 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerpreT: A Probabilistic Programming Language for Program Induction
Aug 15, 2016
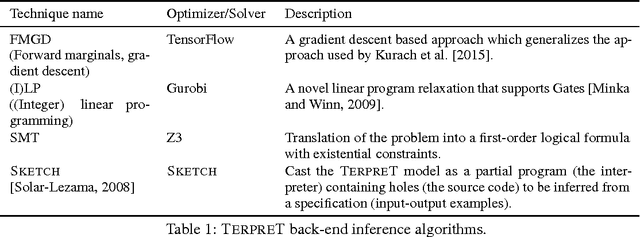
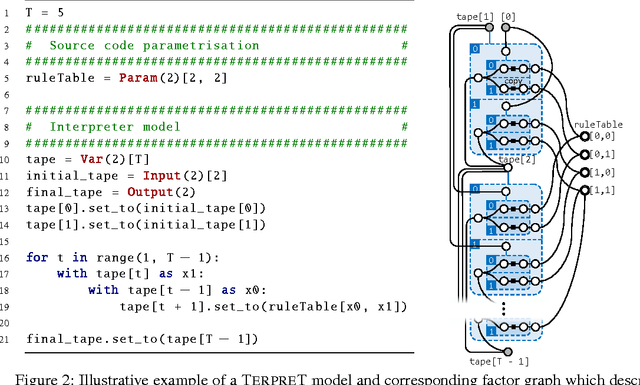
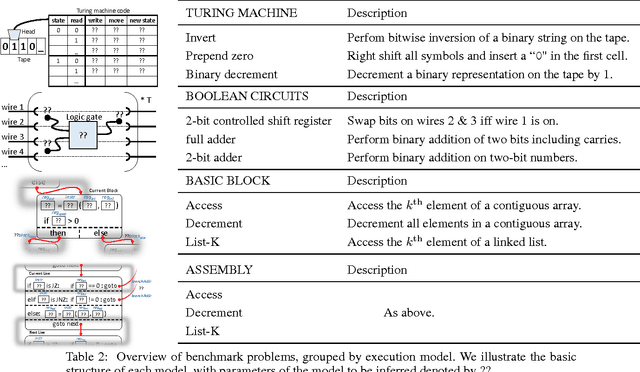
We study machine learning formulations of inductive program synthesis; given input-output examples, we try to synthesize source code that maps inputs to corresponding outputs. Our aims are to develop new machine learning approaches based on neural networks and graphical models, and to understand the capabilities of machine learning techniques relative to traditional alternatives, such as those based on constraint solving from the programming languages community. Our key contribution is the proposal of TerpreT, a domain-specific language for expressing program synthesis problems. TerpreT is similar to a probabilistic programming language: a model is composed of a specification of a program representation (declarations of random variables) and an interpreter describing how programs map inputs to outputs (a model connecting unknowns to observations). The inference task is to observe a set of input-output examples and infer the underlying program. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing like-to-like comparisons between different approaches to inference. From a single TerpreT specification we automatically perform inference using four different back-ends. These are based on gradient descent, linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. We illustrate the value of TerpreT by developing several interpreter models and performing an empirical comparison between alternative inference algorithms. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations. We conclude with suggestions for the machine learning community to make progress on program synthesis.
