 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024



Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Automatic WordNet Construction using Word Sense Induction through Sentence Embeddings
Apr 07, 2022
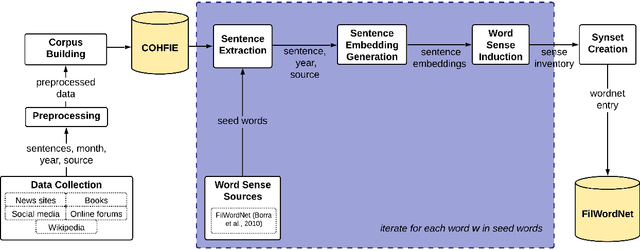
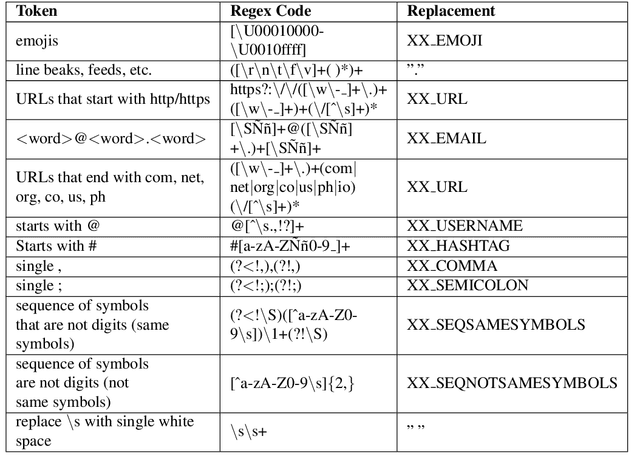
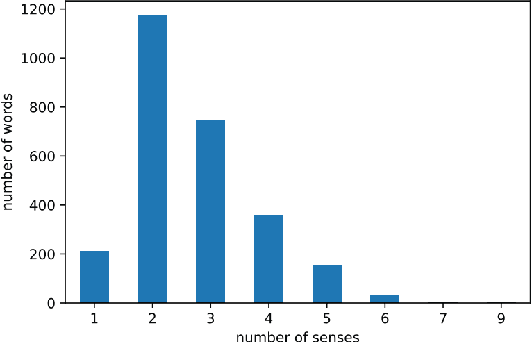
Language resources such as wordnets remain indispensable tools for different natural language tasks and applications. However, for low-resource languages such as Filipino, existing wordnets are old and outdated, and producing new ones may be slow and costly in terms of time and resources. In this paper, we propose an automatic method for constructing a wordnet from scratch using only an unlabeled corpus and a sentence embeddings-based language model. Using this, we produce FilWordNet, a new wordnet that supplants and improves the outdated Filipino WordNet. We evaluate our automatically-induced senses and synsets by matching them with senses from the Princeton WordNet, as well as comparing the synsets to the old Filipino WordNet. We empirically show that our method can induce existing, as well as potentially new, senses and synsets automatically without the need for human supervision.
Investigating the True Performance of Transformers in Low-Resource Languages: A Case Study in Automatic Corpus Creation
Oct 22, 2020
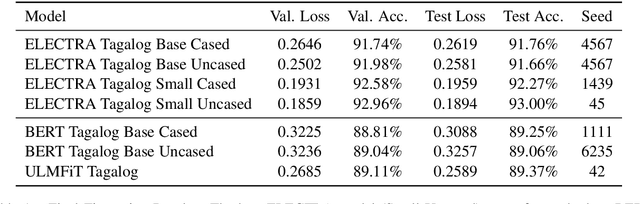
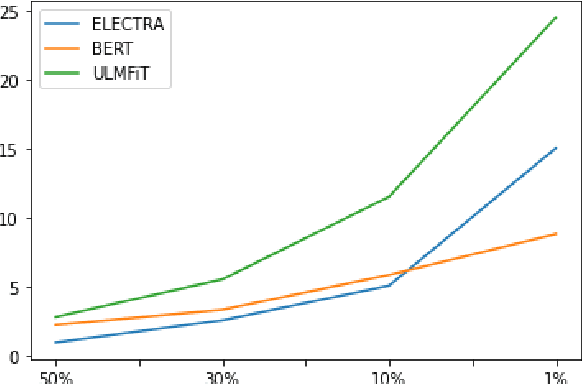
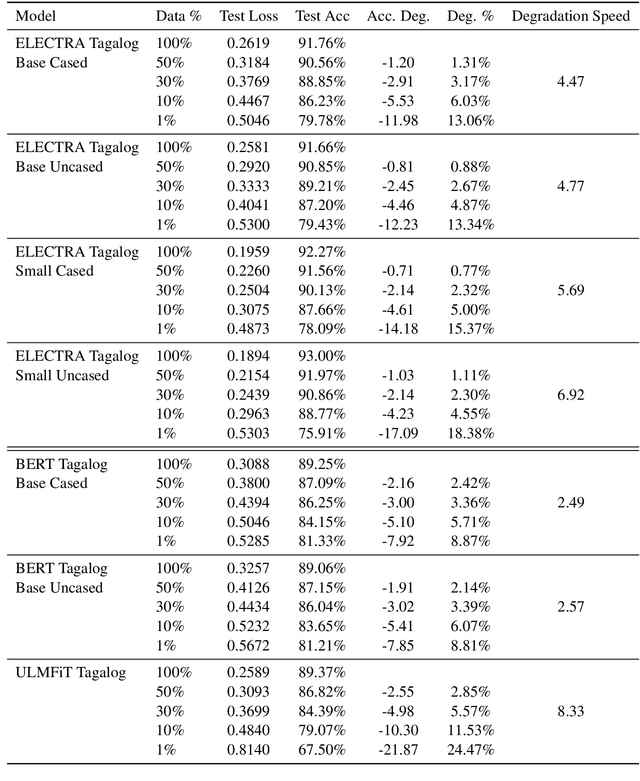
Transformers represent the state-of-the-art in Natural Language Processing (NLP) in recent years, proving effective even in tasks done in low-resource languages. While pretrained transformers for these languages can be made, it is challenging to measure their true performance and capacity due to the lack of hard benchmark datasets, as well as the difficulty and cost of producing them. In this paper, we present three contributions: First, we propose a methodology for automatically producing Natural Language Inference (NLI) benchmark datasets for low-resource languages using published news articles. Through this, we create and release NewsPH-NLI, the first sentence entailment benchmark dataset in the low-resource Filipino language. Second, we produce new pretrained transformers based on the ELECTRA technique to further alleviate the resource scarcity in Filipino, benchmarking them on our dataset against other commonly-used transfer learning techniques. Lastly, we perform analyses on transfer learning techniques to shed light on their true performance when operating in low-data domains through the use of degradation tests.
