 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Distributed Neural Network Training on Massive Graphs: Randomized Partitions Improve Model Aggregation
May 17, 2023



Distributed training of GNNs enables learning on massive graphs (e.g., social and e-commerce networks) that exceed the storage and computational capacity of a single machine. To reach performance comparable to centralized training, distributed frameworks focus on maximally recovering cross-instance node dependencies with either communication across instances or periodic fallback to centralized training, which create overhead and limit the framework scalability. In this work, we present a simplified framework for distributed GNN training that does not rely on the aforementioned costly operations, and has improved scalability, convergence speed and performance over the state-of-the-art approaches. Specifically, our framework (1) assembles independent trainers, each of which asynchronously learns a local model on locally-available parts of the training graph, and (2) only conducts periodic (time-based) model aggregation to synchronize the local models. Backed by our theoretical analysis, instead of maximizing the recovery of cross-instance node dependencies -- which has been considered the key behind closing the performance gap between model aggregation and centralized training -- , our framework leverages randomized assignment of nodes or super-nodes (i.e., collections of original nodes) to partition the training graph such that it improves data uniformity and minimizes the discrepancy of gradient and loss function across instances. In our experiments on social and e-commerce networks with up to 1.3 billion edges, our proposed RandomTMA and SuperTMA approaches -- despite using less training data -- achieve state-of-the-art performance and 2.31x speedup compared to the fastest baseline, and show better robustness to trainer failures.
A Closer Look at Scoring Functions and Generalization Prediction
Mar 23, 2023



Generalization error predictors (GEPs) aim to predict model performance on unseen distributions by deriving dataset-level error estimates from sample-level scores. However, GEPs often utilize disparate mechanisms (e.g., regressors, thresholding functions, calibration datasets, etc), to derive such error estimates, which can obfuscate the benefits of a particular scoring function. Therefore, in this work, we rigorously study the effectiveness of popular scoring functions (confidence, local manifold smoothness, model agreement), independent of mechanism choice. We find, absent complex mechanisms, that state-of-the-art confidence- and smoothness- based scores fail to outperform simple model-agreement scores when estimating error under distribution shifts and corruptions. Furthermore, on realistic settings where the training data has been compromised (e.g., label noise, measurement noise, undersampling), we find that model-agreement scores continue to perform well and that ensemble diversity is important for improving its performance. Finally, to better understand the limitations of scoring functions, we demonstrate that simplicity bias, or the propensity of deep neural networks to rely upon simple but brittle features, can adversely affect GEP performance. Overall, our work carefully studies the effectiveness of popular scoring functions in realistic settings and helps to better understand their limitations.
A Closer Look at Model Adaptation using Feature Distortion and Simplicity Bias
Mar 23, 2023Advances in the expressivity of pretrained models have increased interest in the design of adaptation protocols which enable safe and effective transfer learning. Going beyond conventional linear probing (LP) and fine tuning (FT) strategies, protocols that can effectively control feature distortion, i.e., the failure to update features orthogonal to the in-distribution, have been found to achieve improved out-of-distribution generalization (OOD). In order to limit this distortion, the LP+FT protocol, which first learns a linear probe and then uses this initialization for subsequent FT, was proposed. However, in this paper, we find when adaptation protocols (LP, FT, LP+FT) are also evaluated on a variety of safety objectives (e.g., calibration, robustness, etc.), a complementary perspective to feature distortion is helpful to explain protocol behavior. To this end, we study the susceptibility of protocols to simplicity bias (SB), i.e. the well-known propensity of deep neural networks to rely upon simple features, as SB has recently been shown to underlie several problems in robust generalization. Using a synthetic dataset, we demonstrate the susceptibility of existing protocols to SB. Given the strong effectiveness of LP+FT, we then propose modified linear probes that help mitigate SB, and lead to better initializations for subsequent FT. We verify the effectiveness of the proposed LP+FT variants for decreasing SB in a controlled setting, and their ability to improve OOD generalization and safety on three adaptation datasets.
CAPER: Coarsen, Align, Project, Refine - A General Multilevel Framework for Network Alignment
Aug 23, 2022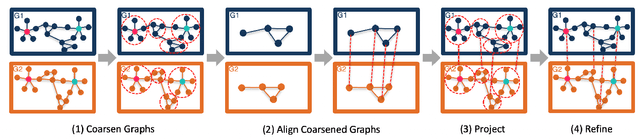

