 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Evaluation of Ranked Lists using Parametric Estimation of Propensities
Jun 06, 2022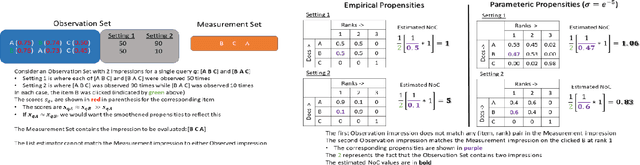
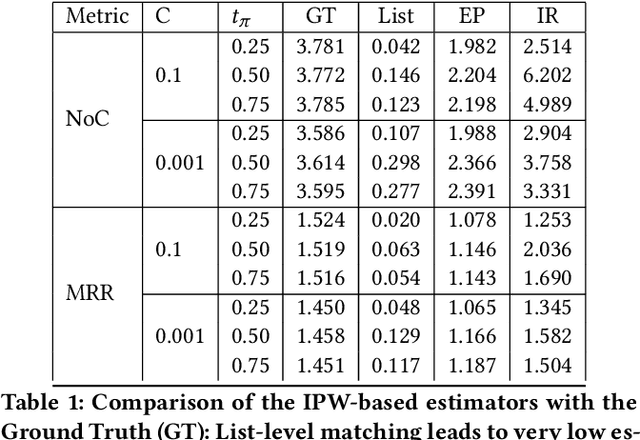

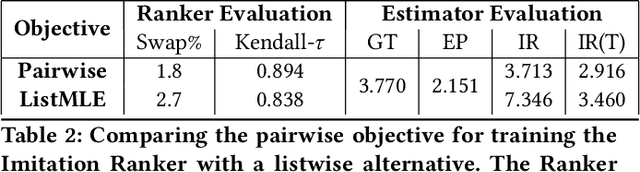
Search engines and recommendation systems attempt to continually improve the quality of the experience they afford to their users. Refining the ranker that produces the lists displayed in response to user requests is an important component of this process. A common practice is for the service providers to make changes (e.g. new ranking features, different ranking models) and A/B test them on a fraction of their users to establish the value of the change. An alternative approach estimates the effectiveness of the proposed changes offline, utilising previously collected clickthrough data on the old ranker to posit what the user behaviour on ranked lists produced by the new ranker would have been. A majority of offline evaluation approaches invoke the well studied inverse propensity weighting to adjust for biases inherent in logged data. In this paper, we propose the use of parametric estimates for these propensities. Specifically, by leveraging well known learning-to-rank methods as subroutines, we show how accurate offline evaluation can be achieved when the new rankings to be evaluated differ from the logged ones.
Off-Policy Evaluation in Embedded Spaces
Mar 05, 2022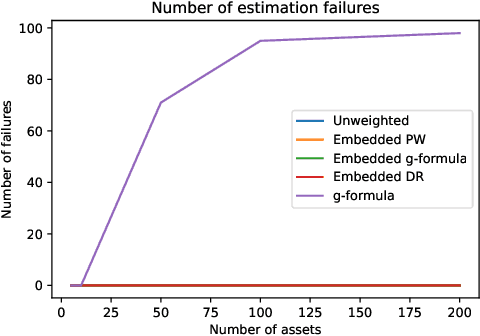
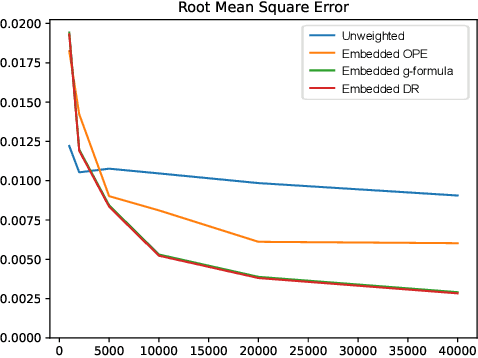
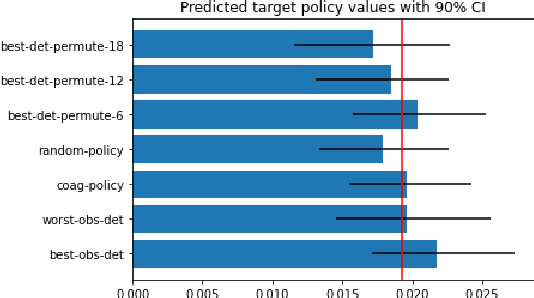
Off-policy evaluation methods are important in recommendation systems and search engines, whereby data collected under an old logging policy is used to predict the performance of a new target policy. However, in practice most systems are not observed to recommend most of the possible actions, which is an issue since existing methods require that the probability of the target policy recommending an item can only be non-zero when the probability of the logging policy is non-zero (known as absolute continuity). To circumvent this issue, we explore the use of action embeddings. By representing contexts and actions in an embedding space, we are able to share information to extrapolate behaviors for actions and contexts previously unseen.
