 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepBrainPrint: A Novel Contrastive Framework for Brain MRI Re-Identification
Feb 25, 2023



Recent advances in MRI have led to the creation of large datasets. With the increase in data volume, it has become difficult to locate previous scans of the same patient within these datasets (a process known as re-identification). To address this issue, we propose an AI-powered medical imaging retrieval framework called DeepBrainPrint, which is designed to retrieve brain MRI scans of the same patient. Our framework is a semi-self-supervised contrastive deep learning approach with three main innovations. First, we use a combination of self-supervised and supervised paradigms to create an effective brain fingerprint from MRI scans that can be used for real-time image retrieval. Second, we use a special weighting function to guide the training and improve model convergence. Third, we introduce new imaging transformations to improve retrieval robustness in the presence of intensity variations (i.e. different scan contrasts), and to account for age and disease progression in patients. We tested DeepBrainPrint on a large dataset of T1-weighted brain MRIs from the Alzheimer's Disease Neuroimaging Initiative (ADNI) and on a synthetic dataset designed to evaluate retrieval performance with different image modalities. Our results show that DeepBrainPrint outperforms previous methods, including simple similarity metrics and more advanced contrastive deep learning frameworks.
Deformably-Scaled Transposed Convolution
Oct 17, 2022

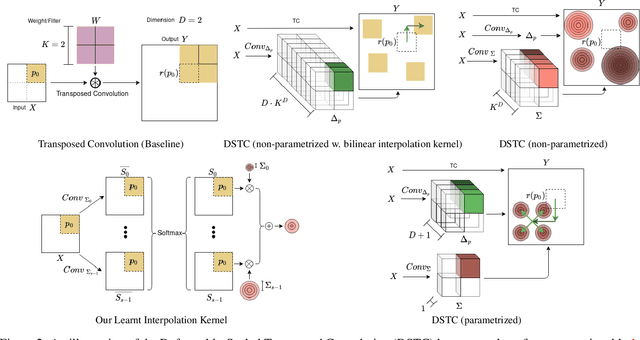
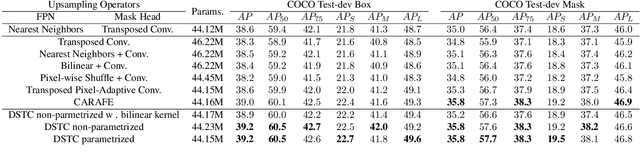
Transposed convolution is crucial for generating high-resolution outputs, yet has received little attention compared to convolution layers. In this work we revisit transposed convolution and introduce a novel layer that allows us to place information in the image selectively and choose the `stroke breadth' at which the image is synthesized, whilst incurring a small additional parameter cost. For this we introduce three ideas: firstly, we regress offsets to the positions where the transpose convolution results are placed; secondly we broadcast the offset weight locations over a learnable neighborhood; and thirdly we use a compact parametrization to share weights and restrict offsets. We show that simply substituting upsampling operators with our novel layer produces substantial improvements across tasks as diverse as instance segmentation, object detection, semantic segmentation, generative image modeling, and 3D magnetic resonance image enhancement, while outperforming all existing variants of transposed convolutions. Our novel layer can be used as a drop-in replacement for 2D and 3D upsampling operators and the code will be publicly available.
