 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOReole-FM: successes and challenges toward billion-parameter foundation models for high-resolution satellite imagery
Oct 25, 2024While the pretraining of Foundation Models (FMs) for remote sensing (RS) imagery is on the rise, models remain restricted to a few hundred million parameters. Scaling models to billions of parameters has been shown to yield unprecedented benefits including emergent abilities, but requires data scaling and computing resources typically not available outside industry R&D labs. In this work, we pair high-performance computing resources including Frontier supercomputer, America's first exascale system, and high-resolution optical RS data to pretrain billion-scale FMs. Our study assesses performance of different pretrained variants of vision Transformers across image classification, semantic segmentation and object detection benchmarks, which highlight the importance of data scaling for effective model scaling. Moreover, we discuss construction of a novel TIU pretraining dataset, model initialization, with data and pretrained models intended for public release. By discussing technical challenges and details often lacking in the related literature, this work is intended to offer best practices to the geospatial community toward efficient training and benchmarking of larger FMs.
Pretraining Billion-scale Geospatial Foundational Models on Frontier
Apr 17, 2024



As AI workloads increase in scope, generalization capability becomes challenging for small task-specific models and their demand for large amounts of labeled training samples increases. On the contrary, Foundation Models (FMs) are trained with internet-scale unlabeled data via self-supervised learning and have been shown to adapt to various tasks with minimal fine-tuning. Although large FMs have demonstrated significant impact in natural language processing and computer vision, efforts toward FMs for geospatial applications have been restricted to smaller size models, as pretraining larger models requires very large computing resources equipped with state-of-the-art hardware accelerators. Current satellite constellations collect 100+TBs of data a day, resulting in images that are billions of pixels and multimodal in nature. Such geospatial data poses unique challenges opening up new opportunities to develop FMs. We investigate billion scale FMs and HPC training profiles for geospatial applications by pretraining on publicly available data. We studied from end-to-end the performance and impact in the solution by scaling the model size. Our larger 3B parameter size model achieves up to 30% improvement in top1 scene classification accuracy when comparing a 100M parameter model. Moreover, we detail performance experiments on the Frontier supercomputer, America's first exascale system, where we study different model and data parallel approaches using PyTorch's Fully Sharded Data Parallel library. Specifically, we study variants of the Vision Transformer architecture (ViT), conducting performance analysis for ViT models with size up to 15B parameters. By discussing throughput and performance bottlenecks under different parallelism configurations, we offer insights on how to leverage such leadership-class HPC resources when developing large models for geospatial imagery applications.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
Proceedings of KDD 2021 Workshop on Data-driven Humanitarian Mapping: Harnessing Human-Machine Intelligence for High-Stake Public Policy and Resilience Planning