Consensus Message Passing for Layered Graphical Models
Jan 26, 2015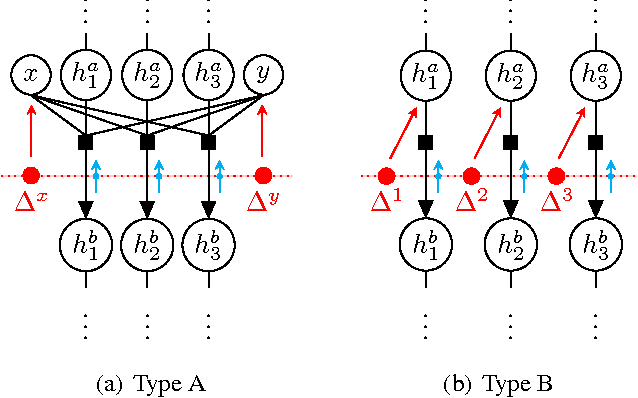
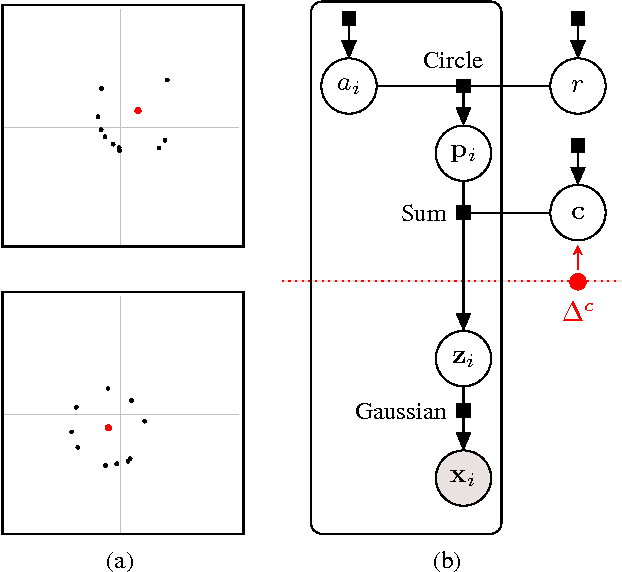
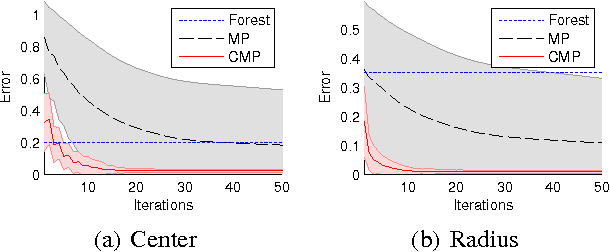
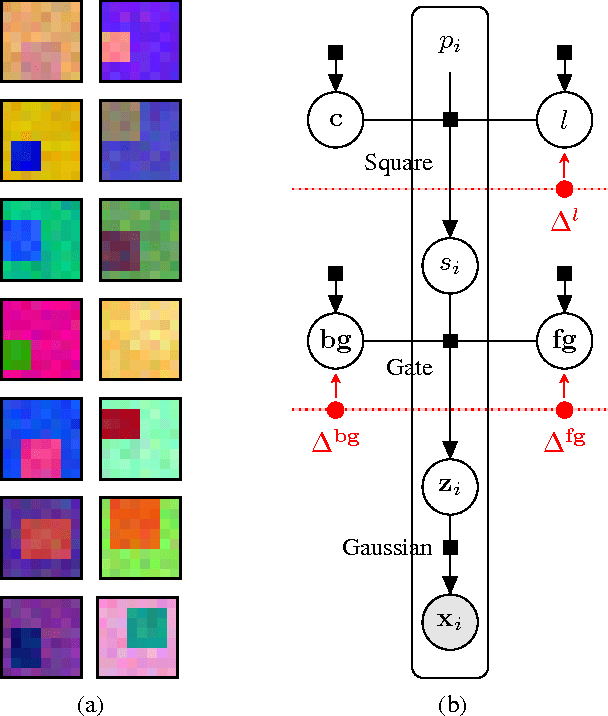
Generative models provide a powerful framework for probabilistic reasoning. However, in many domains their use has been hampered by the practical difficulties of inference. This is particularly the case in computer vision, where models of the imaging process tend to be large, loopy and layered. For this reason bottom-up conditional models have traditionally dominated in such domains. We find that widely-used, general-purpose message passing inference algorithms such as Expectation Propagation (EP) and Variational Message Passing (VMP) fail on the simplest of vision models. With these models in mind, we introduce a modification to message passing that learns to exploit their layered structure by passing 'consensus' messages that guide inference towards good solutions. Experiments on a variety of problems show that the proposed technique leads to significantly more accurate inference results, not only when compared to standard EP and VMP, but also when compared to competitive bottom-up conditional models.
