 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlended Diffusion for Text-driven Editing of Natural Images
Nov 29, 2021
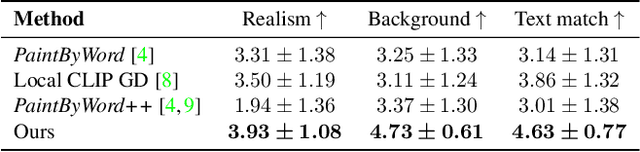
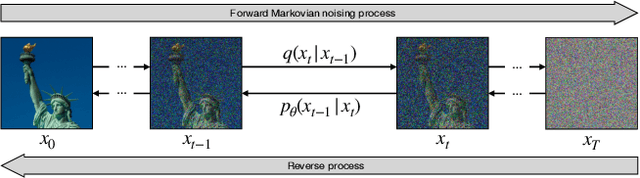
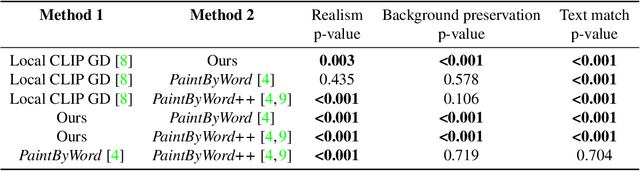
Natural language offers a highly intuitive interface for image editing. In this paper, we introduce the first solution for performing local (region-based) edits in generic natural images, based on a natural language description along with an ROI mask. We achieve our goal by leveraging and combining a pretrained language-image model (CLIP), to steer the edit towards a user-provided text prompt, with a denoising diffusion probabilistic model (DDPM) to generate natural-looking results. To seamlessly fuse the edited region with the unchanged parts of the image, we spatially blend noised versions of the input image with the local text-guided diffusion latent at a progression of noise levels. In addition, we show that adding augmentations to the diffusion process mitigates adversarial results. We compare against several baselines and related methods, both qualitatively and quantitatively, and show that our method outperforms these solutions in terms of overall realism, ability to preserve the background and matching the text. Finally, we show several text-driven editing applications, including adding a new object to an image, removing/replacing/altering existing objects, background replacement, and image extrapolation.
Classification-Regression for Chart Comprehension
Nov 29, 2021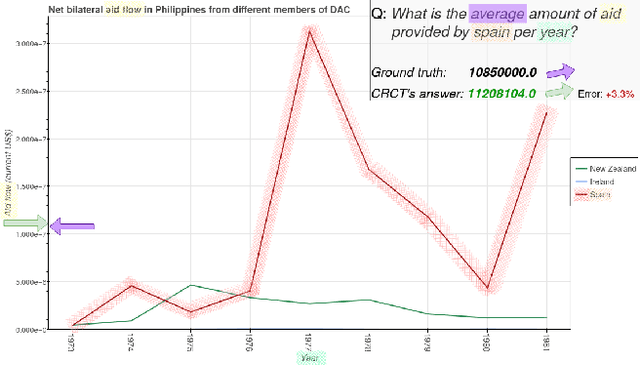
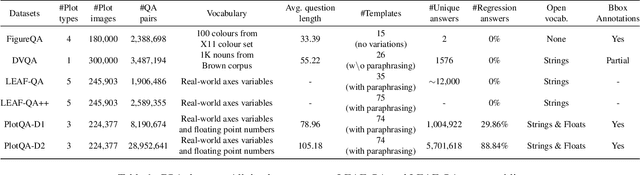
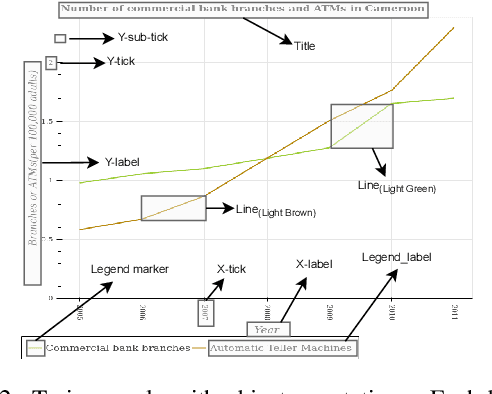
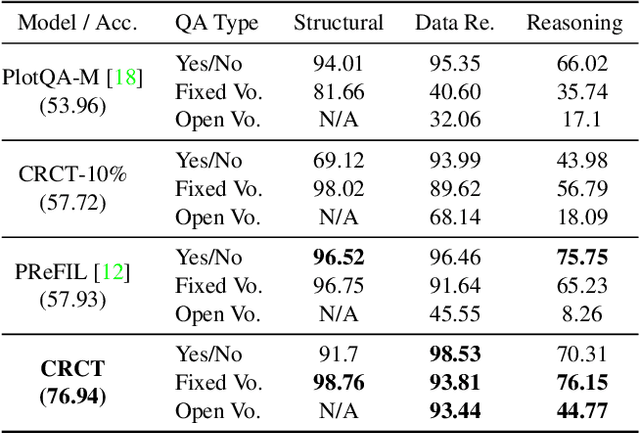
Charts are a popular and effective form of data visualization. Chart question answering (CQA) is a task used for assessing chart comprehension, which is fundamentally different from understanding natural images. CQA requires analyzing the relationships between the textual and the visual components of a chart, in order to answer general questions or infer numerical values. Most existing CQA datasets and it models are based on simplifying assumptions that often enable surpassing human performance. In this work, we further explore