 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models for Health-related Queries with Presuppositions
Dec 14, 2023



As corporations rush to integrate large language models (LLMs) to their search offerings, it is critical that they provide factually accurate information that is robust to any presuppositions that a user may express. In this work, we introduce UPHILL, a dataset consisting of health-related queries with varying degrees of presuppositions. Using UPHILL, we evaluate the factual accuracy and consistency of InstructGPT, ChatGPT, and BingChat models. We find that while model responses rarely disagree with true health claims (posed as questions), they often fail to challenge false claims: responses from InstructGPT agree with 32% of the false claims, ChatGPT 26% and BingChat 23%. As we increase the extent of presupposition in input queries, the responses from InstructGPT and ChatGPT agree with the claim considerably more often, regardless of its veracity. Responses from BingChat, which rely on retrieved webpages, are not as susceptible. Given the moderate factual accuracy, and the inability of models to consistently correct false assumptions, our work calls for a careful assessment of current LLMs for use in high-stakes scenarios.
Performance Trade-offs of Watermarking Large Language Models
Nov 16, 2023Amidst growing concerns of large language models (LLMs) being misused for generating misinformation or completing homework assignments, watermarking has emerged as an effective solution for distinguishing human-written and LLM-generated text. A prominent watermarking strategy is to embed a signal into generated text by upsampling a (pseudorandomly-chosen) subset of tokens at every generation step. Although this signal is imperceptible to a human reader, it is detectable through statistical testing. However, implanting such signals alters the model's output distribution and can have unintended effects when watermarked LLMs are used for downstream applications. In this work, we evaluate the performance of watermarked LLMs on a diverse suite of tasks, including text classification, textual entailment, reasoning, question answering, translation, summarization, and language modeling. We find that watermarking has negligible impact on the performance of tasks posed as k-class classification problems in the average case. However, the accuracy can plummet to that of a random classifier for some scenarios (that occur with non-negligible probability). Tasks that are cast as multiple-choice questions and short-form generation are surprisingly unaffected by watermarking. For long-form generation tasks, including summarization and translation, we see a drop of 15-20% in the performance due to watermarking. Our findings highlight the trade-offs that users should be cognizant of when using watermarked models, and point to cases where future research could improve existing trade-offs.
Geographical Erasure in Language Generation
Oct 23, 2023



Large language models (LLMs) encode vast amounts of world knowledge. However, since these models are trained on large swaths of internet data, they are at risk of inordinately capturing information about dominant groups. This imbalance can propagate into generated language. In this work, we study and operationalise a form of geographical erasure, wherein language models underpredict certain countries. We demonstrate consistent instances of erasure across a range of LLMs. We discover that erasure strongly correlates with low frequencies of country mentions in the training corpus. Lastly, we mitigate erasure by finetuning using a custom objective.
Goodhart's Law Applies to NLP's Explanation Benchmarks
Aug 28, 2023



Despite the rising popularity of saliency-based explanations, the research community remains at an impasse, facing doubts concerning their purpose, efficacy, and tendency to contradict each other. Seeking to unite the community's efforts around common goals, several recent works have proposed evaluation metrics. In this paper, we critically examine two sets of metrics: the ERASER metrics (comprehensiveness and sufficiency) and the EVAL-X metrics, focusing our inquiry on natural language processing. First, we show that we can inflate a model's comprehensiveness and sufficiency scores dramatically without altering its predictions or explanations on in-distribution test inputs. Our strategy exploits the tendency for extracted explanations and their complements to be "out-of-support" relative to each other and in-distribution inputs. Next, we demonstrate that the EVAL-X metrics can be inflated arbitrarily by a simple method that encodes the label, even though EVAL-X is precisely motivated to address such exploits. Our results raise doubts about the ability of current metrics to guide explainability research, underscoring the need for a broader reassessment of what precisely these metrics are intended to capture.
Inspecting the Geographical Representativeness of Images from Text-to-Image Models
May 18, 2023