Relational Causal Models with Cycles:Representation and Reasoning
Feb 22, 2022
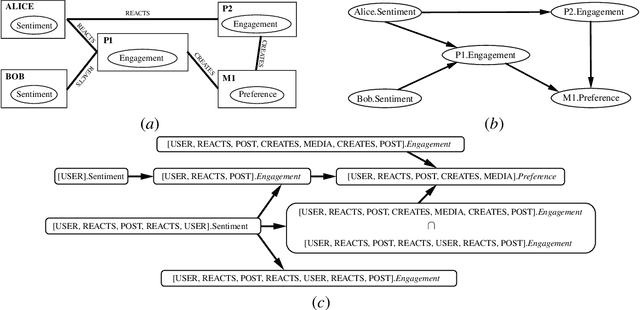

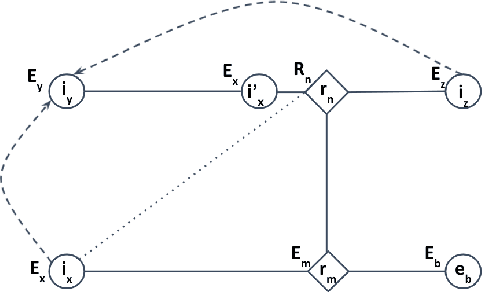
Causal reasoning in relational domains is fundamental to studying real-world social phenomena in which individual units can influence each other's traits and behavior. Dynamics between interconnected units can be represented as an instantiation of a relational causal model; however, causal reasoning over such instantiation requires additional templating assumptions that capture feedback loops of influence. Previous research has developed lifted representations to address the relational nature of such dynamics but has strictly required that the representation has no cycles. To facilitate cycles in relational representation and learning, we introduce relational $\sigma$-separation, a new criterion for understanding relational systems with feedback loops. We also introduce a new lifted representation, $\sigma$-abstract ground graph which helps with abstracting statistical independence relations in all possible instantiations of the cyclic relational model. We show the necessary and sufficient conditions for the completeness of $\sigma$-AGG and that relational $\sigma$-separation is sound and complete in the presence of one or more cycles with arbitrary length. To the best of our knowledge, this is the first work on representation of and reasoning with cyclic relational causal models.
