 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tight Convex Upper Bound on the Likelihood of a Finite Mixture
Aug 18, 2016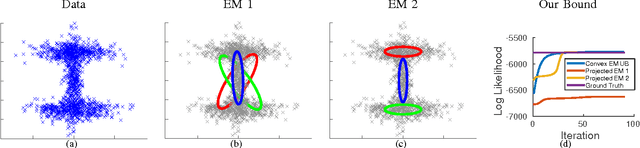
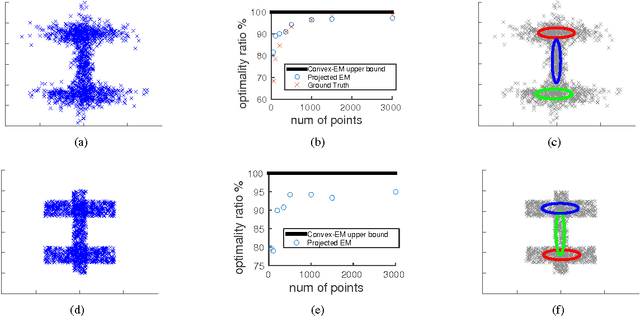
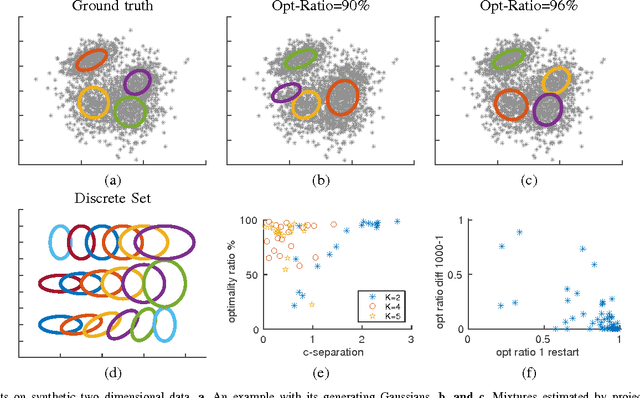

The likelihood function of a finite mixture model is a non-convex function with multiple local maxima and commonly used iterative algorithms such as EM will converge to different solutions depending on initial conditions. In this paper we ask: is it possible to assess how far we are from the global maximum of the likelihood? Since the likelihood of a finite mixture model can grow unboundedly by centering a Gaussian on a single datapoint and shrinking the covariance, we constrain the problem by assuming that the parameters of the individual models are members of a large discrete set (e.g. estimating a mixture of two Gaussians where the means and variances of both Gaussians are members of a set of a million possible means and variances). For this setting we show that a simple upper bound on the likelihood can be computed using convex optimization and we analyze conditions under which the bound is guaranteed to be tight. This bound can then be used to assess the quality of solutions found by EM (where the final result is projected on the discrete set) or any other mixture estimation algorithm. For any dataset our method allows us to find a finite mixture model together with a dataset-specific bound on how far the likelihood of this mixture is from the global optimum of the likelihood
Tighter Linear Program Relaxations for High Order Graphical Models
Sep 26, 2013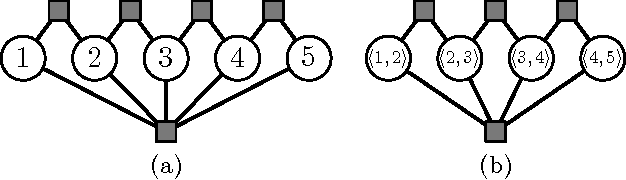
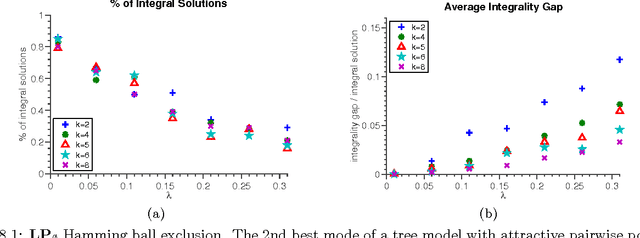
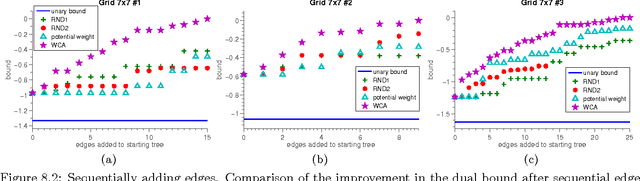
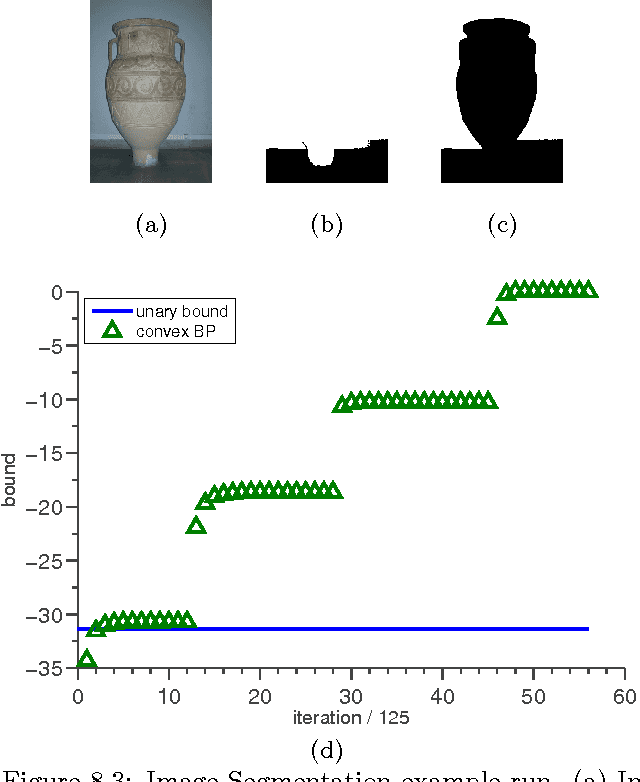
Graphical models with High Order Potentials (HOPs) have received considerable interest in recent years. While there are a variety of approaches to inference in these models, nearly all of them amount to solving a linear program (LP) relaxation with unary consistency constraints between the HOP and the individual variables. In many cases, the resulting relaxations are loose, and in these cases the results of inference can be poor. It is thus desirable to look for more accurate ways of performing inference in these models. In this work, we study the LP relaxations that result from enforcing additional consistency constraints between the HOP and the rest of the model. We address theoretical questions about the strength of the resulting relaxations compared to the relaxations that arise in standard approaches, and we develop practical and efficient message passing algorithms for optimizing the LPs. Empirically, we show that the LPs with additional consistency constraints lead to more accurate inference on some challenging problems that include a combination of low order and high order terms.