the reasons behind this outcome and propose a new model that jointly learns classification and regression. Our language-vision set up with co-attention transformers captures the complex interactions between the question and the textual elements, which commonly exist in real-world charts. We validate these conclusions with extensive experiments and breakdowns on the realistic PlotQA dataset, outperforming previous approaches by a large margin, while showing competitive performance on FigureQA. Our model's edge is particularly emphasized on questions with out-of-vocabulary answers, many of which require regression. We hope that this work will stimulate further research towards solving the challenging and highly practical task of chart comprehension.
StyleAlign: Analysis and Applications of Aligned StyleGAN Models
Oct 21, 2021
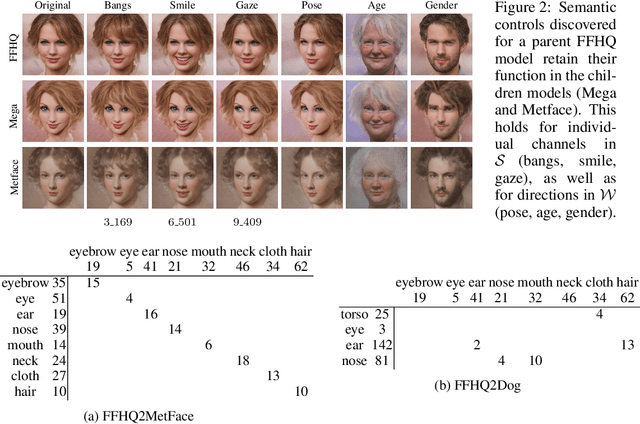

In this paper, we perform an in-depth study of the properties and applications of aligned generative models. We refer to two models as aligned if they share the same architecture, and one of them (the child) is obtained from the other (the parent) via fine-tuning to another domain, a common practice in transfer learning. Several works already utilize some basic properties of aligned StyleGAN models to perform image-to-image translation. Here, we perform the first detailed exploration of model alignment, also focusing on StyleGAN. First, we empirically analyze aligned models and provide answers to important questions regarding their nature. In particular, we find that the child model's latent spaces are semantically aligned with those of the parent, inheriting incredibly rich semantics, even for distant data domains such as human faces and churches. Second, equipped with this better understanding, we leverage aligned models to solve a diverse set of tasks. In addition to image translation, we demonstrate fully automatic cross-domain image morphing. We further show that zero-shot vision tasks may be performed in the child domain, while relying exclusively on supervision in the parent domain. We demonstrate qualitatively and quantitatively that our approach yields state-of-the-art results, while requiring only simple fine-tuning and inversion.