Constraint Sampling Reinforcement Learning: Incorporating Expertise For Faster Learning
Dec 30, 2021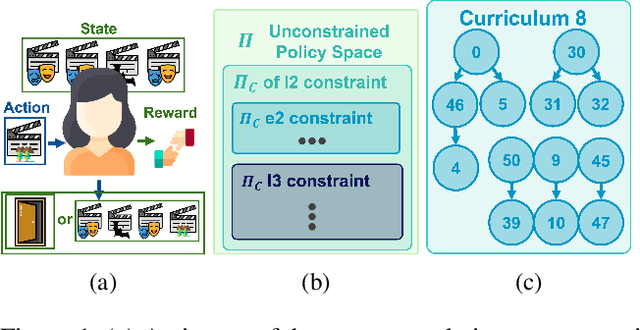
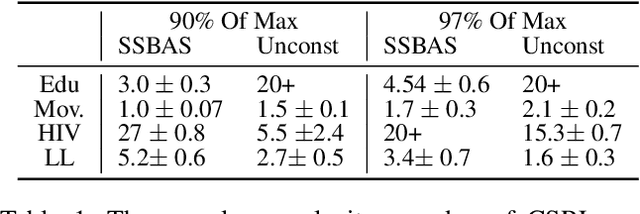
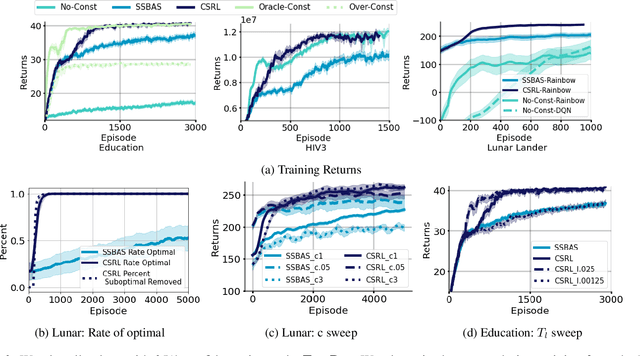
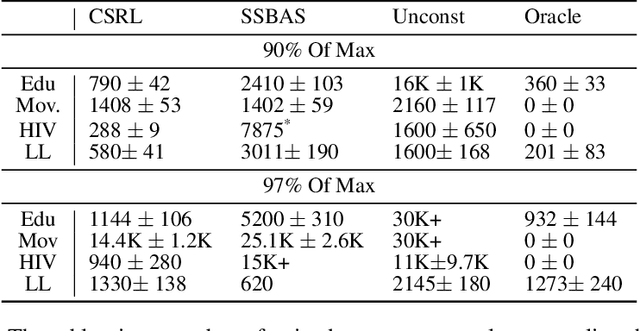
Online reinforcement learning (RL) algorithms are often difficult to deploy in complex human-facing applications as they may learn slowly and have poor early performance. To address this, we introduce a practical algorithm for incorporating human insight to speed learning. Our algorithm, Constraint Sampling Reinforcement Learning (CSRL), incorporates prior domain knowledge as constraints/restrictions on the RL policy. It takes in multiple potential policy constraints to maintain robustness to misspecification of individual constraints while leveraging helpful ones to learn quickly. Given a base RL learning algorithm (ex. UCRL, DQN, Rainbow) we propose an upper confidence with elimination scheme that leverages the relationship between the constraints, and their observed performance, to adaptively switch among them. We instantiate our algorithm with DQN-type algorithms and UCRL as base algorithms, and evaluate our algorithm in four environments, including three simulators based on real data: recommendations, educational activity sequencing, and HIV treatment sequencing. In all cases, CSRL learns a good policy faster than baselines.
Doubly robust confidence sequences for sequential causal inference
Mar 11, 2021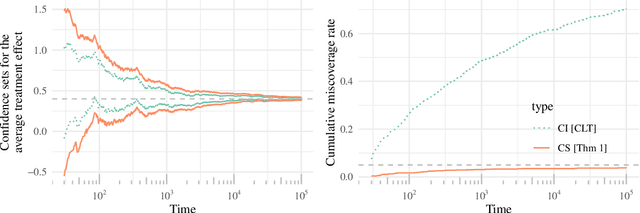
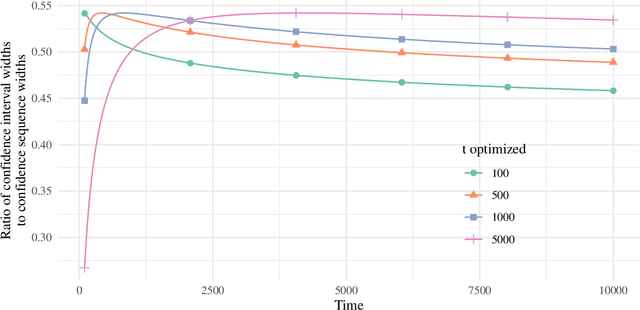
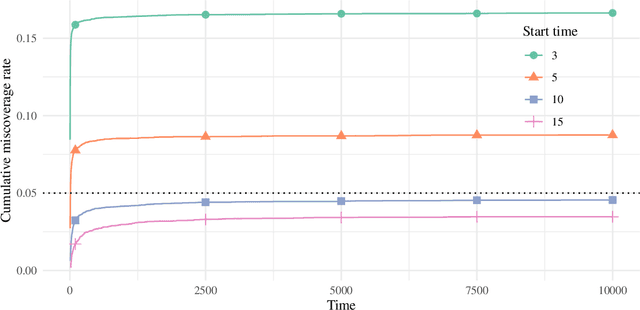
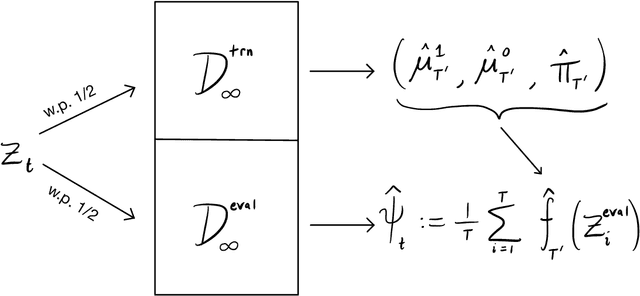
This paper derives time-uniform confidence sequences (CS) for causal effects in experimental and observational settings. A confidence sequence for a target parameter $\psi$ is a sequence of confidence intervals $(C_t)_{t=1}^\infty$ such that every one of these intervals simultaneously captures $\psi$ with high probability. Such CSs provide valid statistical inference for $\psi$ at arbitrary stopping times, unlike classical fixed-time confidence intervals which require the sample size to be fixed in advance. Existing methods for constructing CSs focus on the nonasymptotic regime where certain assumptions (such as known bounds on the random variables) are imposed, while doubly-robust estimators of causal effects rely on (asymptotic) semiparametric theory. We use sequential versions of central limit