarial training. The library may be used to develop more robust machine learning models and to provide standardized benchmarks of models' performance in the adversarial setting. Benchmarks constructed without a standardized implementation of adversarial example construction are not comparable to each other, because a good result may indicate a robust model or it may merely indicate a weak implementation of the adversarial example construction procedure. This technical report is structured as follows. Section 1 provides an overview of adversarial examples in machine learning and of the CleverHans software. Section 2 presents the core functionalities of the library: namely the attacks based on adversarial examples and defenses to improve the robustness of machine learning models to these attacks. Section 3 describes how to report benchmark results using the library. Section 4 describes the versioning system.
BEGAN: Boundary Equilibrium Generative Adversarial Networks
May 31, 2017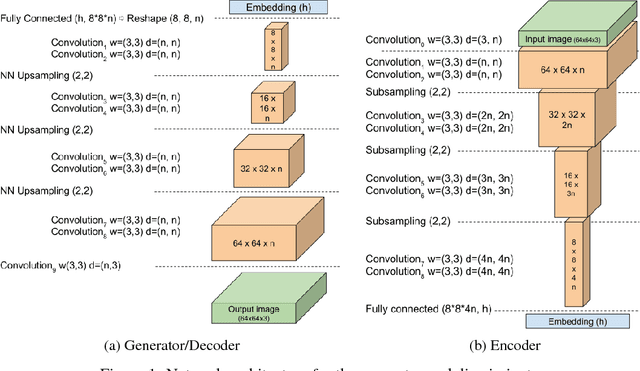
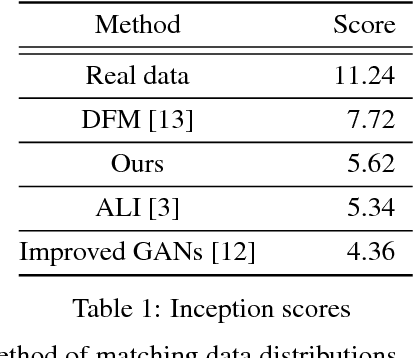


We propose a new equilibrium enforcing method paired with a loss derived from the Wasserstein distance for training auto-encoder based Generative Adversarial Networks. This method balances the generator and discriminator during training. Additionally, it provides a new approximate convergence measure, fast and stable training and high visual quality. We also derive a way of controlling the trade-off between image diversity and visual quality. We focus on the image generation task, setting a new milestone in visual quality, even at higher resolutions. This is achieved while using a relatively simple model architecture and a standard training procedure.
WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia
Mar 15, 2017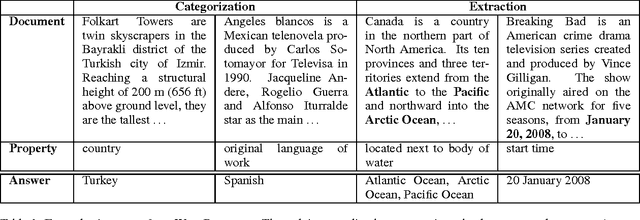
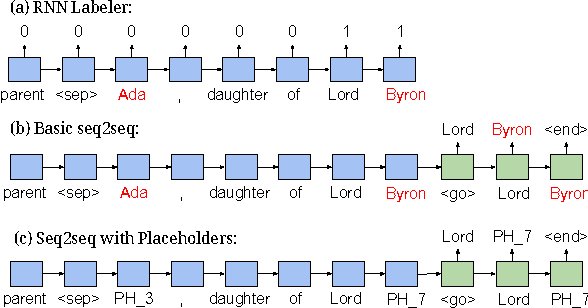
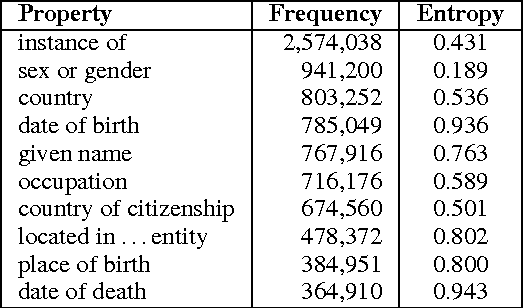
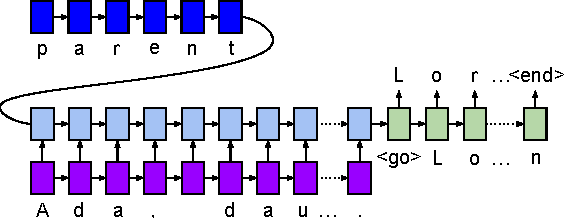
We present WikiReading, a large-scale natural language understanding task and publicly-available dataset with 18 million instances. The task is to predict textual values from the structured knowledge base Wikidata by reading the text of the corresponding Wikipedia articles. The task contains a rich variety of challenging classification and extraction sub-tasks, making it well-suited for end-to-end models such as deep neural networks (DNNs). We compare various state-of-the-art DNN-based architectures for document classification, information extraction, and question answering. We find that models supporting a rich answer space, such as word or character sequences, perform best. Our best-performing model, a word-level sequence to sequence model with a mechanism to copy out-of-vocabulary words, obtains an accuracy of 71.8%.