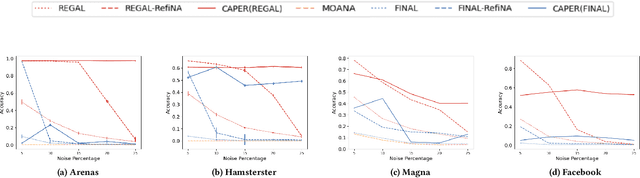
Network alignment, or the task of finding corresponding nodes in different networks, is an important problem formulation in many application domains. We propose CAPER, a multilevel alignment framework that Coarsens the input graphs, Aligns the coarsened graphs, Projects the alignment solution to finer levels and Refines the alignment solution. We show that CAPER can improve upon many different existing network alignment algorithms by enforcing alignment consistency across multiple graph resolutions: nodes matched at finer levels should also be matched at coarser levels. CAPER also accelerates the use of slower network alignment methods, at the modest cost of linear-time coarsening and refinement steps, by allowing them to be run on smaller coarsened versions of the input graphs. Experiments show that CAPER can improve upon diverse network alignment methods by an average of 33% in accuracy and/or an order of magnitude faster in runtime.
Analyzing Data-Centric Properties for Contrastive Learning on Graphs
Aug 04, 2022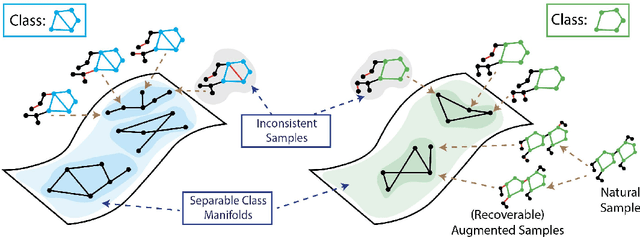


Recent analyses of self-supervised learning (SSL) find the following data-centric properties to be critical for learning good representations: invariance to task-irrelevant semantics, separability of classes in some latent space, and recoverability of labels from augmented samples. However, given their discrete, non-Euclidean nature, graph datasets and graph SSL methods are unlikely to satisfy these properties. This raises the question: how do graph SSL methods, such as contrastive learning (CL), work well? To systematically probe this question, we perform a generalization analysis for CL when using generic graph augmentations (GGAs), with a focus on data-centric properties. Our analysis yields formal insights into the limitations of GGAs and the necessity of task-relevant augmentations. As we empirically show, GGAs do not induce task-relevant invariances on common benchmark datasets, leading to only marginal gains over naive, untrained baselines. Our theory motivates a synthetic data generation process that enables control over task-relevant information and boasts pre-defined optimal augmentations. This flexible benchmark helps us identify yet unrecognized limitations in advanced augmentation techniques (e.g., automated methods). Overall, our work rigorously contextualizes, both empirically and theoretically, the effects of data-centric properties on augmentation strategies and learning paradigms for graph SSL.
Exploring the Design of Adaptation Protocols for Improved Generalization and Machine Learning Safety
Jul 26, 2022

While directly fine-tuning (FT) large-scale, pretrained models on task-specific data is well-known to induce strong in-distribution task performance, recent works have demonstrated that different adaptation protocols, such as linear probing (LP) prior to FT, can improve out-of-distribution generalization. However, the design space of such adaptation protocols remains under-explored and the evaluation of such protocols has primarily focused on distribution shifts. Therefore, in this work, we evaluate common adaptation protocols across distributions shifts and machine learning safety metrics (e.g., anomaly detection, calibration, robustness to corruptions). We find that protocols induce disparate trade-offs that were not apparent from prior evaluation. Further, we demonstrate that appropriate pairing of data augmentation and protocol can substantially mitigate this trade-off. Finally, we hypothesize and empirically see that using hardness-promoting augmentations during LP and then FT with augmentations may be particularly effective for trade-off mitigation.
On Graph Neural Network Fairness in the Presence of Heterophilous Neighborhoods
Jul 10, 2022
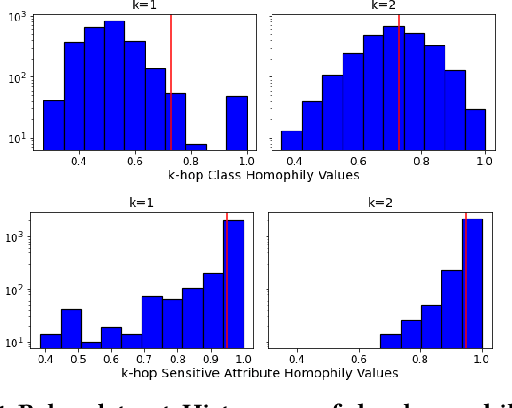