An Experiment Design Paradigm using Joint Feature Selection and Task Optimization
Oct 13, 2022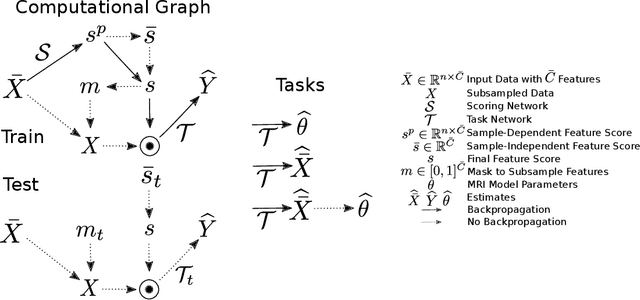
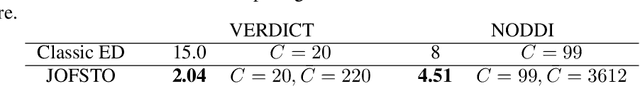

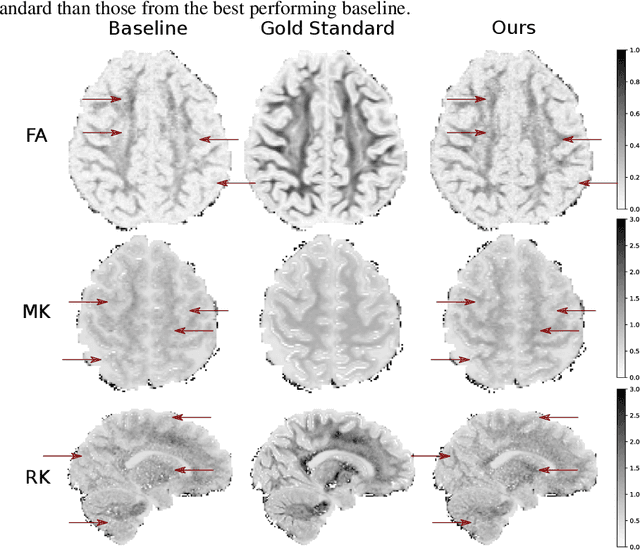
This paper presents a subsampling-task paradigm for data-driven task-specific experiment design (ED) and a novel method in populationwide supervised feature selection (FS). Optimal ED, the choice of sampling points under constraints of limited acquisition-time, arises in a wide variety of scientific and engineering contexts. However the continuous optimization used in classical approaches depend on a-priori parameter choices and challenging non-convex optimization landscapes. This paper proposes to replace this strategy with a subsampling-task paradigm, analogous to populationwide supervised FS. In particular, we introduce JOFSTO, which performs JOint Feature Selection and Task Optimization. JOFSTO jointly optimizes two coupled networks: one for feature scoring, which provides the ED, the other for execution of a downstream task or process. Unlike most FS problems, e.g. selecting protein expressions for classification, ED problems typically select from highly correlated globally informative candidates rather than seeking a small number of highly informative features among many uninformative features. JOFSTO's construction efficiently identifies potentially correlated, but effective subsets and returns a trained task network. We demonstrate the approach using parameter estimation and mapping problems in quantitative MRI, where economical ED is crucial for clinical application. Results from simulations and empirical data show the subsampling-task paradigm strongly outperforms classical ED, and within our paradigm, JOFSTO outperforms state-of-the-art supervised FS techniques. JOFSTO extends immediately to wider image-based ED problems and other scenarios where the design must be specified globally across large numbers of acquisitions. Code will be released.
Fitting a Directional Microstructure Model to Diffusion-Relaxation MRI Data with Self-Supervised Machine Learning
Oct 05, 2022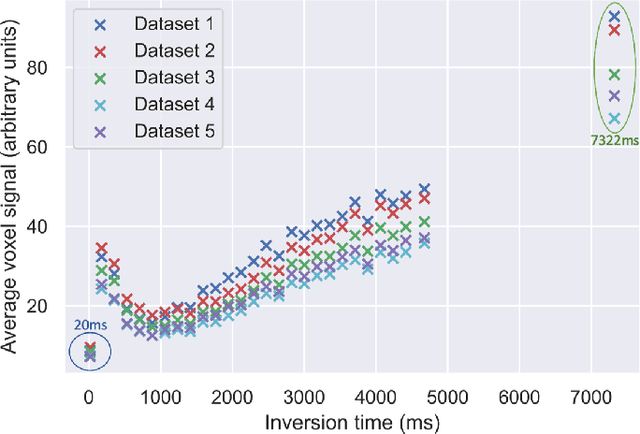
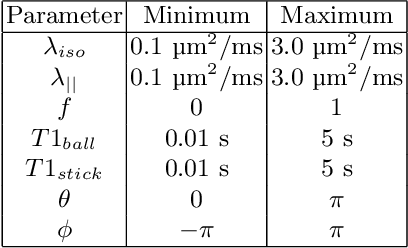
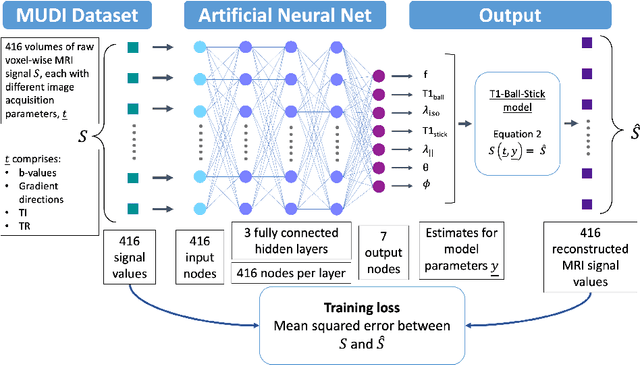
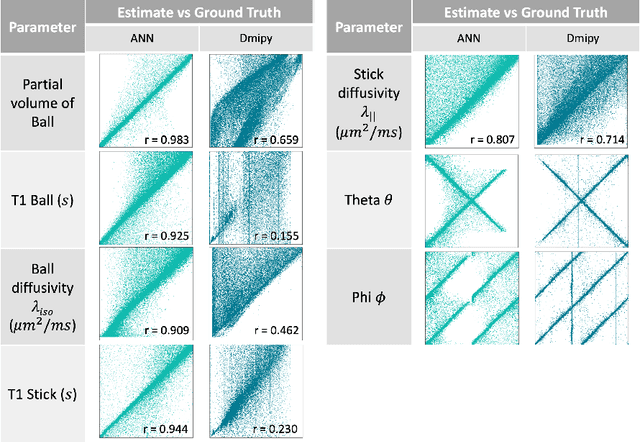
