 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unified Control Framework: Establishing a Common Foundation for Enterprise AI Governance, Risk Management and Regulatory Compliance
Mar 07, 2025



The rapid adoption of AI systems presents enterprises with a dual challenge: accelerating innovation while ensuring responsible governance. Current AI governance approaches suffer from fragmentation, with risk management frameworks that focus on isolated domains, regulations that vary across jurisdictions despite conceptual alignment, and high-level standards lacking concrete implementation guidance. This fragmentation increases governance costs and creates a false dichotomy between innovation and responsibility. We propose the Unified Control Framework (UCF): a comprehensive governance approach that integrates risk management and regulatory compliance through a unified set of controls. The UCF consists of three key components: (1) a comprehensive risk taxonomy synthesizing organizational and societal risks, (2) structured policy requirements derived from regulations, and (3) a parsimonious set of 42 controls that simultaneously address multiple risk scenarios and compliance requirements. We validate the UCF by mapping it to the Colorado AI Act, demonstrating how our approach enables efficient, adaptable governance that scales across regulations while providing concrete implementation guidance. The UCF reduces duplication of effort, ensures comprehensive coverage, and provides a foundation for automation, enabling organizations to achieve responsible AI governance without sacrificing innovation speed.
AI Risk Profiles: A Standards Proposal for Pre-Deployment AI Risk Disclosures
Sep 22, 2023As AI systems' sophistication and proliferation have increased, awareness of the risks has grown proportionally (Sorkin et al. 2023). In response, calls have grown for stronger emphasis on disclosure and transparency in the AI industry (NTIA 2023; OpenAI 2023b), with proposals ranging from standardizing use of technical disclosures, like model cards (Mitchell et al. 2019), to yet-unspecified licensing regimes (Sindhu 2023). Since the AI value chain is complicated, with actors representing various expertise, perspectives, and values, it is crucial that consumers of a transparency disclosure be able to understand the risks of the AI system the disclosure concerns. In this paper we propose a risk profiling standard which can guide downstream decision-making, including triaging further risk assessment, informing procurement and deployment, and directing regulatory frameworks. The standard is built on our proposed taxonomy of AI risks, which reflects a high-level categorization of the wide variety of risks proposed in the literature. We outline the myriad data sources needed to construct informative Risk Profiles and propose a template-based methodology for collating risk information into a standard, yet flexible, structure. We apply this methodology to a number of prominent AI systems using publicly available information. To conclude, we discuss design decisions for the profiles and future work.
General Identification of Dynamic Treatment Regimes Under Interference
Apr 02, 2020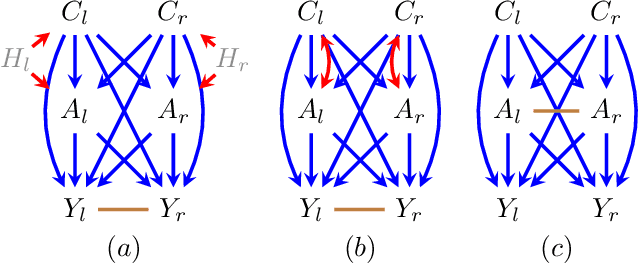

In many applied fields, researchers are often interested in tailoring treatments to unit-level characteristics in order to optimize an outcome of interest. Methods for identifying and estimating treatment policies are the subject of the dynamic treatment regime literature. Separately, in many settings the assumption that data are independent and identically distributed does not hold due to inter-subject dependence. The phenomenon where a subject's outcome is dependent on his neighbor's exposure is known as interference. These areas intersect in myriad real-world settings. In this paper we consider the problem of identifying optimal treatment policies in the presence of interference. Using a general representation of interference, via Lauritzen-Wermuth-Freydenburg chain graphs (Lauritzen and Richardson, 2002), we formalize a variety of policy interventions under interference and extend existing identification theory (Tian, 2008; Sherman and Shpitser, 2018). Finally, we illustrate the efficacy of policy maximization under interference in a simulation study.
Leveraging Clinical Time-Series Data for Prediction: A Cautionary Tale
Nov 29, 2018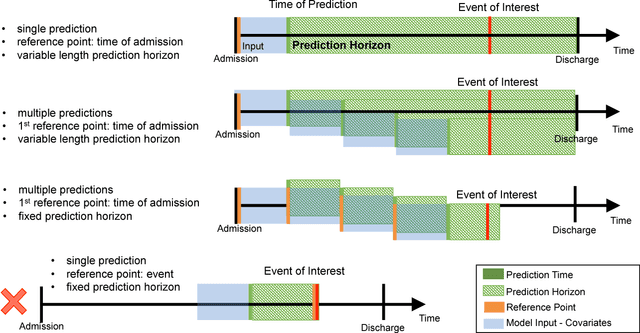
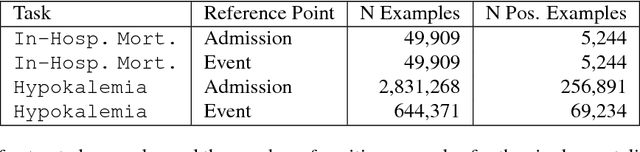
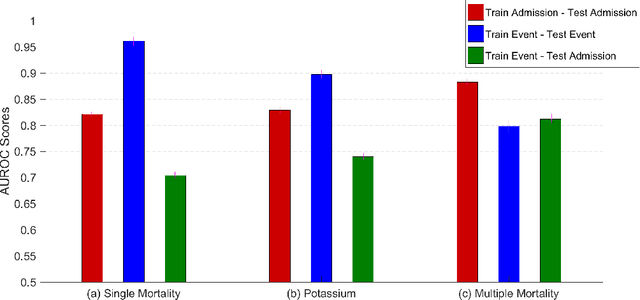

In healthcare, patient risk stratification models are often learned using time-series data extracted from electronic health records. When extracting data for a clinical prediction task, several formulations exist, depending on how one chooses the time of prediction and the prediction horizon. In this paper, we show how the formulation can greatly impact both model performance and clinical utility. Leveraging a publicly available ICU dataset, we consider two clinical prediction tasks: in-hospital mortality, and hypokalemia. Through these case studies, we demonstrate the necessity of evaluating models using an outcome-independent reference point, since choosing the time of prediction relative to the event can result in unrealistic performance. Further, an outcome-independent scheme outperforms an outcome-dependent scheme on both tasks (In-Hospital Mortality AUROC .882 vs. .831; Serum Potassium: AUROC .829 vs. .740) when evaluated on test sets that mimic real-world use.
* In Proceedings of American Medical Informatics Annual Symposium 2017 PMID: 29854227