A* Sampling
Jan 26, 2015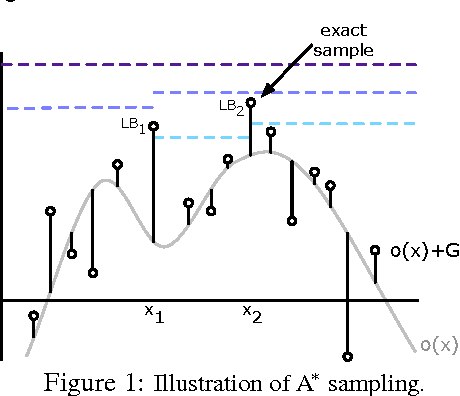
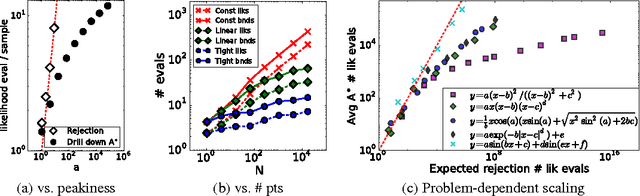
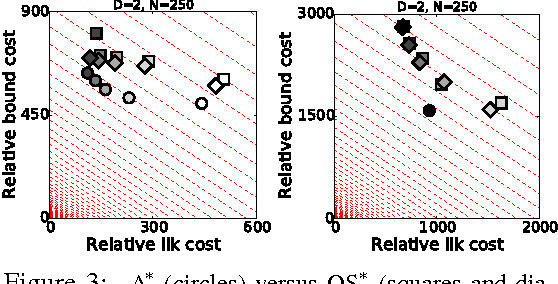
The problem of drawing samples from a discrete distribution can be converted into a discrete optimization problem. In this work, we show how sampling from a continuous distribution can be converted into an optimization problem over continuous space. Central to the method is a stochastic process recently described in mathematical statistics that we call the Gumbel process. We present a new construction of the Gumbel process and A* sampling, a practical generic sampling algorithm that searches for the maximum of a Gumbel process using A* search. We analyze the correctness and convergence time of A* sampling and demonstrate empirically that it makes more efficient use of bound and likelihood evaluations than the most closely related adaptive rejection sampling-based algorithms.
Candidate Constrained CRFs for Loss-Aware Structured Prediction
Dec 10, 2014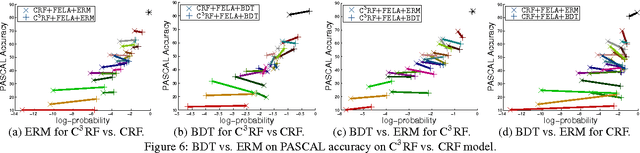


When evaluating computer vision systems, we are often concerned with performance on a task-specific evaluation measure such as the Intersection-Over-Union score used in the PASCAL VOC image segmentation challenge. Ideally, our systems would be tuned specifically to these evaluation measures. However, despite much work on loss-aware structured prediction, top performing systems do not use these techniques. In this work, we seek to address this problem, incorporating loss-aware prediction in a manner that is amenable to the approaches taken by top performing systems. Our main idea is to simultaneously leverage two systems: a highly tuned pipeline system as is found on top of leaderboards, and a traditional CRF. We show how to combine high quality candidate solutions from the pipeline with the probabilistic approach of the CRF that is amenable to loss-aware prediction. The result is that we can use loss-aware prediction methodology to improve performance of the highly tuned pipeline system.
