 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComMer: a Framework for Compressing and Merging User Data for Personalization
Jan 05, 2025Large Language Models (LLMs) excel at a wide range of tasks, but adapting them to new data, particularly for personalized applications, poses significant challenges due to resource and computational constraints. Existing methods either rely on exposing fresh data to the model through the prompt, which is limited by context size and computationally expensive at inference time, or fine-tuning, which incurs substantial training and update costs. In this paper, we introduce ComMer - Compress and Merge - a novel framework that efficiently personalizes LLMs by compressing users' documents into compact representations, which are then merged and fed into a frozen LLM. We evaluate ComMer on two types of personalization tasks - personalized skill learning, using the tweet paraphrasing dataset and the personalized news headline generation dataset from the LaMP benchmark, and knowledge-intensive, using the PerLTQA dataset. Our experiments demonstrate that in constrained inference budget scenarios ComMer achieves superior quality in skill learning tasks, while highlighting limitations in knowledge-intensive settings due to the loss of detailed information. These results offer insights into trade-offs and potential optimizations in multi-document compression for personalization.
Evidence of Cognitive Deficits andDevelopmental Advances in Generative AI: A Clock Drawing Test Analysis
Oct 15, 2024

Generative AI's rapid advancement sparks interest in its cognitive abilities, especially given its capacity for tasks like language understanding and code generation. This study explores how several recent GenAI models perform on the Clock Drawing Test (CDT), a neuropsychological assessment of visuospatial planning and organization. While models create clock-like drawings, they struggle with accurate time representation, showing deficits similar to mild-severe cognitive impairment (Wechsler, 2009). Errors include numerical sequencing issues, incorrect clock times, and irrelevant additions, despite accurate rendering of clock features. Only GPT 4 Turbo and Gemini Pro 1.5 produced the correct time, scoring like healthy individuals (4/4). A follow-up clock-reading test revealed only Sonnet 3.5 succeeded, suggesting drawing deficits stem from difficulty with numerical concepts. These findings may reflect weaknesses in visual-spatial understanding, working memory, or calculation, highlighting strengths in learned knowledge but weaknesses in reasoning. Comparing human and machine performance is crucial for understanding AI's cognitive capabilities and guiding development toward human-like cognitive functions.
The Cognitive Capabilities of Generative AI: A Comparative Analysis with Human Benchmarks
Oct 09, 2024



There is increasing interest in tracking the capabilities of general intelligence foundation models. This study benchmarks leading large language models and vision language models against human performance on the Wechsler Adult Intelligence Scale (WAIS-IV), a comprehensive, population-normed assessment of underlying human cognition and intellectual abilities, with a focus on the domains of VerbalComprehension (VCI), Working Memory (WMI), and Perceptual Reasoning (PRI). Most models demonstrated exceptional capabilities in the storage, retrieval, and manipulation of tokens such as arbitrary sequences of letters and numbers, with performance on the Working Memory Index (WMI) greater or equal to the 99.5th percentile when compared to human population normative ability. Performance on the Verbal Comprehension Index (VCI) which measures retrieval of acquired information, and linguistic understanding about the meaning of words and their relationships to each other, also demonstrated consistent performance at or above the 98th percentile. Despite these broad strengths, we observed consistently poor performance on the Perceptual Reasoning Index (PRI; range 0.1-10th percentile) from multimodal models indicating profound inability to interpret and reason on visual information. Smaller and older model versions consistently performed worse, indicating that training data, parameter count and advances in tuning are resulting in significant advances in cognitive ability.
The Ability of Large Language Models to Evaluate Constraint-satisfaction in Agent Responses to Open-ended Requests
Sep 22, 2024Generative AI agents are often expected to respond to complex user requests that have No One Right Answer (NORA), e.g., "design a vegetarian meal plan below 1800 calories". Such requests may entail a set of constraints that the agent should adhere to. To successfully develop agents for NORA scenarios, an accurate automatic evaluation framework is essential, and specifically - one capable of validating the satisfaction of constraints in the agent's response. Recently, large language models (LLMs) have been adopted as versatile evaluators for many NORA tasks, but their ability to evaluate constraint-satisfaction in generated text remains unclear. To study this, we develop and release a novel Arithmetic Constraint-Satisfaction (ACS) benchmarking dataset. The dataset consists of complex user requests with corresponding constraints, agent responses and human labels indicating each constraint's satisfaction level in the response. A unique property of this dataset is that validating many of its constraints requires reviewing the response as a whole (in contrast to many other benchmarks that require the validation of a single independent item). Moreover, it assesses LLMs in performing reasoning, in-context data extraction, arithmetic calculations, and counting. We then benchmark both open and proprietary LLMs on evaluating constraint-satisfaction, and show that most models still have a significant headroom for improvement, and that errors primarily stem from reasoning issues. In addition, most models exhibit a skewed constraint-satisfaction prediction pattern, with higher accuracy where the ground-truth label is "satisfied". Lastly, few-shot prompting for our task proved to be rather challenging, since many of the studied models showed a degradation in performance when it was introduced.