Pagsusuri ng RNN-based Transfer Learning Technique sa Low-Resource Language
Oct 14, 2020
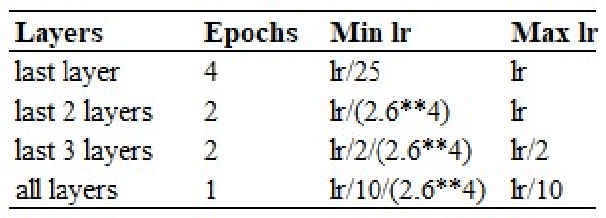


Low-resource languages such as Filipino suffer from data scarcity which makes it challenging to develop NLP applications for Filipino language. The use of Transfer Learning (TL) techniques alleviates this problem in low-resource setting. In recent years, transformer-based models are proven to be effective in low-resource tasks but faces challenges in accessibility due to its high compute and memory requirements. For this reason, there's a need for a cheaper but effective alternative. This paper has three contributions. First, release a pre-trained AWD-LSTM language model for Filipino language. Second, benchmark AWD-LSTM in the Hate Speech classification task and show that it performs on par with transformer-based models. Third, analyze the the performance of AWD-LSTM in low-resource setting using degradation test and compare it with transformer-based models. ----- Ang mga low-resource languages tulad ng Filipino ay gipit sa accessible na datos kaya't mahirap gumawa ng mga applications sa wikang ito. Ang mga Transfer Learning (TL) techniques ay malaking tulong para sa low-resource setting o mga pagkakataong gipit sa datos. Sa mga nagdaang taon, nanaig ang mga transformer-based TL techniques pagdating sa low-resource tasks ngunit ito ay mataas na compute and memory requirements kaya nangangailangan ng mas mura pero epektibong alternatibo. Ang papel na ito ay may tatlong kontribusyon. Una, maglabas ng pre-trained AWD-LSTM language model sa wikang Filipino upang maging tuntungan sa pagbuo ng mga NLP applications sa wikang Filipino. Pangalawa, mag benchmark ng AWD-LSTM sa Hate Speech classification task at ipakita na kayang nitong makipagsabayan sa mga transformer-based models. Pangatlo, suriin ang performance ng AWD-LSTM sa low-resource setting gamit ang degradation test at ikumpara ito sa mga transformer-based models.