theorem arguments to construct large-sample CSs for causal estimands, with a particular focus on the average treatment effect (ATE) under nonparametric conditions. These CSs allow analysts to update statistical inferences about the ATE in lieu of new data, and experiments can be continuously monitored, stopped, or continued for any data-dependent reason, all while controlling the type-I error rate. Finally, we describe how these CSs readily extend to other causal estimands and estimators, providing a new framework for sequential causal inference in a wide array of problems.
Heterogeneous Graphlets
Oct 23, 2020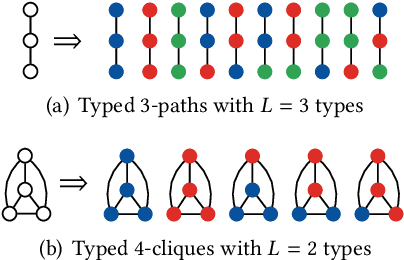


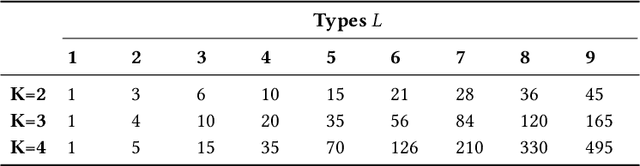
In this paper, we introduce a generalization of graphlets to heterogeneous networks called typed graphlets. Informally, typed graphlets are small typed induced subgraphs. Typed graphlets generalize graphlets to rich heterogeneous networks as they explicitly capture the higher-order typed connectivity patterns in such networks. To address this problem, we describe a general framework for counting the occurrences of such typed graphlets. The proposed algorithms leverage a number of combinatorial relationships for different typed graphlets. For each edge, we count a few typed graphlets, and with these counts along with the combinatorial relationships, we obtain the exact counts of the other typed graphlets in o(1) constant time. Notably, the worst-case time complexity of the proposed approach matches the time complexity of the best known untyped algorithm. In addition, the approach lends itself to an efficient lock-free and asynchronous parallel implementation. While there are no existing methods for typed graphlets, there has been some work that focused on computing a different and much simpler notion called colored graphlet. The experiments confirm that our proposed approach is orders of magnitude faster and more space-efficient than methods for computing the simpler notion of colored graphlet. Unlike these methods that take hours on small networks, the proposed approach takes only seconds on large networks with millions of edges. Notably, since typed graphlet is more general than colored graphlet (and untyped graphlets), the counts of various typed graphlets can be combined to obtain the counts of the much simpler notion of colored graphlets. The proposed methods give rise to new opportunities and applications for typed graphlets.