ShapeConv: Shape-aware Convolutional Layer for Indoor RGB-D Semantic Segmentation
Aug 24, 2021
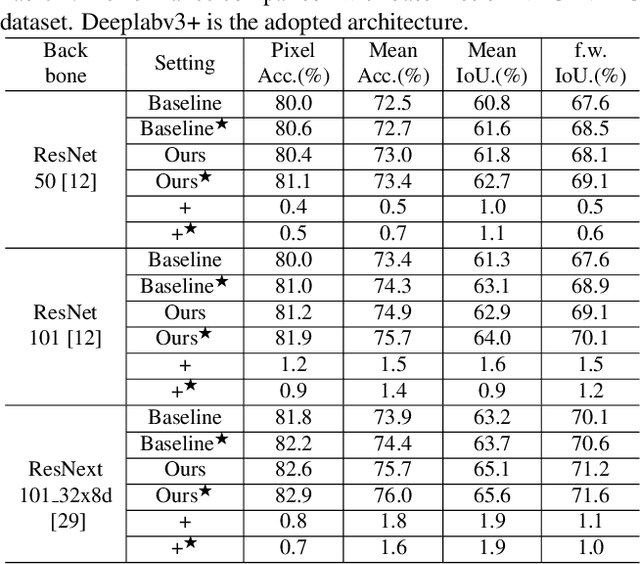
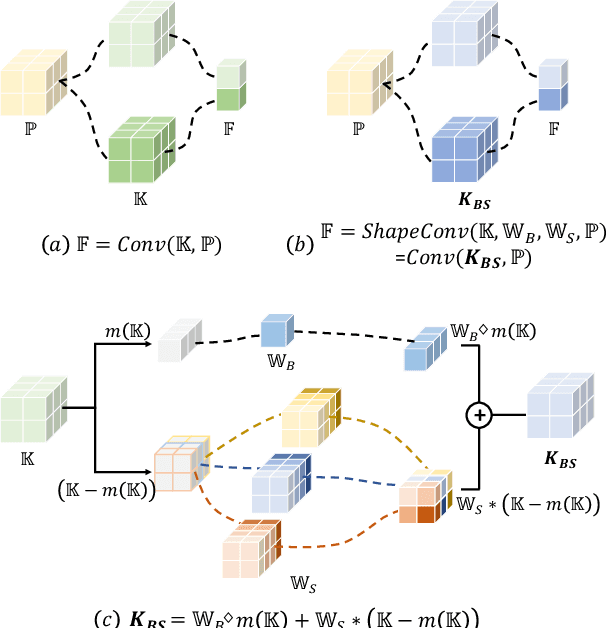
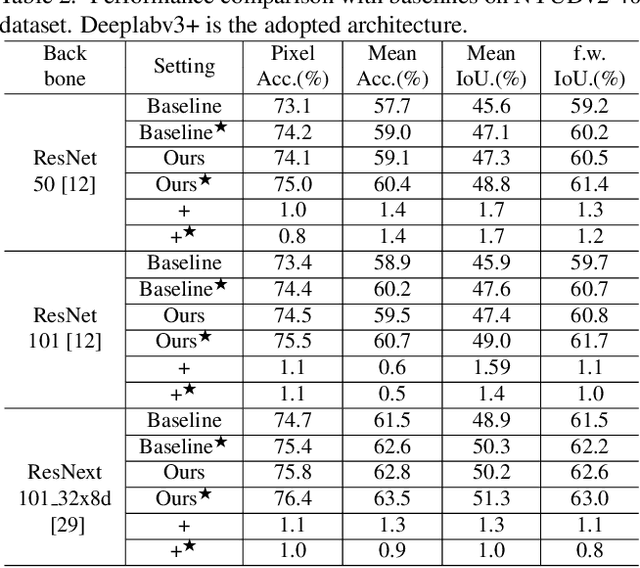
RGB-D semantic segmentation has attracted increasing attention over the past few years. Existing methods mostly employ homogeneous convolution operators to consume the RGB and depth features, ignoring their intrinsic differences. In fact, the RGB values capture the photometric appearance properties in the projected image space, while the depth feature encodes both the shape of a local geometry as well as the base (whereabout) of it in a larger context. Compared with the base, the shape probably is more inherent and has a stronger connection to the semantics, and thus is more critical for segmentation accuracy. Inspired by this observation, we introduce a Shape-aware Convolutional layer (ShapeConv) for processing the depth feature, where the depth feature is firstly decomposed into a shape-component and a base-component, next two learnable weights are introduced to cooperate with them independently, and finally a convolution is applied on the re-weighted combination of these two components. ShapeConv is model-agnostic and can be easily integrated into most CNNs to replace vanilla convolutional layers for semantic segmentation. Extensive experiments on three challenging indoor RGB-D semantic segmentation benchmarks, i.e., NYU-Dv2(-13,-40), SUN RGB-D, and SID, demonstrate the effectiveness of our ShapeConv when employing it over five popular architectures. Moreover, the performance of CNNs with ShapeConv is boosted without introducing any computation and memory increase in the inference phase. The reason is that the learnt weights for balancing the importance between the shape and base components in ShapeConv become constants in the inference phase, and thus can be fused into the following convolution, resulting in a network that is identical to one with vanilla convolutional layers.