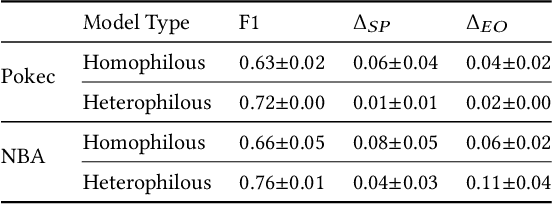
We study the task of node classification for graph neural networks (GNNs) and establish a connection between group fairness, as measured by statistical parity and equal opportunity, and local assortativity, i.e., the tendency of linked nodes to have similar attributes. Such assortativity is often induced by homophily, the tendency for nodes of similar properties to connect. Homophily can be common in social networks where systemic factors have forced individuals into communities which share a sensitive attribute. Through synthetic graphs, we study the interplay between locally occurring homophily and fair predictions, finding that not all node neighborhoods are equal in this respect -- neighborhoods dominated by one category of a sensitive attribute often struggle to obtain fair treatment, especially in the case of diverging local class and sensitive attribute homophily. After determining that a relationship between local homophily and fairness exists, we investigate if the issue of unfairness can be associated to the design of the applied GNN model. We show that by adopting heterophilous GNN designs capable of handling disassortative group labels, group fairness in locally heterophilous neighborhoods can be improved by up to 25% over homophilous designs in real and synthetic datasets.
Learning node embeddings via summary graphs: a brief theoretical analysis
Jul 04, 2022

Graph representation learning plays an important role in many graph mining applications, but learning embeddings of large-scale graphs remains a problem. Recent works try to improve scalability via graph summarization -- i.e., they learn embeddings on a smaller summary graph, and then restore the node embeddings of the original graph. However, all existing works depend on heuristic designs and lack theoretical analysis. Different from existing works, we contribute an in-depth theoretical analysis of three specific embedding learning methods based on introduced kernel matrix, and reveal that learning embeddings via graph summarization is actually learning embeddings on a approximate graph constructed by the configuration model. We also give analysis about approximation error. To the best of our knowledge, this is the first work to give theoretical analysis of this approach. Furthermore, our analysis framework gives interpretation of some existing methods and provides great insights for future work on this problem.
Convolutional Neural Network Dynamics: A Graph Perspective
Nov 09, 2021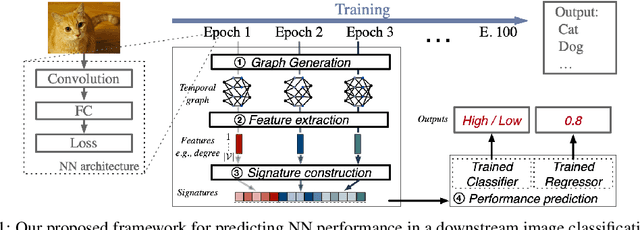