Sep 07, 2021Humanitarian challenges, including natural disasters, food insecurity, climate change, racial and gender violence, environmental crises, the COVID-19 coronavirus pandemic, human rights violations, and forced displacements, disproportionately impact vulnerable communities worldwide. According to UN OCHA, 235 million people will require humanitarian assistance in 2021. Despite these growing perils, there remains a notable paucity of data science research to scientifically inform equitable public policy decisions for improving the livelihood of at-risk populations. Scattered data science efforts exist to address these challenges, but they remain isolated from practice and prone to algorithmic harms concerning lack of privacy, fairness, interpretability, accountability, transparency, and ethics. Biases in data-driven methods carry the risk of amplifying inequalities in high-stakes policy decisions that impact the livelihood of millions of people. Consequently, proclaimed benefits of data-driven innovations remain inaccessible to policymakers, practitioners, and marginalized communities at the core of humanitarian actions and global development. To help fill this gap, we propose the Data-driven Humanitarian Mapping Research Program, which focuses on developing novel data science methodologies that harness human-machine intelligence for high-stakes public policy and resilience planning. The proceedings of the 2nd Data-driven Humanitarian Mapping workshop at the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. August 15th, 2021
Proceedings of KDD 2020 Workshop on Data-driven Humanitarian Mapping: Harnessing Human-Machine Intelligence for High-Stake Public Policy and Resilience Planning
Sep 07, 2021Humanitarian challenges, including natural disasters, food insecurity, climate change, racial and gender violence, environmental crises, the COVID-19 coronavirus pandemic, human rights violations, and forced displacements, disproportionately impact vulnerable communities worldwide. According to UN OCHA, 235 million people will require humanitarian assistance in 2021 . Despite these growing perils, there remains a notable paucity of data science research to scientifically inform equitable public policy decisions for improving the livelihood of at-risk populations. Scattered data science efforts exist to address these challenges, but they remain isolated from practice and prone to algorithmic harms concerning lack of privacy, fairness, interpretability, accountability, transparency, and ethics. Biases in data-driven methods carry the risk of amplifying inequalities in high-stakes policy decisions that impact the livelihood of millions of people. Consequently, proclaimed benefits of data-driven innovations remain inaccessible to policymakers, practitioners, and marginalized communities at the core of humanitarian actions and global development. To help fill this gap, we propose the Data-driven Humanitarian Mapping Research Program, which focuses on developing novel data science methodologies that harness human-machine intelligence for high-stakes public policy and resilience planning. The proceedings of the 1st Data-driven Humanitarian Mapping workshop at the 26th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, August 24th, 2020.
Computer-aided abnormality detection in chest radiographs in a clinical setting via domain-adaptation
Dec 19, 2020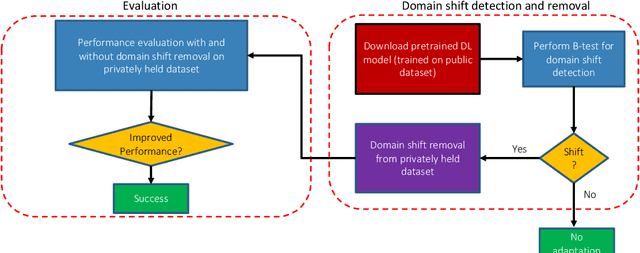
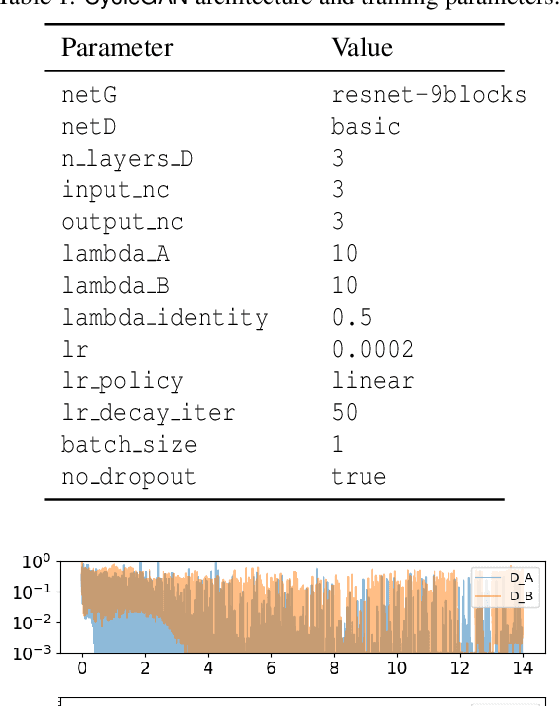
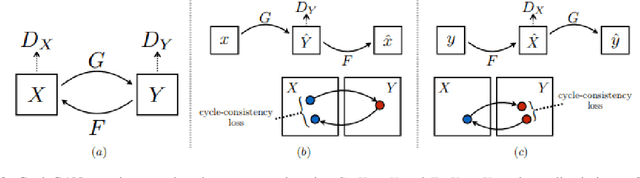
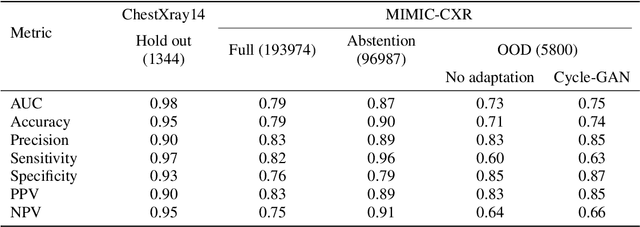
Deep learning (DL) models are being deployed at medical centers to aid radiologists for diagnosis of lung conditions from chest radiographs. Such models are often trained on a large volume of publicly available labeled radiographs. These pre-trained DL models' ability to generalize in clinical settings is poor because of the changes in data distributions between publicly available and privately held radiographs. In chest radiographs, the heterogeneity in distributions arises from the diverse conditions in X-ray equipment and their configurations used for generating the images. In the machine learning community, the challenges posed by the heterogeneity in the data generation source is known as domain shift, which is a mode shift in the generative model. In this work, we introduce a domain-shift detection and removal method to overcome this problem. Our experimental results show the proposed method's effectiveness in deploying a pre-trained DL model for abnormality detection in chest radiographs in a clinical setting.