Efficient Balanced Treatment Assignments for Experimentation
Oct 21, 2020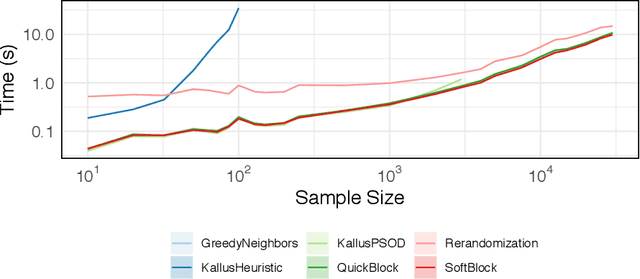
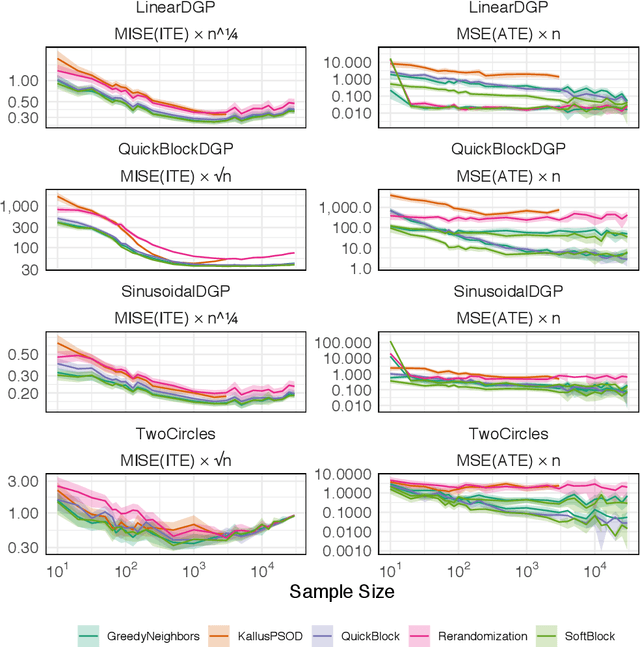
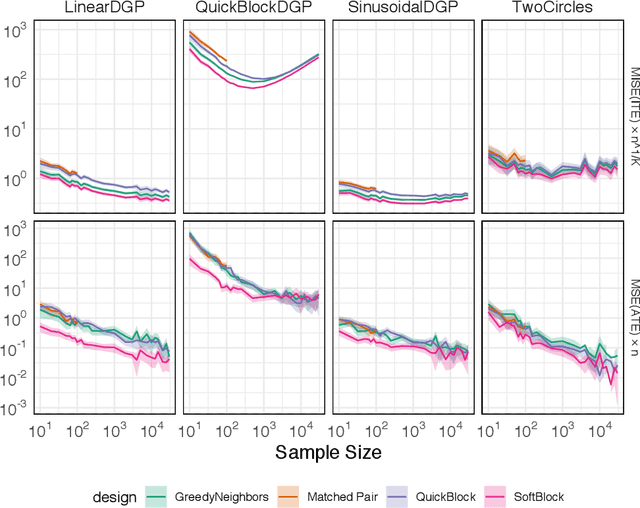
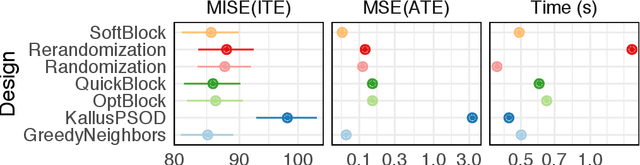
In this work, we reframe the problem of balanced treatment assignment as optimization of a two-sample test between test and control units. Using this lens we provide an assignment algorithm that is optimal with respect to the minimum spanning tree test of Friedman and Rafsky (1979). This assignment to treatment groups may be performed exactly in polynomial time. We provide a probabilistic interpretation of this process in terms of the most probable element of designs drawn from a determinantal point process which admits a probabilistic interpretation of the design. We provide a novel formulation of estimation as transductive inference and show how the tree structures used in design can also be used in an adjustment estimator. We conclude with a simulation study demonstrating the improved efficacy of our method.