Recent progress in generative models has resulted in models that produce both realistic as well as relevant images for most textual inputs. These models are being used to generate millions of images everyday, and hold the potential to drastically impact areas such as generative art, digital marketing and data augmentation. Given their outsized impact, it is important to ensure that the generated content reflects the artifacts and surroundings across the globe, rather than over-representing certain parts of the world. In this paper, we measure the geographical representativeness of common nouns (e.g., a house) generated through DALL.E 2 and Stable Diffusion models using a crowdsourced study comprising 540 participants across 27 countries. For deliberately underspecified inputs without country names, the generated images most reflect the surroundings of the United States followed by India, and the top generations rarely reflect surroundings from all other countries (average score less than 3 out of 5). Specifying the country names in the input increases the representativeness by 1.44 points on average for DALL.E 2 and 0.75 for Stable Diffusion, however, the overall scores for many countries still remain low, highlighting the need for future models to be more geographically inclusive. Lastly, we examine the feasibility of quantifying the geographical representativeness of generated images without conducting user studies.
Model-tuning Via Prompts Makes NLP Models Adversarially Robust
Mar 13, 2023In recent years, NLP practitioners have converged on the following practice: (i) import an off-the-shelf pretrained (masked) language model; (ii) append a multilayer perceptron atop the CLS token's hidden representation (with randomly initialized weights); and (iii) fine-tune the entire model on a downstream task (MLP). This procedure has produced massive gains on standard NLP benchmarks, but these models remain brittle, even to mild adversarial perturbations, such as word-level synonym substitutions. In this work, we demonstrate surprising gains in adversarial robustness enjoyed by Model-tuning Via Prompts (MVP), an alternative method of adapting to downstream tasks. Rather than modifying the model (by appending an MLP head), MVP instead modifies the input (by appending a prompt template). Across three classification datasets, MVP improves performance against adversarial word-level synonym substitutions by an average of 8% over standard methods and even outperforms adversarial training-based state-of-art defenses by 3.5%. By combining MVP with adversarial training, we achieve further improvements in robust accuracy while maintaining clean accuracy. Finally, we conduct ablations to investigate the mechanism underlying these gains. Notably, we find that the main causes of vulnerability of MLP can be attributed to the misalignment between pre-training and fine-tuning tasks, and the randomly initialized MLP parameters. Code is available at https://github.com/acmi-lab/mvp
Learning the Legibility of Visual Text Perturbations
Mar 10, 2023Many adversarial attacks in NLP perturb inputs to produce visually similar strings ('ergo' $\rightarrow$ '$\epsilon$rgo') which are legible to humans but degrade model performance. Although preserving legibility is a necessary condition for text perturbation, little work has been done to systematically characterize it; instead, legibility is typically loosely enforced via intuitions around the nature and extent of perturbations. Particularly, it is unclear to what extent can inputs be perturbed while preserving legibility, or how to quantify the legibility of a perturbed string. In this work, we address this gap by learning models that predict the legibility of a perturbed string, and rank candidate perturbations based on their legibility. To do so, we collect and release LEGIT, a human-annotated dataset comprising the legibility of visually perturbed text. Using this dataset, we build both text- and vision-based models which achieve up to $0.91$ F1 score in predicting whether an input is legible, and an accuracy of $0.86$ in predicting which of two given perturbations is more legible. Additionally, we discover that legible perturbations from the LEGIT dataset are more effective at lowering the performance of NLP models than best-known attack strategies, suggesting that current models may be vulnerable to a broad range of perturbations beyond what is captured by existing visual attacks. Data, code, and models are available at https://github.com/dvsth/learning-legibility-2023.
Assisting Human Decisions in Document Matching
Feb 16, 2023