Machine learning is a powerful approach for fitting microstructural models to diffusion MRI data. Early machine learning microstructure imaging implementations trained regressors to estimate model parameters in a supervised way, using synthetic training data with known ground truth. However, a drawback of this approach is that the choice of training data impacts fitted parameter values. Self-supervised learning is emerging as an attractive alternative to supervised learning in this context. Thus far, both supervised and self-supervised learning have typically been applied to isotropic models, such as intravoxel incoherent motion (IVIM), as opposed to models where the directionality of anisotropic structures is also estimated. In this paper, we demonstrate self-supervised machine learning model fitting for a directional microstructural model. In particular, we fit a combined T1-ball-stick model to the multidimensional diffusion (MUDI) challenge diffusion-relaxation dataset. Our self-supervised approach shows clear improvements in parameter estimation and computational time, for both simulated and in-vivo brain data, compared to standard non-linear least squares fitting. Code for the artificial neural net constructed for this study is available for public use from the following GitHub repository: https://github.com/jplte/deep-T1-ball-stick
Bayesian Pseudo Labels: Expectation Maximization for Robust and Efficient Semi-Supervised Segmentation
Aug 08, 2022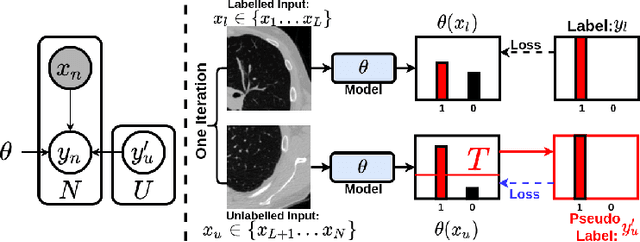
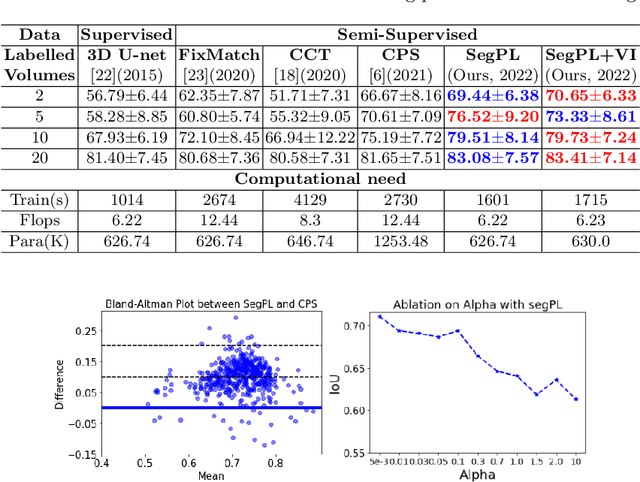
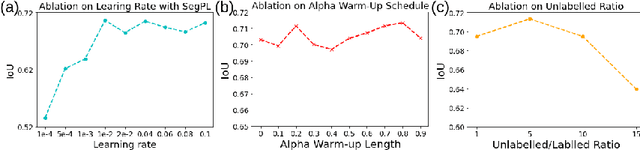
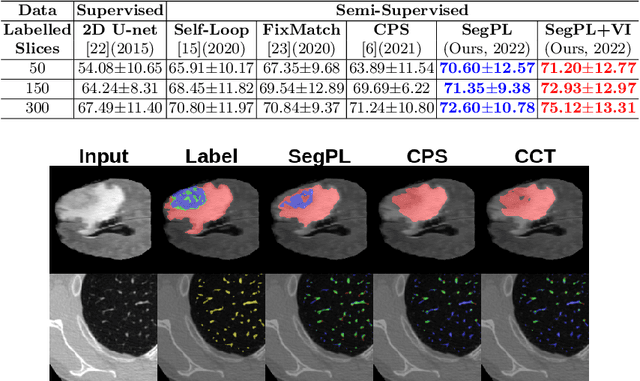
This paper concerns pseudo labelling in segmentation. Our contribution is fourfold. Firstly, we present a new formulation of pseudo-labelling as an Expectation-Maximization (EM) algorithm for clear statistical interpretation. Secondly, we propose a semi-supervised medical image segmentation method purely based on the original pseudo labelling, namely SegPL. We demonstrate SegPL is a competitive approach against state-of-the-art consistency regularisation based methods on semi-supervised segmentation on a 2D multi-class MRI brain tumour segmentation task and a 3D binary CT lung vessel segmentation task. The simplicity of SegPL allows less computational cost comparing to prior methods. Thirdly, we demonstrate that the effectiveness of SegPL may originate from its robustness against out-of-distribution noises and adversarial attacks. Lastly, under the EM framework, we introduce a probabilistic generalisation of SegPL via variational inference, which learns a dynamic threshold for pseudo labelling during the training. We show that SegPL with variational inference can perform uncertainty estimation on par with the gold-standard method Deep Ensemble.