Adjusting for Confounders with Text: Challenges and an Empirical Evaluation Framework for Causal Inference
Sep 21, 2020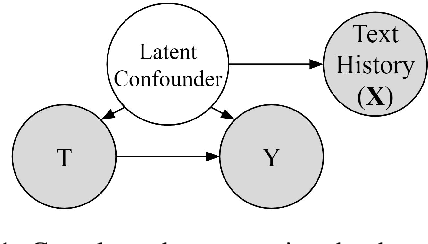
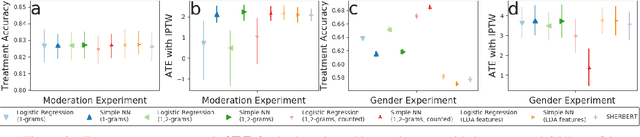
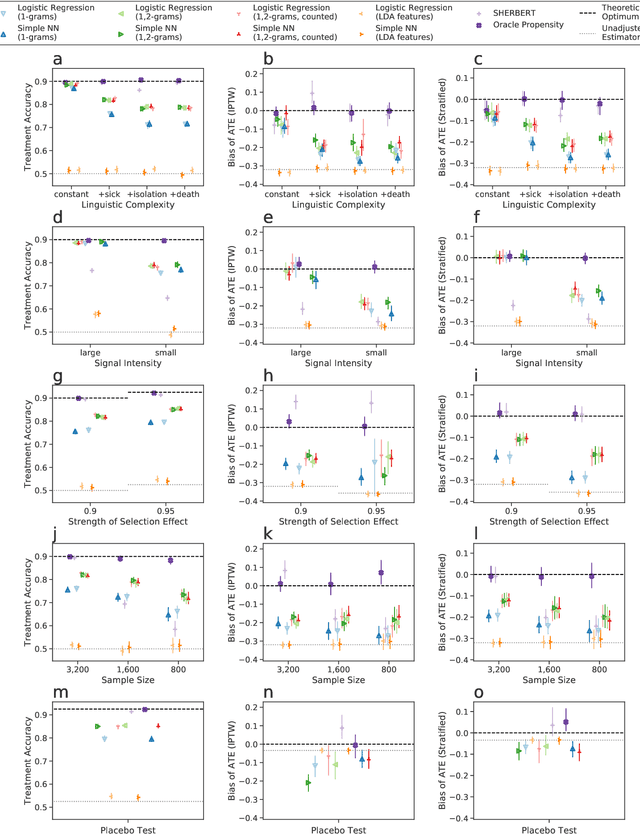
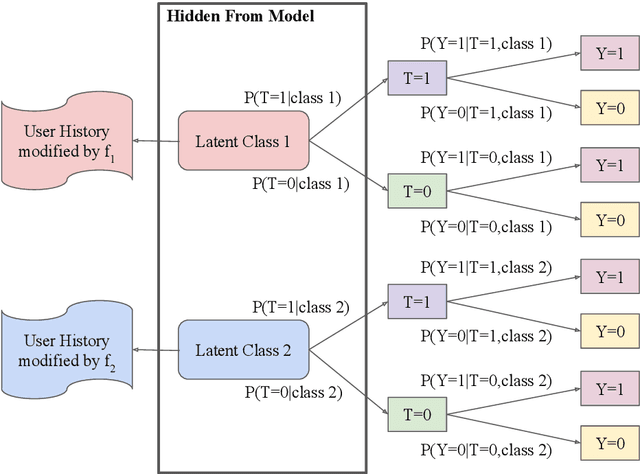
Leveraging text, such as social media posts, for causal inferences requires the use of NLP models to 'learn' and adjust for confounders, which could otherwise impart bias. However, evaluating such models is challenging, as ground truth is almost never available. We demonstrate the need for empirical evaluation frameworks for causal inference in natural language by showing that existing, commonly used models regularly disagree with one another on real world tasks. We contribute the first such framework, generalizing several challenges across these real world tasks. Using this framework, we evaluate a large set of commonly used causal inference models based on propensity scores and identify their strengths and weaknesses to inform future improvements. We make all tasks, data, and models public to inform applications and encourage additional research.