Structured Generative Models of Natural Source Code
Jun 20, 2014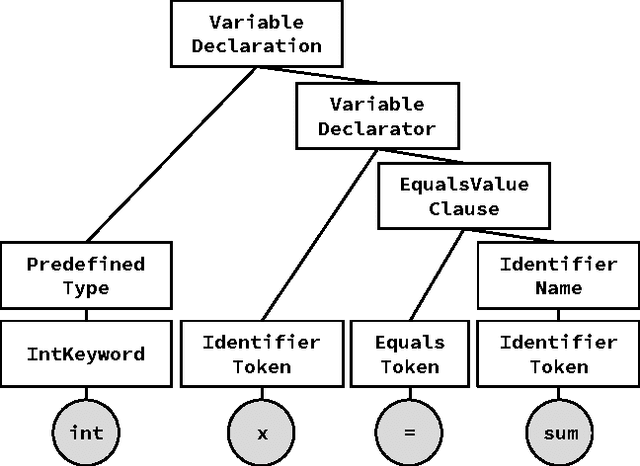
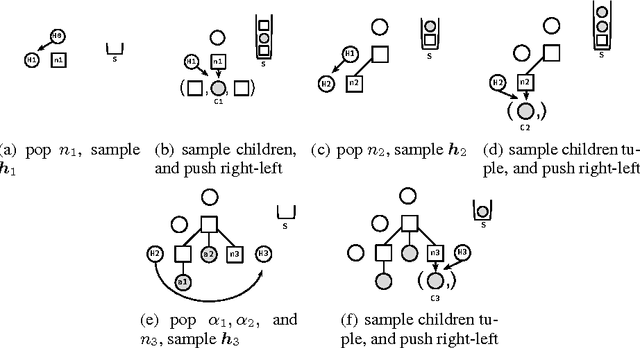
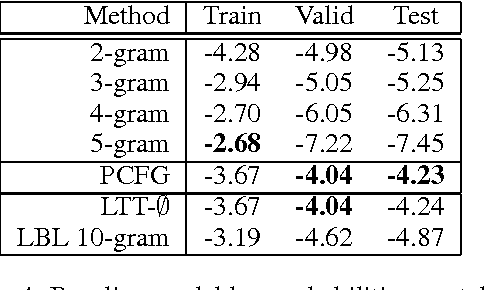
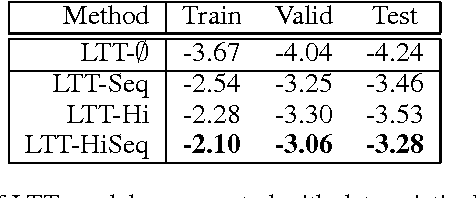
We study the problem of building generative models of natural source code (NSC); that is, source code written and understood by humans. Our primary contribution is to describe a family of generative models for NSC that have three key properties: First, they incorporate both sequential and hierarchical structure. Second, we learn a distributed representation of source code elements. Finally, they integrate closely with a compiler, which allows leveraging compiler logic and abstractions when building structure into the model. We also develop an extension that includes more complex structure, refining how the model generates identifier tokens based on what variables are currently in scope. Our models can be learned efficiently, and we show empirically that including appropriate structure greatly improves the models, measured by the probability of generating test programs.
Detecting Parameter Symmetries in Probabilistic Models
Dec 19, 2013
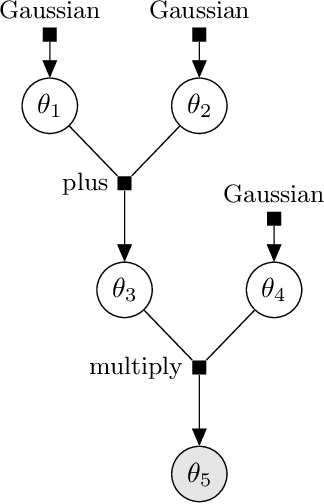


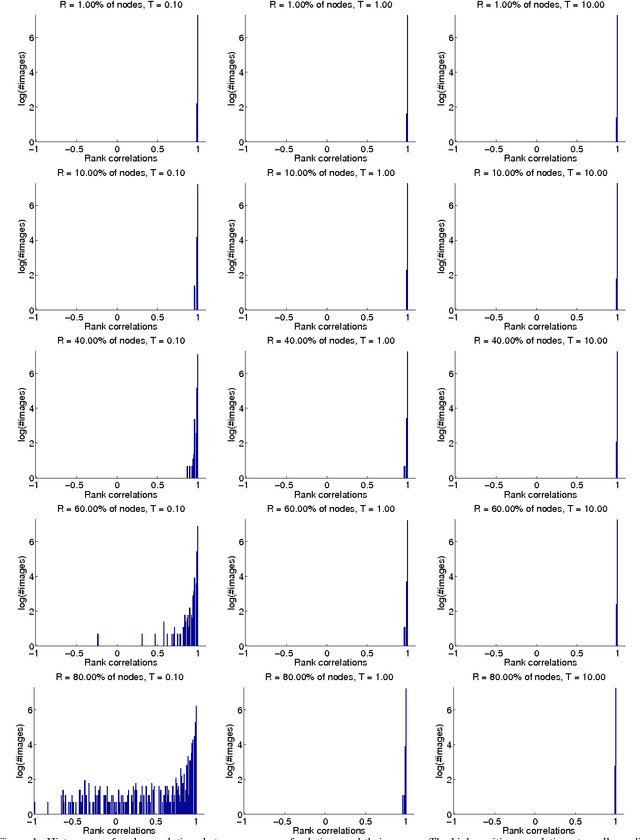
Probabilistic models often have parameters that can be translated, scaled, permuted, or otherwise transformed without changing the model. These symmetries can lead to strong correlation and multimodality in the posterior distribution over the model's parameters, which can pose challenges both for performing inference and interpreting the results. In this work, we address the automatic detection of common problematic model symmetries. To do so, we introduce local symmetries, which cover many common cases and are amenable to automatic detection. We show how to derive algorithms to detect several broad classes of local symmetries. Our algorithms are compatible with probabilistic programming constructs such as arrays, for loops, and if statements, and they scale to models with many variables.