Apache Spark Accelerated Deep Learning Inference for Large Scale Satellite Image Analytics
Aug 08, 2019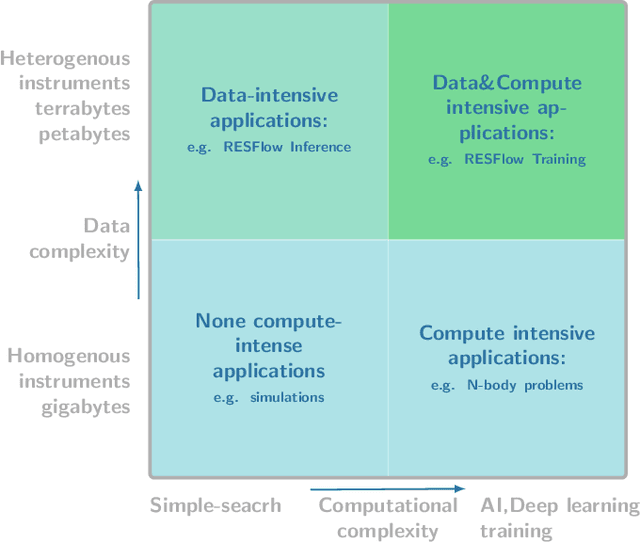


The shear volumes of data generated from earth observation and remote sensing technologies continue to make major impact; leaping key geospatial applications into the dual data and compute intensive era. As a consequence, this rapid advancement poses new computational and data processing challenges. We implement a novel remote sensing data flow (RESFlow) for advanced machine learning and computing with massive amounts of remotely sensed imagery. The core contribution is partitioning massive amount of data based on the spectral and semantic characteristics for distributed imagery analysis. RESFlow takes advantage of both a unified analytics engine for large-scale data processing and the availability of modern computing hardware to harness the acceleration of deep learning inference on expansive remote sensing imagery. The framework incorporates a strategy to optimize resource utilization across multiple executors assigned to a single worker. We showcase its deployment across computationally and data-intensive on pixel-level labeling workloads. The pipeline invokes deep learning inference at three stages; during deep feature extraction, deep metric mapping, and deep semantic segmentation. The tasks impose compute intensive and GPU resource sharing challenges motivating for a parallelized pipeline for all execution steps. By taking advantage of Apache Spark, Nvidia DGX1, and DGX2 computing platforms, we demonstrate unprecedented compute speed-ups for deep learning inference on pixel labeling workloads; processing 21,028~Terrabytes of imagery data and delivering an output maps at area rate of 5.245sq.km/sec, amounting to 453,168 sq.km/day - reducing a 28 day workload to 21~hours.