GAN Cocktail: mixing GANs without dataset access
Jun 07, 2021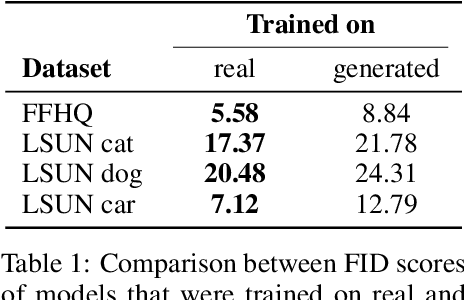

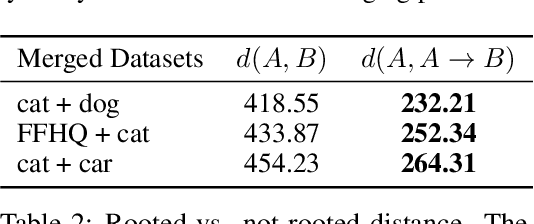

Today's generative models are capable of synthesizing high-fidelity images, but each model specializes on a specific target domain. This raises the need for model merging: combining two or more pretrained generative models into a single unified one. In this work we tackle the problem of model merging, given two constraints that often come up in the real world: (1) no access to the original training data, and (2) without increasing the size of the neural network. To the best of our knowledge, model merging under these constraints has not been studied thus far. We propose a novel, two-stage solution. In the first stage, we transform the weights of all the models to the same parameter space by a technique we term model rooting. In the second stage, we merge the rooted models by averaging their weights and fine-tuning them for each specific domain, using only data generated by the original trained models. We demonstrate that our approach is superior to baseline methods and to existing transfer learning techniques, and investigate several applications.
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
Mar 31, 2021
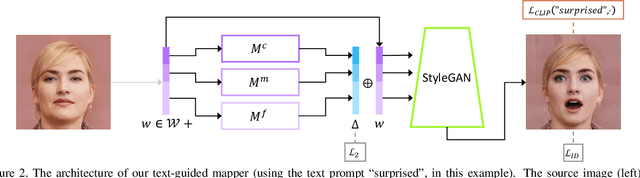


Inspired by the ability of StyleGAN to generate highly realistic images in a variety of domains, much recent work has focused on understanding how to use the latent spaces of StyleGAN to manipulate generated and real images. However, discovering semantically meaningful latent manipulations typically involves painstaking human examination of the many degrees of freedom, or an annotated collection of images for each desired manipulation. In this work, we explore leveraging the power of recently introduced Contrastive Language-Image Pre-training (CLIP) models in order to develop a text-based interface for StyleGAN image manipulation that does not require such manual effort. We first introduce an optimization scheme that utilizes a CLIP-based loss to modify an input latent vector in response to a user-provided text prompt. Next, we describe a latent mapper that infers a text-guided latent manipulation step for a given input image, allowing faster and more stable text-based manipulation. Finally, we present a method for mapping a text prompts to input-agnostic directions in StyleGAN's style space, enabling interactive text-driven image manipulation. Extensive results and comparisons demonstrate the effectiveness of our approaches.