Tighter Linear Program Relaxations for High Order Graphical Models
Sep 26, 2013
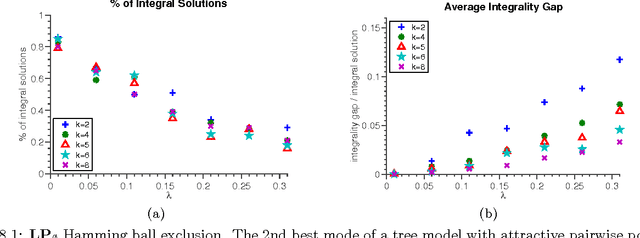
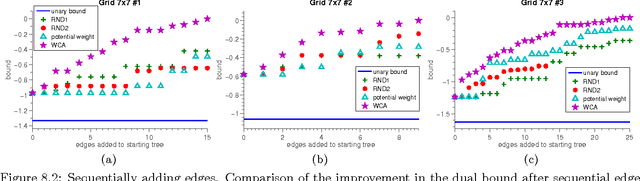
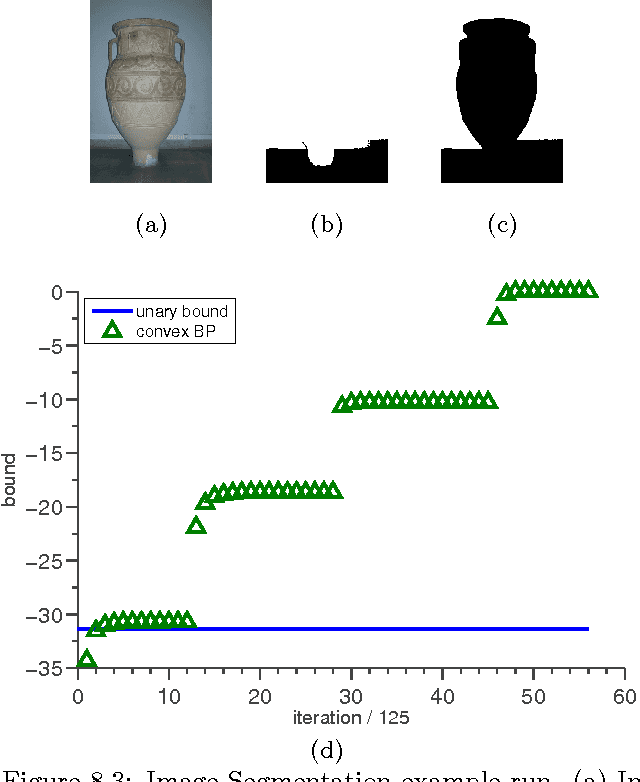
Graphical models with High Order Potentials (HOPs) have received considerable interest in recent years. While there are a variety of approaches to inference in these models, nearly all of them amount to solving a linear program (LP) relaxation with unary consistency constraints between the HOP and the individual variables. In many cases, the resulting relaxations are loose, and in these cases the results of inference can be poor. It is thus desirable to look for more accurate ways of performing inference in these models. In this work, we study the LP relaxations that result from enforcing additional consistency constraints between the HOP and the rest of the model. We address theoretical questions about the strength of the resulting relaxations compared to the relaxations that arise in standard approaches, and we develop practical and efficient message passing algorithms for optimizing the LPs. Empirically, we show that the LPs with additional consistency constraints lead to more accurate inference on some challenging problems that include a combination of low order and high order terms.