An efficient semi-supervised quality control system trained using physics-based MRI-artefact generators and adversarial training
Jun 07, 2022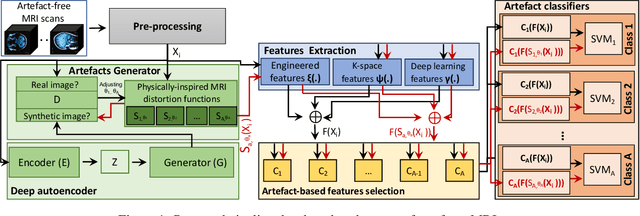

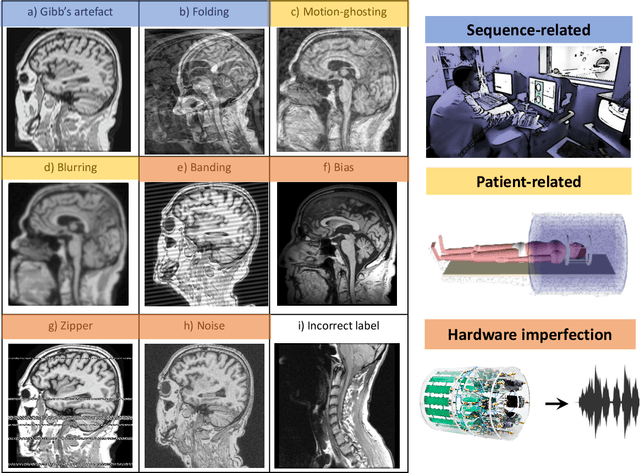

Large medical imaging data sets are becoming increasingly available. A common challenge in these data sets is to ensure that each sample meets minimum quality requirements devoid of significant artefacts. Despite a wide range of existing automatic methods having been developed to identify imperfections and artefacts in medical imaging, they mostly rely on data-hungry methods. In particular, the lack of sufficient scans with artefacts available for training has created a barrier in designing and deploying machine learning in clinical research. To tackle this problem, we propose a novel framework having four main components: (1) a set of artefact generators inspired by magnetic resonance physics to corrupt brain MRI scans and augment a training dataset, (2) a set of abstract and engineered features to represent images compactly, (3) a feature selection process that depends on the class of artefact to improve classification performance, and (4) a set of Support Vector Machine (SVM) classifiers trained to identify artefacts. Our novel contributions are threefold: first, we use the novel physics-based artefact generators to generate synthetic brain MRI scans with controlled artefacts as a data augmentation technique. This will avoid the labour-intensive collection and labelling process of scans with rare artefacts. Second, we propose a large pool of abstract and engineered image features developed to identify 9 different artefacts for structural MRI. Finally, we use an artefact-based feature selection block that, for each class of artefacts, finds the set of features that provide the best classification performance. We performed validation experiments on a large data set of scans with artificially-generated artefacts, and in a multiple sclerosis clinical trial where real artefacts were identified by experts, showing that the proposed pipeline outperforms traditional methods.