Evaluation and Comparison of Edge-Preserving Filters
Dec 26, 2020
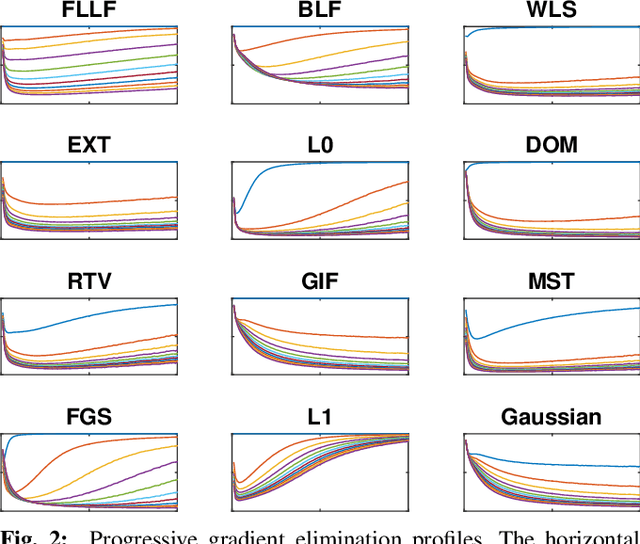

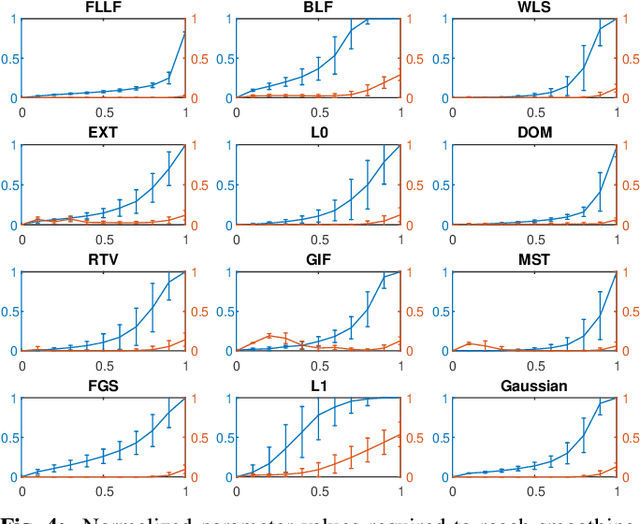
Edge-preserving filters play an essential role in some of the most basic tasks of computational photography, such as abstraction, tonemapping, detail enhancement and texture removal, to name a few. The abundance and diversity of smoothing operators, accompanied by a lack of methodology to evaluate output quality and/or perform an unbiased comparison between them, could lead to misunderstanding and potential misuse of such methods. This paper introduces a systematic methodology for evaluating and comparing such operators and demonstrates it on a diverse set of published edge-preserving filters. Additionally, we present a common baseline along which a comparison of different operators can be achieved and use it to determine equivalent parameter mappings between methods. Finally, we suggest some guidelines for objective comparison and evaluation of edge-preserving filters.
StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation
Dec 03, 2020
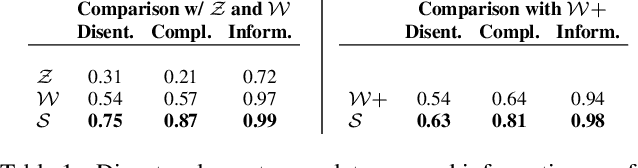
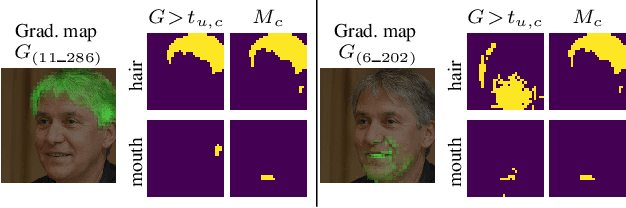
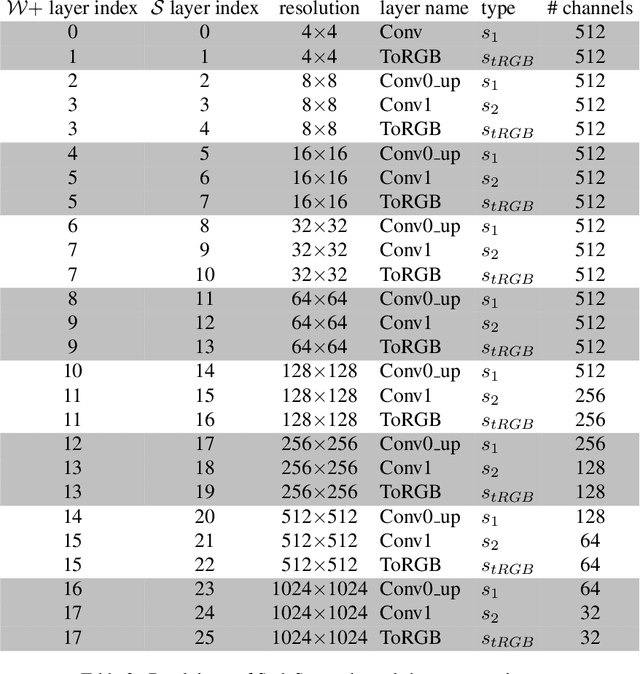
We explore and analyze the latent style space of StyleGAN2, a state-of-the-art architecture for image generation, using models pretrained on several different datasets. We first show that StyleSpace, the space of channel-wise style parameters, is significantly more disentangled than the other intermediate latent spaces explored by previous works. Next, we describe a method for discovering a large collection of style channels, each of which is shown to control a distinct visual attribute in a highly localized and disentangled manner. Third, we propose a simple method for identifying style channels that control a specific attribute, using a pretrained classifier or a small number of example images. Manipulation of visual attributes via these StyleSpace controls is shown to be better disentangled than via those proposed in previous works. To show this, we make use of a newly proposed Attribute Dependency metric. Finally, we demonstrate the applicability of StyleSpace controls to the manipulation of real images. Our findings pave the way to semantically meaningful and well-disentangled image manipulations via simple and intuitive interfaces.