Building Extraction at Scale using Convolutional Neural Network: Mapping of the United States
May 23, 2018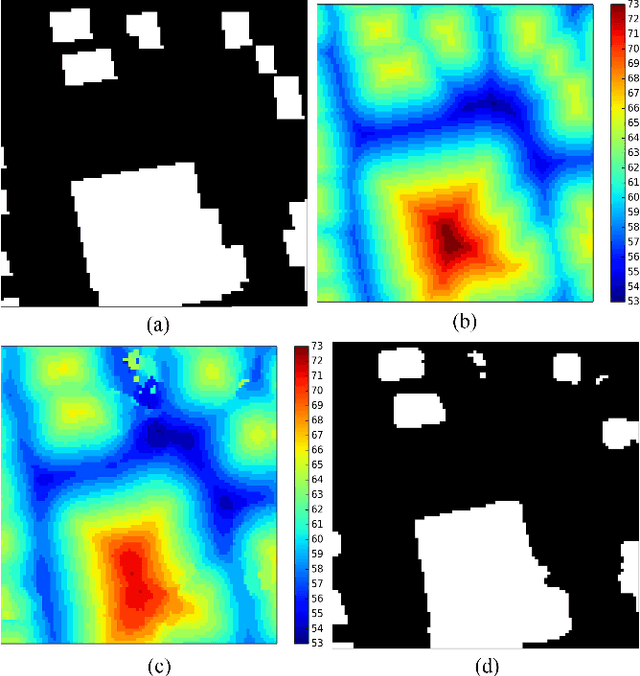
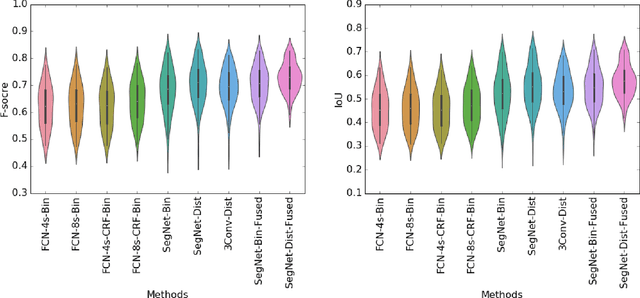
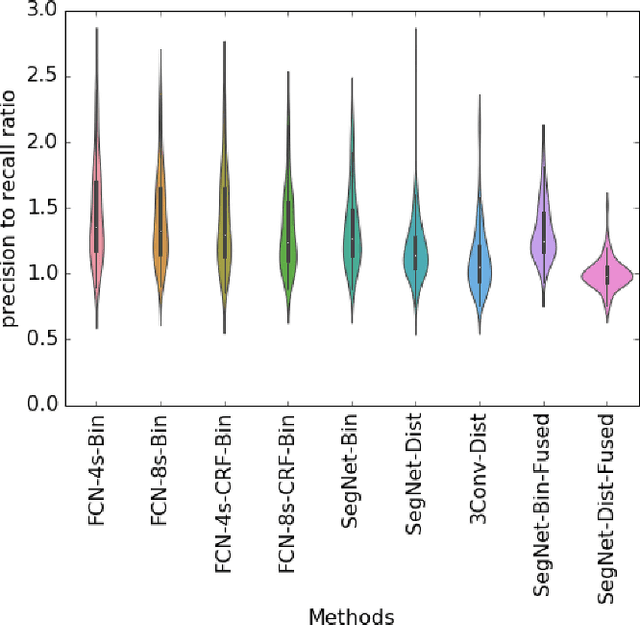
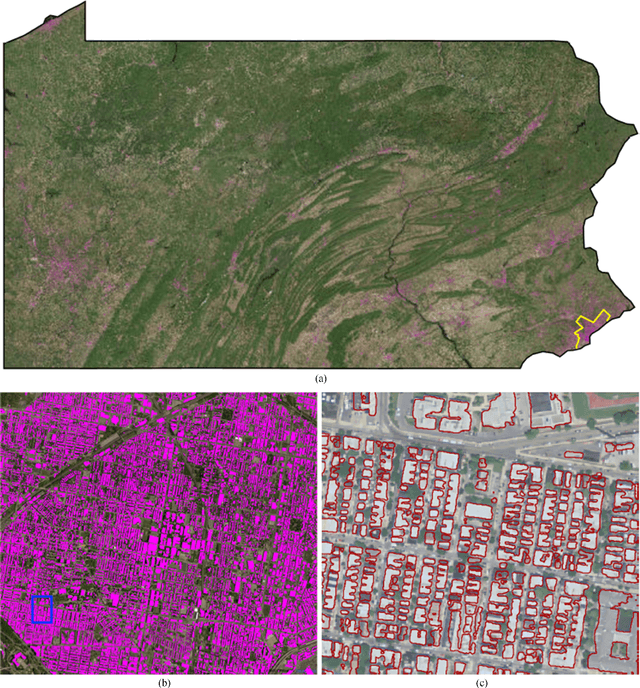
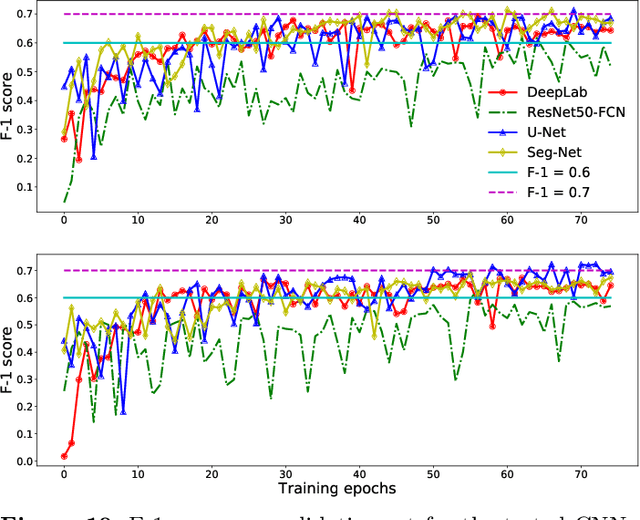
Establishing up-to-date large scale building maps is essential to understand urban dynamics, such as estimating population, urban planning and many other applications. Although many computer vision tasks has been successfully carried out with deep convolutional neural networks, there is a growing need to understand their large scale impact on building mapping with remote sensing imagery. Taking advantage of the scalability of CNNs and using only few areas with the abundance of building footprints, for the first time we conduct a comparative analysis of four state-of-the-art CNNs for extracting building footprints across the entire continental United States. The four CNN architectures namely: branch-out CNN, fully convolutional neural network (FCN), conditional random field as recurrent neural network (CRFasRNN), and SegNet, support semantic pixel-wise labeling and focus on capturing textural information at multi-scale. We use 1-meter resolution aerial images from National Agriculture Imagery Program (NAIP) as the test-bed, and compare the extraction results across the four methods. In addition, we propose to combine signed-distance labels with SegNet, the preferred CNN architecture identified by our extensive evaluations, to advance building extraction results to instance level. We further demonstrate the usefulness of fusing additional near IR information into the building extraction framework. Large scale experimental evaluations are conducted and reported using metrics that include: precision, recall rate, intersection over union, and the number of buildings extracted. With the improved CNN model and no requirement of further post-processing, we have generated building maps for the United States. The quality of extracted buildings and processing time demonstrated the proposed CNN-based framework fits the need of building extraction at scale.