Generative agent-based modeling with actions grounded in physical, social, or digital space using Concordia
Dec 13, 2023



Agent-based modeling has been around for decades, and applied widely across the social and natural sciences. The scope of this research method is now poised to grow dramatically as it absorbs the new affordances provided by Large Language Models (LLM)s. Generative Agent-Based Models (GABM) are not just classic Agent-Based Models (ABM)s where the agents talk to one another. Rather, GABMs are constructed using an LLM to apply common sense to situations, act "reasonably", recall common semantic knowledge, produce API calls to control digital technologies like apps, and communicate both within the simulation and to researchers viewing it from the outside. Here we present Concordia, a library to facilitate constructing and working with GABMs. Concordia makes it easy to construct language-mediated simulations of physically- or digitally-grounded environments. Concordia agents produce their behavior using a flexible component system which mediates between two fundamental operations: LLM calls and associative memory retrieval. A special agent called the Game Master (GM), which was inspired by tabletop role-playing games, is responsible for simulating the environment where the agents interact. Agents take actions by describing what they want to do in natural language. The GM then translates their actions into appropriate implementations. In a simulated physical world, the GM checks the physical plausibility of agent actions and describes their effects. In digital environments simulating technologies such as apps and services, the GM may handle API calls to integrate with external tools such as general AI assistants (e.g., Bard, ChatGPT), and digital apps (e.g., Calendar, Email, Search, etc.). Concordia was designed to support a wide array of applications both in scientific research and for evaluating performance of real digital services by simulating users and/or generating synthetic data.
Federated Multilingual Models for Medical Transcript Analysis
Nov 04, 2022Federated Learning (FL) is a novel machine learning approach that allows the model trainer to access more data samples, by training the model across multiple decentralized data sources, while data access constraints are in place. Such trained models can achieve significantly higher performance beyond what can be done when trained on a single data source. As part of FL's promises, none of the training data is ever transmitted to any central location, ensuring that sensitive data remains local and private. These characteristics make FL perfectly suited for large-scale applications in healthcare, where a variety of compliance constraints restrict how data may be handled, processed, and stored. Despite the apparent benefits of federated learning, the heterogeneity in the local data distributions pose significant challenges, and such challenges are even more pronounced in the case of multilingual data providers. In this paper we present a federated learning system for training a large-scale multi-lingual model suitable for fine-tuning on downstream tasks such as medical entity tagging. Our work represents one of the first such production-scale systems, capable of training across multiple highly heterogeneous data providers, and achieving levels of accuracy that could not be otherwise achieved by using central training with public data. Finally, we show that the global model performance can be further improved by a training step performed locally.
Algorithmic Rewriting of Health-Related Ads to Improve their Performance
Nov 03, 2019
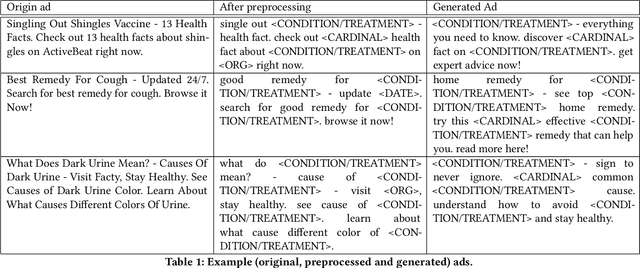
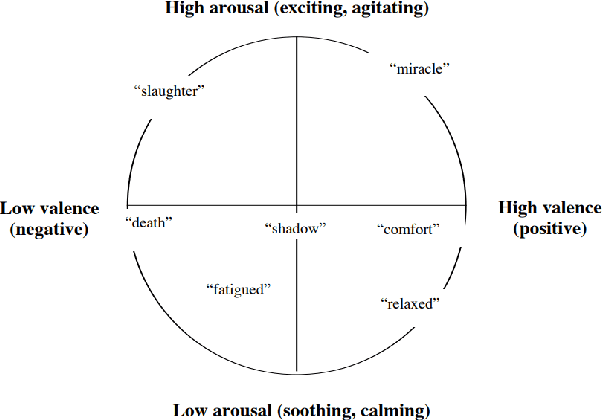