Fast Exact Inference for Recursive Cardinality Models
Oct 16, 2012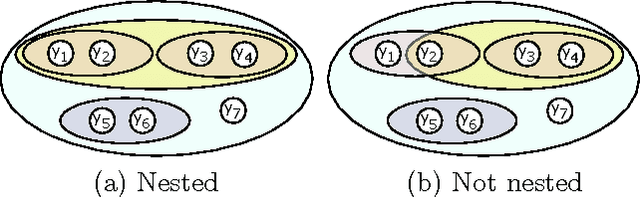
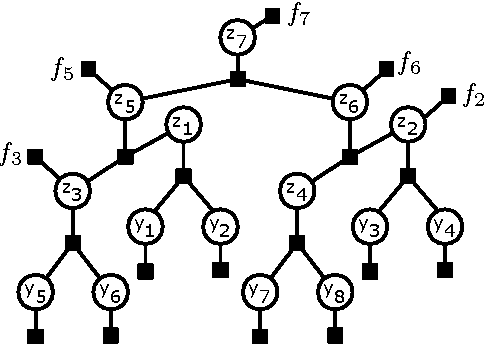
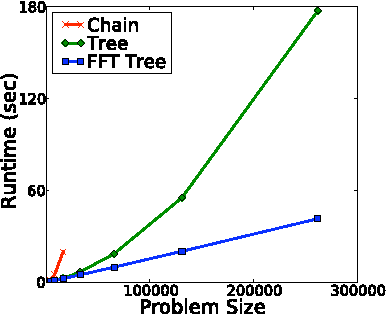
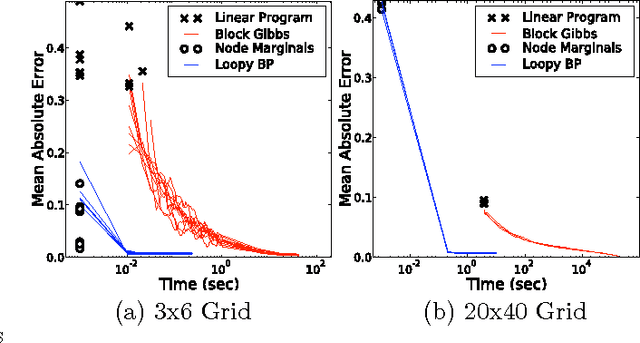
Cardinality potentials are a generally useful class of high order potential that affect probabilities based on how many of D binary variables are active. Maximum a posteriori (MAP) inference for cardinality potential models is well-understood, with efficient computations taking O(DlogD) time. Yet efficient marginalization and sampling have not been addressed as thoroughly in the machine learning community. We show that there exists a simple algorithm for computing marginal probabilities and drawing exact joint samples that runs in O(Dlog2 D) time, and we show how to frame the algorithm as efficient belief propagation in a low order tree-structured model that includes additional auxiliary variables. We then develop a new, more general class of models, termed Recursive Cardinality models, which take advantage of this efficiency. Finally, we show how to do efficient exact inference in models composed of a tree structure and a cardinality potential. We explore the expressive power of Recursive Cardinality models and empirically demonstrate their utility.
Flexible Priors for Exemplar-based Clustering
Jun 13, 2012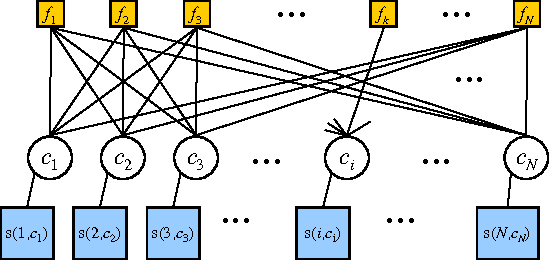
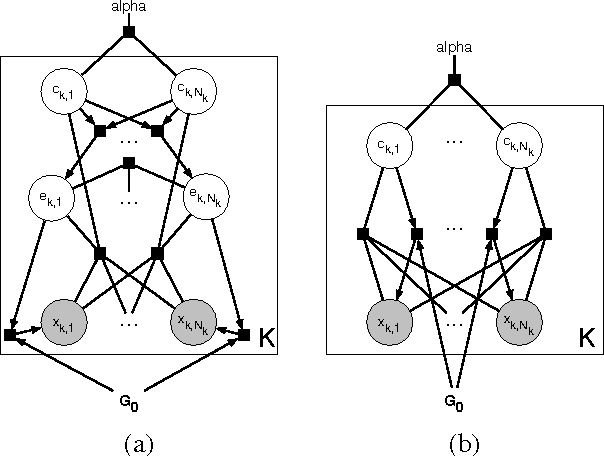
Exemplar-based clustering methods have been shown to produce state-of-the-art results on a number of synthetic and real-world clustering problems. They are appealing because they offer computational benefits over latent-mean models and can handle arbitrary pairwise similarity measures between data points. However, when trying to recover underlying structure in clustering problems, tailored similarity measures are often not enough; we also desire control over the distribution of cluster sizes. Priors such as Dirichlet process priors allow the number of clusters to be unspecified while expressing priors over data partitions. To our knowledge, they have not been applied to exemplar-based models. We show how to incorporate priors, including Dirichlet process priors, into the recently introduced affinity propagation algorithm. We develop an efficient maxproduct belief propagation algorithm for our new model and demonstrate experimentally how the expanded range of clustering priors allows us to better recover true clusterings in situations where we have some information about the generating process.