MotioNet: 3D Human Motion Reconstruction from Monocular Video with Skeleton Consistency
Jun 22, 2020
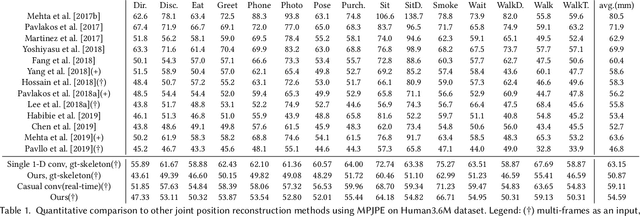

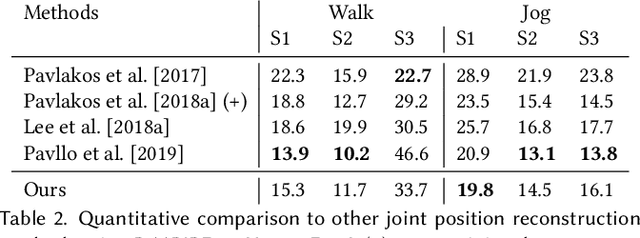
We introduce MotioNet, a deep neural network that directly reconstructs the motion of a 3D human skeleton from monocular video.While previous methods rely on either rigging or inverse kinematics (IK) to associate a consistent skeleton with temporally coherent joint rotations, our method is the first data-driven approach that directly outputs a kinematic skeleton, which is a complete, commonly used, motion representation. At the crux of our approach lies a deep neural network with embedded kinematic priors, which decomposes sequences of 2D joint positions into two separate attributes: a single, symmetric, skeleton, encoded by bone lengths, and a sequence of 3D joint rotations associated with global root positions and foot contact labels. These attributes are fed into an integrated forward kinematics (FK) layer that outputs 3D positions, which are compared to a ground truth. In addition, an adversarial loss is applied to the velocities of the recovered rotations, to ensure that they lie on the manifold of natural joint rotations. The key advantage of our approach is that it learns to infer natural joint rotations directly from the training data, rather than assuming an underlying model, or inferring them from joint positions using a data-agnostic IK solver. We show that enforcing a single consistent skeleton along with temporally coherent joint rotations constrains the solution space, leading to a more robust handling of self-occlusions and depth ambiguities.
DO-Conv: Depthwise Over-parameterized Convolutional Layer
Jun 22, 2020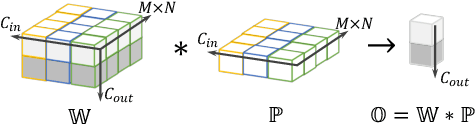
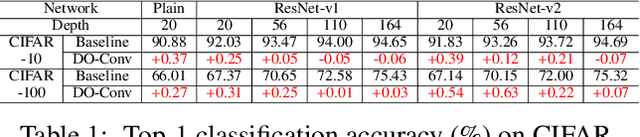

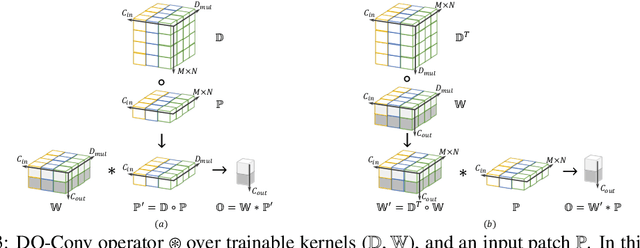
Convolutional layers are the core building blocks of Convolutional Neural Networks (CNNs). In this paper, we propose to augment a convolutional layer with an additional depthwise convolution, where each input channel is convolved with a different 2D kernel. The composition of the two convolutions constitutes an over-parameterization, since it adds learnable parameters, while the resulting linear operation can be expressed by a single convolution layer. We refer to this depthwise over-parameterized convolutional layer as DO-Conv. We show with extensive experiments that the mere replacement of conventional convolutional layers with DO-Conv layers boosts the performance of CNNs on many classical vision tasks, such as image classification, detection, and segmentation. Moreover, in the inference phase, the depthwise convolution is folded into the conventional convolution, reducing the computation to be exactly equivalent to that of a convolutional layer without over-parameterization. As DO-Conv introduces performance gains without incurring any computational complexity increase for inference, we advocate it as an alternative to the conventional convolutional layer. We open-source a reference implementation of DO-Conv in Tensorflow, PyTorch and GluonCV at https://github.com/yangyanli/DO-Conv.