Hashed Binary Search Sampling for Convolutional Network Training with Large Overhead Image Patches
Jul 18, 2017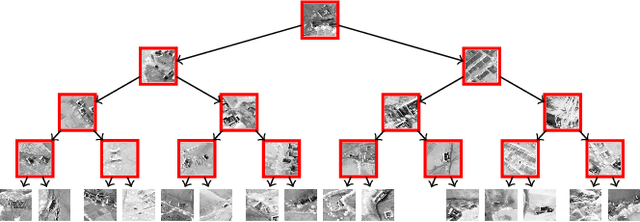
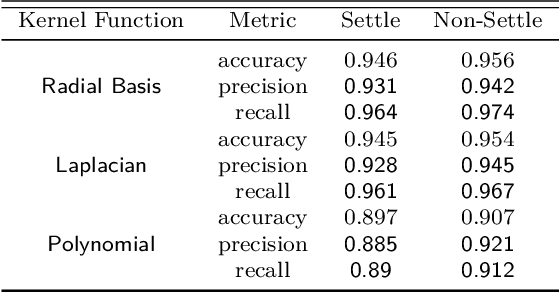
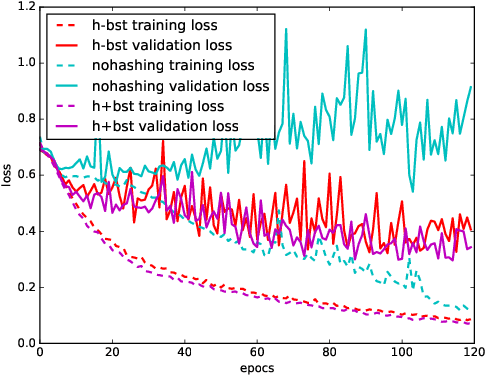

Very large overhead imagery associated with ground truth maps has the potential to generate billions of training image patches for machine learning algorithms. However, random sampling selection criteria often leads to redundant and noisy-image patches for model training. With minimal research efforts behind this challenge, the current status spells missed opportunities to develop supervised learning algorithms that generalize over wide geographical scenes. In addition, much of the computational cycles for large scale machine learning are poorly spent crunching through noisy and redundant image patches. We demonstrate a potential framework to address these challenges specifically, while evaluating a human settlement detection task. A novel binary search tree sampling scheme is fused with a kernel based hashing procedure that maps image patches into hash-buckets using binary codes generated from image content. The framework exploits inherent redundancy within billions of image patches to promote mostly high variance preserving samples for accelerating algorithmic training and increasing model generalization.
Exploiting Convolutional Representations for Multiscale Human Settlement Detection
Jul 18, 2017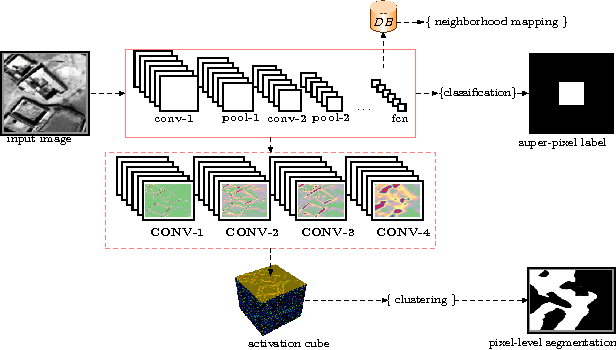

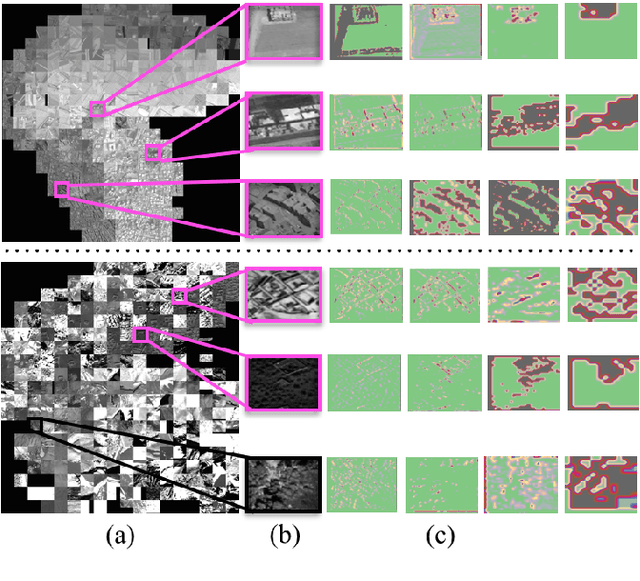
We test this premise and explore representation spaces from a single deep convolutional network and their visualization to argue for a novel unified feature extraction framework. The objective is to utilize and re-purpose trained feature extractors without the need for network retraining on three remote sensing tasks i.e. superpixel mapping, pixel-level segmentation and semantic based image visualization. By leveraging the same convolutional feature extractors and viewing them as visual information extractors that encode different image representation spaces, we demonstrate a preliminary inductive transfer learning potential on multiscale experiments that incorporate edge-level details up to semantic-level information.