Progressive Subsampling for Oversampled Data -- Application to Quantitative MRI
Apr 08, 2022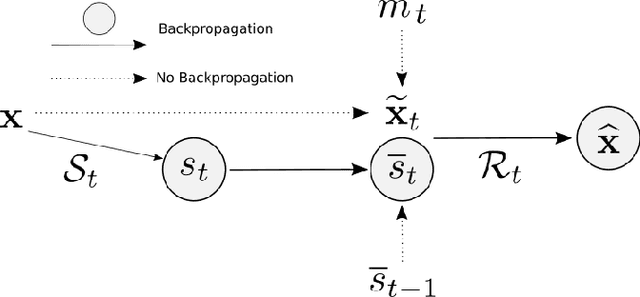
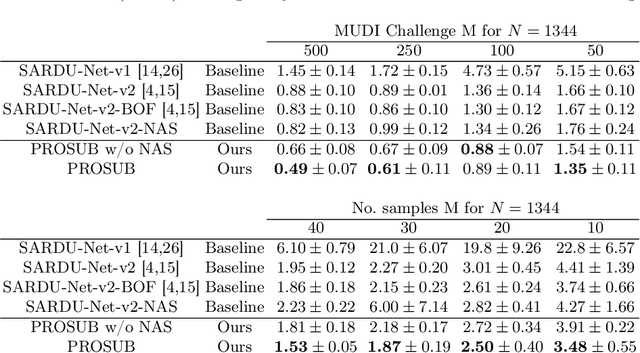
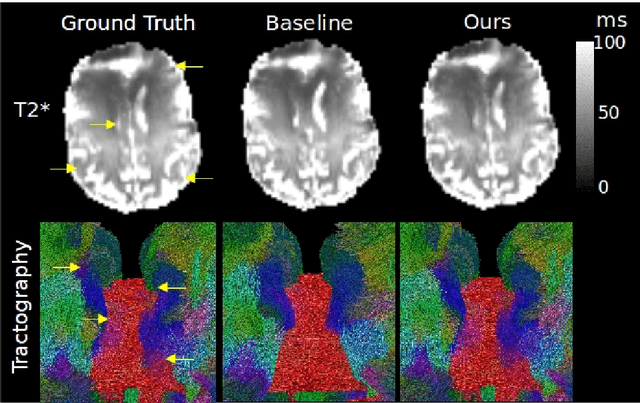
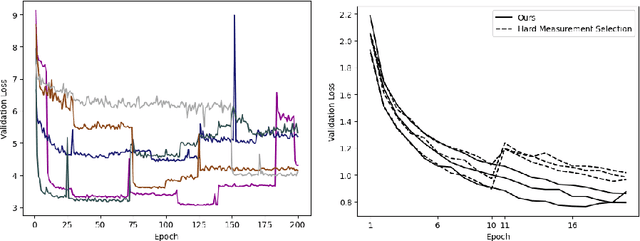
We present PROSUB: PROgressive SUBsampling, a deep learning based, automated methodology that subsamples an oversampled data set (e.g. multi-channeled 3D images) with minimal loss of information. We build upon a recent dual-network approach that won the MICCAI MUlti-DIffusion (MUDI) quantitative MRI measurement sampling-reconstruction challenge, but suffers from deep learning training instability, by subsampling with a hard decision boundary. PROSUB uses the paradigm of recursive feature elimination (RFE) and progressively subsamples measurements during deep learning training, improving optimization stability. PROSUB also integrates a neural architecture search (NAS) paradigm, allowing the network architecture hyperparameters to respond to the subsampling process. We show PROSUB outperforms the winner of the MUDI MICCAI challenge, producing large improvements >18% MSE on the MUDI challenge sub-tasks and qualitative improvements on downstream processes useful for clinical applications. We also show the benefits of incorporating NAS and analyze the effect of PROSUB's components. As our method generalizes to other problems beyond MRI measurement selection-reconstruction, our code is https://github.com/sbb-gh/PROSUB
Learning Morphological Feature Perturbations for Calibrated Semi-Supervised Segmentation
Apr 01, 2022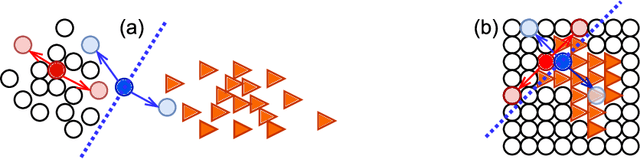
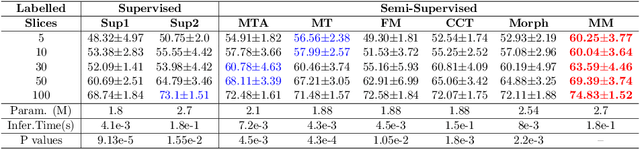
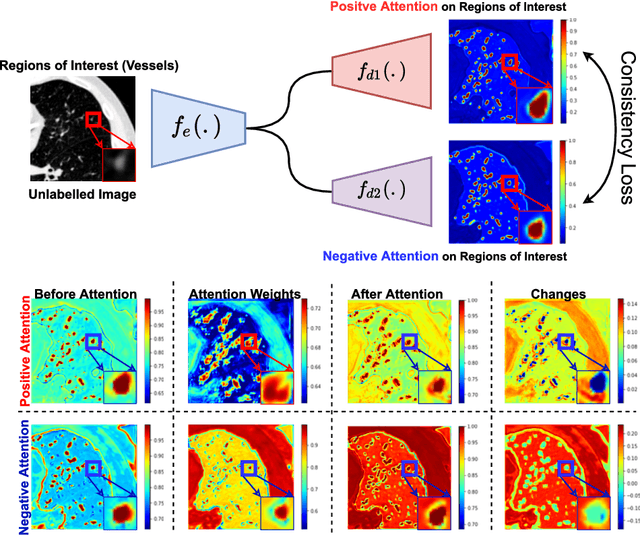