General Identification of Dynamic Treatment Regimes Under Interference
Apr 02, 2020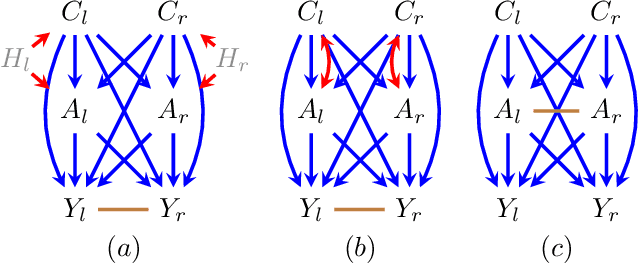
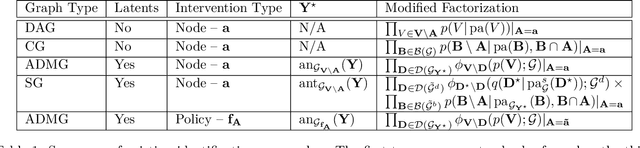

In many applied fields, researchers are often interested in tailoring treatments to unit-level characteristics in order to optimize an outcome of interest. Methods for identifying and estimating treatment policies are the subject of the dynamic treatment regime literature. Separately, in many settings the assumption that data are independent and identically distributed does not hold due to inter-subject dependence. The phenomenon where a subject's outcome is dependent on his neighbor's exposure is known as interference. These areas intersect in myriad real-world settings. In this paper we consider the problem of identifying optimal treatment policies in the presence of interference. Using a general representation of interference, via Lauritzen-Wermuth-Freydenburg chain graphs (Lauritzen and Richardson, 2002), we formalize a variety of policy interventions under interference and extend existing identification theory (Tian, 2008; Sherman and Shpitser, 2018). Finally, we illustrate the efficacy of policy maximization under interference in a simulation study.
Balanced Off-Policy Evaluation in General Action Spaces
Jun 13, 2019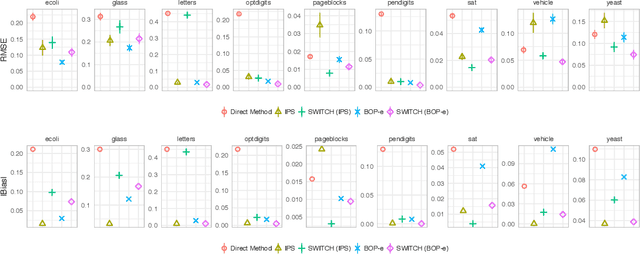

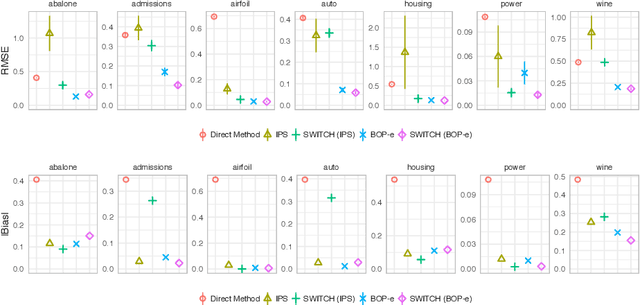
In many practical applications of contextual bandits, online learning is infeasible and practitioners must rely on off-policy evaluation (OPE) of logged data collected from prior policies. OPE generally consists of a combination of two components: (i) directly estimating a model of the reward given state and action and (ii) importance sampling. While recent work has made significant advances adaptively combining these two components, less attention has been paid to improving the quality of the importance weights themselves. In this work we present balancing off-policy evaluation (BOP-e), an importance sampling procedure that directly optimizes for balance and can be plugged into any OPE estimator that uses importance sampling. BOP-e directly estimates the importance sampling ratio via a classifier which attempts to distinguish state-action pairs from an observed versus a proposed policy. BOP-e can be applied to continuous, mixed, and multi-valued action spaces without modification and is easily scalable to many observations. Further, we show that minimization of regret in the constructed binary classification problem translates directly into minimizing regret in the off-policy evaluation task. Finally, we provide experimental evidence that BOP-e outperforms inverse propensity weighting-based approaches for offline evaluation of policies in the contextual bandit setting under both discrete and continuous action spaces.