Many practical applications, ranging from paper-reviewer assignment in peer review to job-applicant matching for hiring, require human decision makers to identify relevant matches by combining their expertise with predictions from machine learning models. In many such model-assisted document matching tasks, the decision makers have stressed the need for assistive information about the model outputs (or the data) to facilitate their decisions. In this paper, we devise a proxy matching task that allows us to evaluate which kinds of assistive information improve decision makers' performance (in terms of accuracy and time). Through a crowdsourced (N=271 participants) study, we find that providing black-box model explanations reduces users' accuracy on the matching task, contrary to the commonly-held belief that they can be helpful by allowing better understanding of the model. On the other hand, custom methods that are designed to closely attend to some task-specific desiderata are found to be effective in improving user performance. Surprisingly, we also find that the users' perceived utility of assistive information is misaligned with their objective utility (measured through their task performance).
Measures of Information Reflect Memorization Patterns
Oct 19, 2022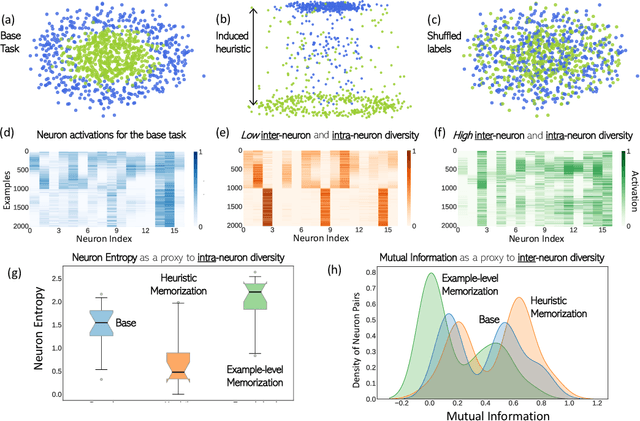
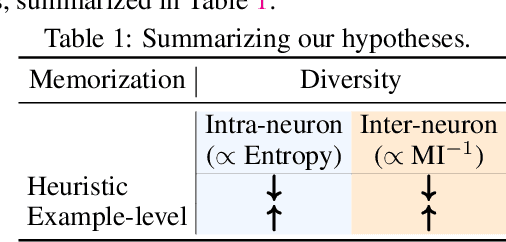
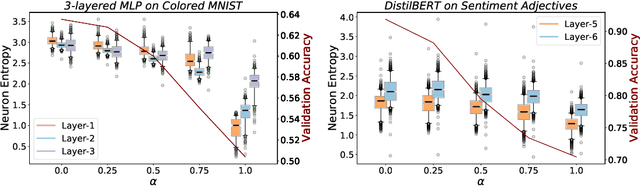
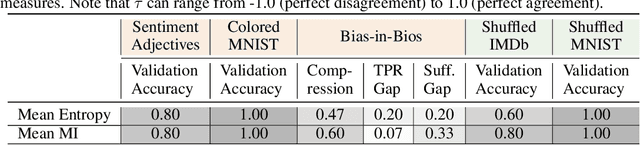
Neural networks are known to exploit spurious artifacts (or shortcuts) that co-occur with a target label, exhibiting heuristic memorization. On the other hand, networks have been shown to memorize training examples, resulting in example-level memorization. These kinds of memorization impede generalization of networks beyond their training distributions. Detecting such memorization could be challenging, often requiring researchers to curate tailored test sets. In this work, we hypothesize -- and subsequently show -- that the diversity in the activation patterns of different neurons is reflective of model generalization and memorization. We quantify the diversity in the neural activations through information-theoretic measures and find support for our hypothesis on experiments spanning several natural language and vision tasks. Importantly, we discover that information organization points to the two forms of memorization, even for neural activations computed on unlabeled in-distribution examples. Lastly, we demonstrate the utility of our findings for the problem of model selection. The associated code and other resources for this work are available at https://linktr.ee/InformationMeasures .
Learning to Scaffold: Optimizing Model Explanations for Teaching
Apr 22, 2022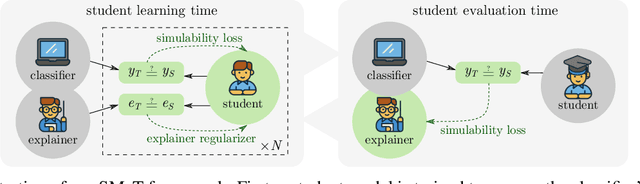
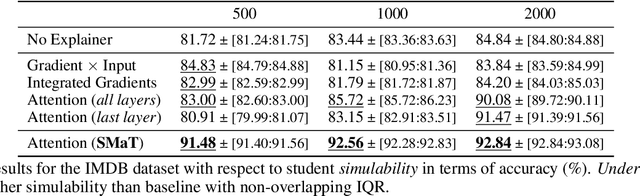
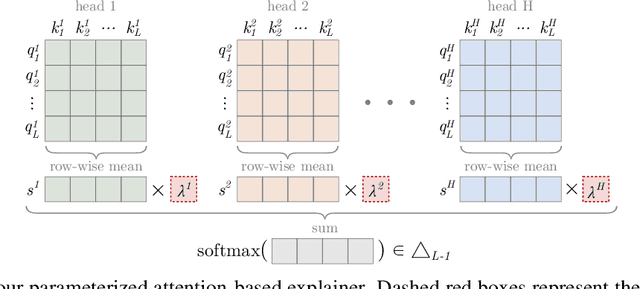

Modern machine learning models are opaque, and as a result there is a burgeoning academic subfield on methods that explain these models' behavior. However, what is the precise goal of providing such explanations, and how can we demonstrate that explanations achieve this goal? Some research argues that explanations should help teach a student (either human or machine) to simulate the model being explained, and that the quality of explanations can be measured by the simulation accuracy of students on unexplained examples. In this work, leveraging meta-learning techniques, we extend this idea to improve the quality of the explanations themselves, specifically by optimizing explanations such that student models more effectively learn to simulate the original model. We train models on three natural language processing and computer vision tasks, and find that students trained with explanations extracted with our framework are able to simulate the teacher significantly more effectively than ones produced with previous methods. Through human annotations and a user study, we further find that these learned explanations more closely align with how humans would explain the required decisions in these tasks. Our code is available at https://github.com/coderpat/learning-scaffold