We propose MisMatch, a novel consistency-driven semi-supervised segmentation framework which produces predictions that are invariant to learnt feature perturbations. MisMatch consists of an encoder and a two-head decoders. One decoder learns positive attention to the foreground regions of interest (RoI) on unlabelled images thereby generating dilated features. The other decoder learns negative attention to the foreground on the same unlabelled images thereby generating eroded features. We then apply a consistency regularisation on the paired predictions. MisMatch outperforms state-of-the-art semi-supervised methods on a CT-based pulmonary vessel segmentation task and a MRI-based brain tumour segmentation task. In addition, we show that the effectiveness of MisMatch comes from better model calibration than its supervised learning counterpart.
Survival Analysis for Idiopathic Pulmonary Fibrosis using CT Images and Incomplete Clinical Data
Mar 21, 2022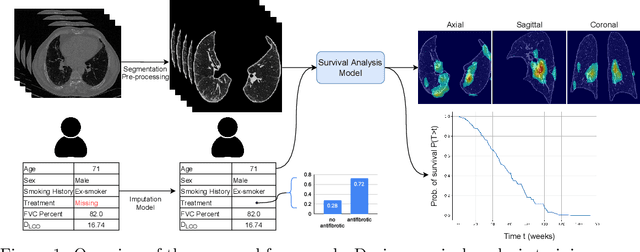
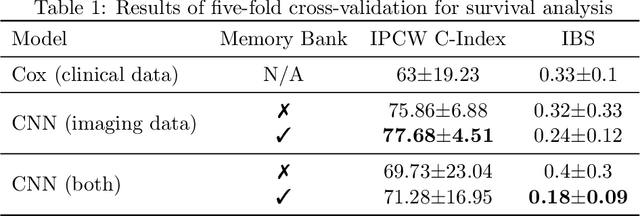
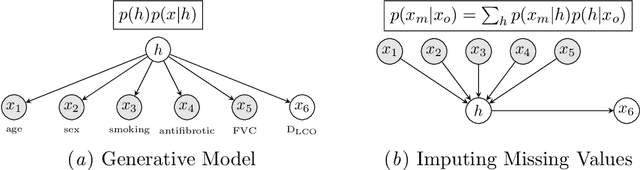

Idiopathic Pulmonary Fibrosis (IPF) is an inexorably progressive fibrotic lung disease with a variable and unpredictable rate of progression. CT scans of the lungs inform clinical assessment of IPF patients and contain pertinent information related to disease progression. In this work, we propose a multi-modal method that uses neural networks and memory banks to predict the survival of IPF patients using clinical and imaging data. The majority of clinical IPF patient records have missing data (e.g. missing lung function tests). To this end, we propose a probabilistic model that captures the dependencies between the observed clinical variables and imputes missing ones. This principled approach to missing data imputation can be naturally combined with a deep survival analysis model. We show that the proposed framework yields significantly better survival analysis results than baselines in terms of concordance index and integrated Brier score. Our work also provides insights into novel image-based biomarkers that are linked to mortality.