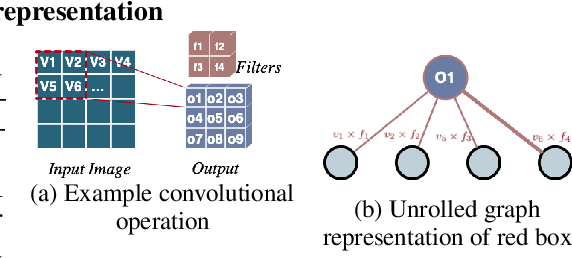
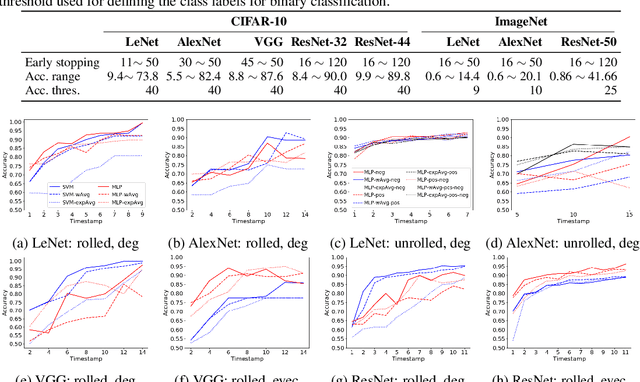
The success of neural networks (NNs) in a wide range of applications has led to increased interest in understanding the underlying learning dynamics of these models. In this paper, we go beyond mere descriptions of the learning dynamics by taking a graph perspective and investigating the relationship between the graph structure of NNs and their performance. Specifically, we propose (1) representing the neural network learning process as a time-evolving graph (i.e., a series of static graph snapshots over epochs), (2) capturing the structural changes of the NN during the training phase in a simple temporal summary, and (3) leveraging the structural summary to predict the accuracy of the underlying NN in a classification or regression task. For the dynamic graph representation of NNs, we explore structural representations for fully-connected and convolutional layers, which are key components of powerful NN models. Our analysis shows that a simple summary of graph statistics, such as weighted degree and eigenvector centrality, over just a few epochs can be used to accurately predict the performance of NNs. For example, a weighted degree-based summary of the time-evolving graph that is constructed based on 5 training epochs of the LeNet architecture achieves classification accuracy of over 93%. Our findings are consistent for different NN architectures, including LeNet, VGG, AlexNet and ResNet.
Augmentations in Graph Contrastive Learning: Current Methodological Flaws & Towards Better Practices
Nov 05, 2021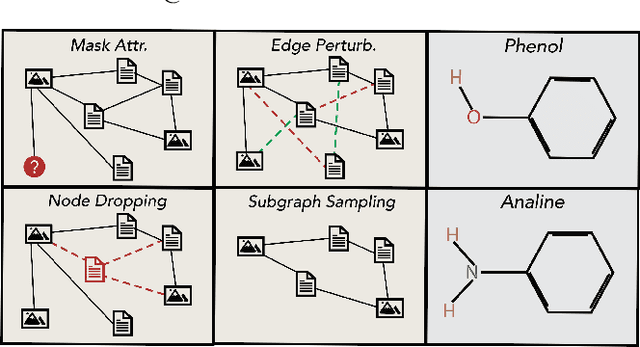
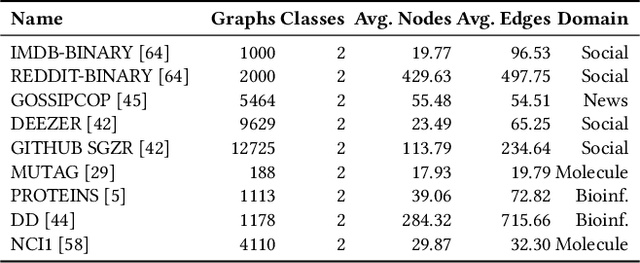
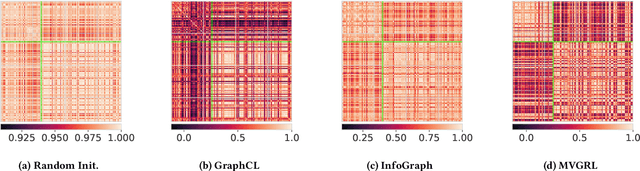
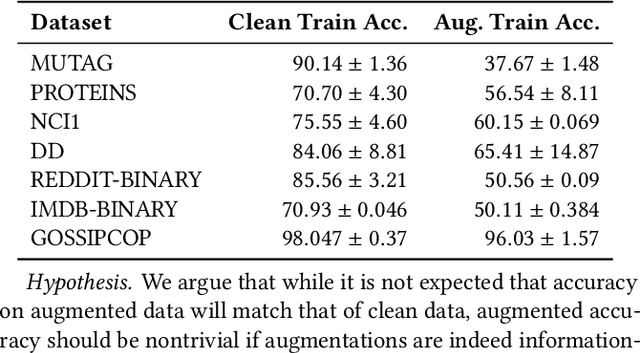
Graph classification has applications in bioinformatics, social sciences, automated fake news detection, web document classification, and more. In many practical scenarios, including web-scale applications, where labels are scarce or hard to obtain, unsupervised learning is a natural paradigm but it trades off performance. Recently, contrastive learning (CL) has enabled unsupervised computer vision models to compete well against supervised ones. Theoretical and empirical works analyzing visual CL frameworks find that leveraging large datasets and domain aware augmentations is essential for framework success. Interestingly, graph CL frameworks often report high performance while using orders of magnitude smaller data, and employing domain-agnostic augmentations (e.g., node or edge dropping, feature perturbations) that can corrupt the graphs' underlying properties. Motivated by these discrepancies, we seek to determine: (i) why existing graph CL frameworks perform well despite weak augmentations and limited data; and (ii) whether adhering to visual CL principles can improve performance on graph classification tasks. Through extensive analysis, we identify flawed practices in graph data augmentation and evaluation protocols that are commonly used in the graph CL literature, and propose improved practices and sanity checks for future research and applications. We show that on small benchmark datasets, the inductive bias of graph neural networks can significantly compensate for the limitations of existing frameworks. In case studies with relatively larger graph classification tasks, we find that commonly used domain-agnostic augmentations perform poorly, while adhering to principles in visual CL can significantly improve performance. For example, in graph-based document classification, which can be used for better web search, we show task-relevant augmentations improve accuracy by 20%.