Search advertising is one of the most commonly-used methods of advertising. Past work has shown that search advertising can be employed to improve health by eliciting positive behavioral change. However, writing effective advertisements requires expertise and (possible expensive) experimentation, both of which may not be available to public health authorities wishing to elicit such behavioral changes, especially when dealing with a public health crises such as epidemic outbreaks. Here we develop an algorithm which builds on past advertising data to train a sequence-to-sequence Deep Neural Network which "translates" advertisements into optimized ads that are more likely to be clicked. The network is trained using more than 114 thousands ads shown on Microsoft Advertising. We apply this translator to two health related domains: Medical Symptoms (MS) and Preventative Healthcare (PH) and measure the improvements in click-through rates (CTR). Our experiments show that the generated ads are predicted to have higher CTR in 81% of MS ads and 76% of PH ads. To understand the differences between the generated ads and the original ones we develop estimators for the affective attributes of the ads. We show that the generated ads contain more calls-to-action and that they reflect higher valence (36% increase) and higher arousal (87%) on a sample of 1000 ads. Finally, we run an advertising campaign where 10 random ads and their rephrased versions from each of the domains are run in parallel. We show an average improvement in CTR of 68% for the generated ads compared to the original ads. Our results demonstrate the ability to automatically optimize advertisement for the health domain. We believe that our work offers health authorities an improved ability to help nudge people towards healthier behaviors while saving the time and cost needed to optimize advertising campaigns.
LaVAN: Localized and Visible Adversarial Noise
Mar 01, 2018
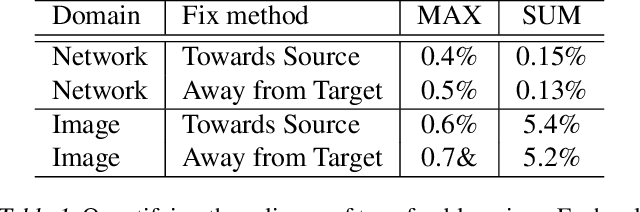


Most works on adversarial examples for deep-learning based image classifiers use noise that, while small, covers the entire image. We explore the case where the noise is allowed to be visible but confined to a small, localized patch of the image, without covering any of the main object(s) in the image. We show that it is possible to generate localized adversarial noises that cover only 2% of the pixels in the image, none of them over the main object, and that are transferable across images and locations, and successfully fool a state-of-the-art Inception v3 model with very high success rates.
Risk Minimization in Structured Prediction using Orbit Loss
Dec 09, 2015
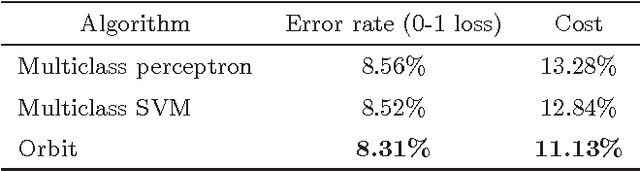
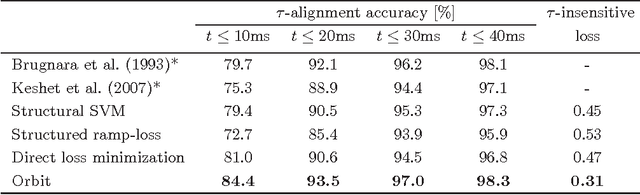
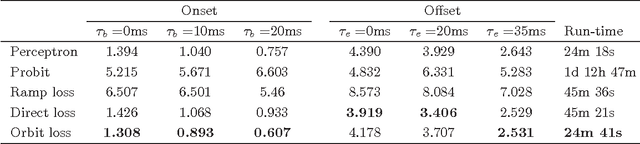
We introduce a new surrogate loss function called orbit loss in the structured prediction framework, which has good theoretical and practical advantages. While the orbit loss is not convex, it has a simple analytical gradient and a simple perceptron-like learning rule. We analyze the new loss theoretically and state a PAC-Bayesian generalization bound. We also prove that the new loss is consistent in the strong sense; namely, the risk achieved by the set of the trained parameters approaches the infimum risk achievable by any linear decoder over the given features. Methods that are aimed at risk minimization, such as the structured ramp loss, the structured probit loss and the direct loss minimization require at least two inference operations per training iteration. In this sense, the orbit loss is more efficient as it requires only one inference operation per training iteration, while yields similar performance. We conclude the paper with an empirical comparison of the proposed loss function to the structured hinge loss, the structured ramp loss, the structured probit loss and the direct loss minimization method on several benchmark datasets and tasks.