VAFO-Loss: VAscular Feature Optimised Loss Function for Retinal Artery/Vein Segmentation
Mar 12, 2022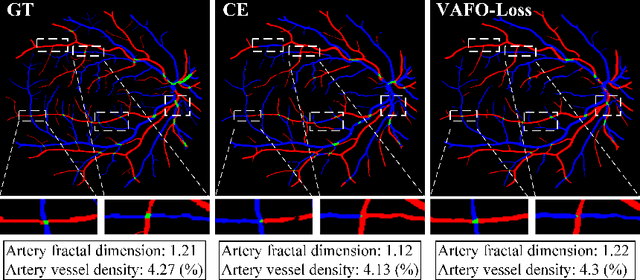
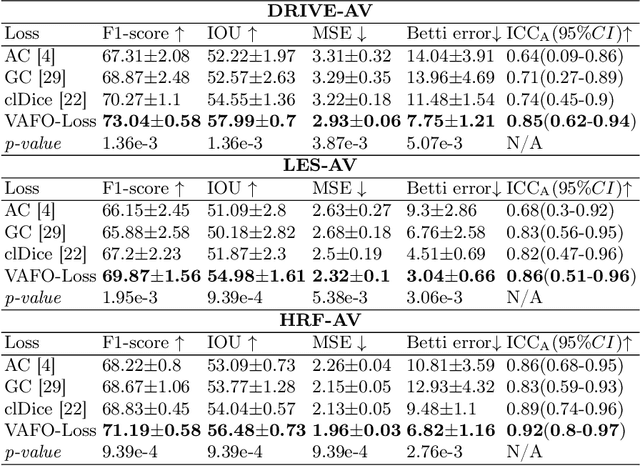
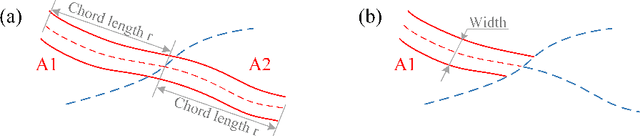
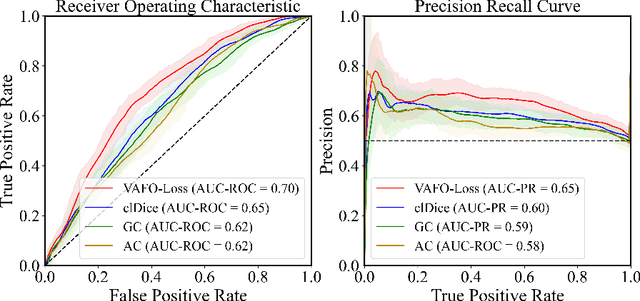
Estimating clinically-relevant vascular features following vessel segmentation is a standard pipeline for retinal vessel analysis, which provides potential ocular biomarkers for both ophthalmic disease and systemic disease. In this work, we integrate these clinical features into a novel vascular feature optimised loss function (VAFO-Loss), in order to regularise networks to produce segmentation maps, with which more accurate vascular features can be derived. Two common vascular features, vessel density and fractal dimension, are identified to be sensitive to intra-segment misclassification, which is a well-recognised problem in multi-class artery/vein segmentation particularly hindering the estimation of these vascular features. Thus we encode these two features into VAFO-Loss. We first show that incorporating our end-to-end VAFO-Loss in standard segmentation networks indeed improves vascular feature estimation, yielding quantitative improvement in stroke incidence prediction, a clinical downstream task. We also report a technically interesting finding that the trained segmentation network, albeit biased by the feature optimised loss VAFO-Loss, shows statistically significant improvement in segmentation metrics, compared to those trained with other state-of-the-art segmentation losses.