Interpreting Graph Cuts as a Max-Product Algorithm
May 05, 2011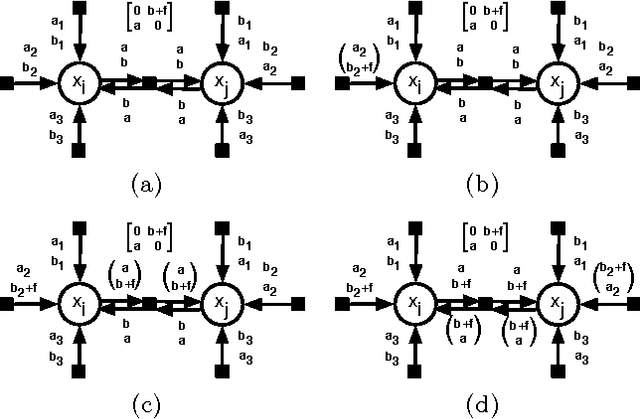
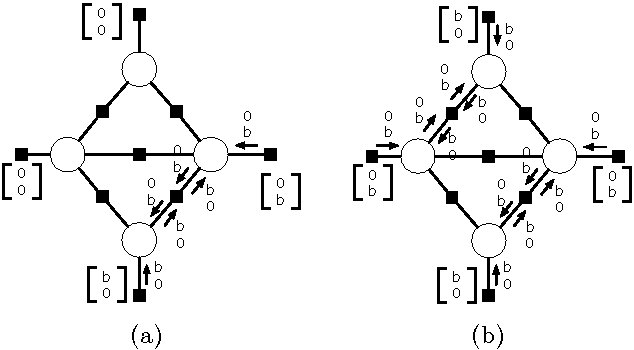
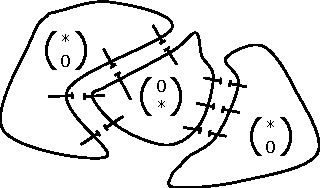
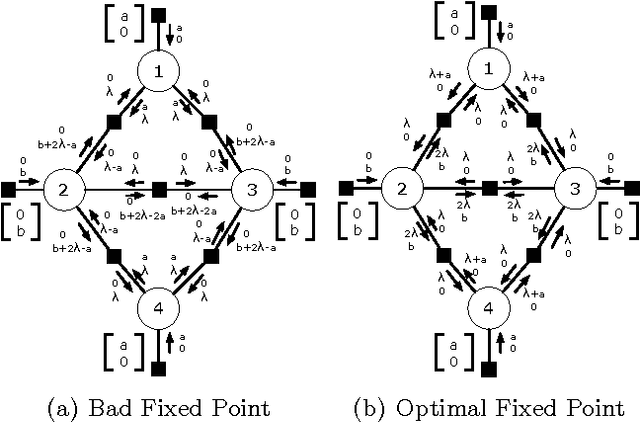
The maximum a posteriori (MAP) configuration of binary variable models with submodular graph-structured energy functions can be found efficiently and exactly by graph cuts. Max-product belief propagation (MP) has been shown to be suboptimal on this class of energy functions by a canonical counterexample where MP converges to a suboptimal fixed point (Kulesza & Pereira, 2008). In this work, we show that under a particular scheduling and damping scheme, MP is equivalent to graph cuts, and thus optimal. We explain the apparent contradiction by showing that with proper scheduling and damping, MP always converges to an optimal fixed point. Thus, the canonical counterexample only shows the suboptimality of MP with a particular suboptimal choice of schedule and damping. With proper choices, MP is optimal.