 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Casual Conversations v2 Dataset
Mar 08, 2023



This paper introduces a new large consent-driven dataset aimed at assisting in the evaluation of algorithmic bias and robustness of computer vision and audio speech models in regards to 11 attributes that are self-provided or labeled by trained annotators. The dataset includes 26,467 videos of 5,567 unique paid participants, with an average of almost 5 videos per person, recorded in Brazil, India, Indonesia, Mexico, Vietnam, Philippines, and the USA, representing diverse demographic characteristics. The participants agreed for their data to be used in assessing fairness of AI models and provided self-reported age, gender, language/dialect, disability status, physical adornments, physical attributes and geo-location information, while trained annotators labeled apparent skin tone using the Fitzpatrick Skin Type and Monk Skin Tone scales, and voice timbre. Annotators also labeled for different recording setups and per-second activity annotations.
A Whac-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others
Dec 09, 2022



Machine learning models have been found to learn shortcuts -- unintended decision rules that are unable to generalize -- undermining models' reliability. Previous works address this problem under the tenuous assumption that only a single shortcut exists in the training data. Real-world images are rife with multiple visual cues from background to texture. Key to advancing the reliability of vision systems is understanding whether existing methods can overcome multiple shortcuts or struggle in a Whac-A-Mole game, i.e., where mitigating one shortcut amplifies reliance on others. To address this shortcoming, we propose two benchmarks: 1) UrbanCars, a dataset with precisely controlled spurious cues, and 2) ImageNet-W, an evaluation set based on ImageNet for watermark, a shortcut we discovered affects nearly every modern vision model. Along with texture and background, ImageNet-W allows us to study multiple shortcuts emerging from training on natural images. We find computer vision models, including large foundation models -- regardless of training set, architecture, and supervision -- struggle when multiple shortcuts are present. Even methods explicitly designed to combat shortcuts struggle in a Whac-A-Mole dilemma. To tackle this challenge, we propose Last Layer Ensemble, a simple-yet-effective method to mitigate multiple shortcuts without Whac-A-Mole behavior. Our results surface multi-shortcut mitigation as an overlooked challenge critical to advancing the reliability of vision systems. The datasets and code are released: https://github.com/facebookresearch/Whac-A-Mole.git.
Casual Conversations v2: Designing a large consent-driven dataset to measure algorithmic bias and robustness
Nov 10, 2022



Developing robust and fair AI systems require datasets with comprehensive set of labels that can help ensure the validity and legitimacy of relevant measurements. Recent efforts, therefore, focus on collecting person-related datasets that have carefully selected labels, including sensitive characteristics, and consent forms in place to use those attributes for model testing and development. Responsible data collection involves several stages, including but not limited to determining use-case scenarios, selecting categories (annotations) such that the data are fit for the purpose of measuring algorithmic bias for subgroups and most importantly ensure that the selected categories/subcategories are robust to regional diversities and inclusive of as many subgroups as possible. Meta, in a continuation of our efforts to measure AI algorithmic bias and robustness (https://ai.facebook.com/blog/shedding-light-on-fairness-in-ai-with-a-new-data-set), is working on collecting a large consent-driven dataset with a comprehensive list of categories. This paper describes our proposed design of such categories and subcategories for Casual Conversations v2.
Generating High Fidelity Data from Low-density Regions using Diffusion Models
Mar 31, 2022
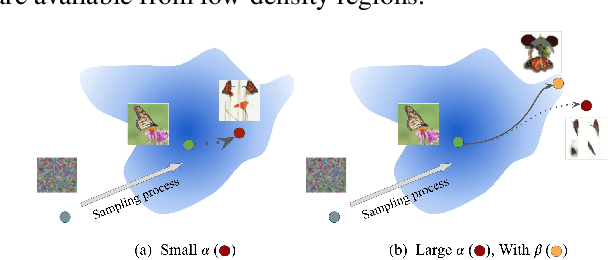

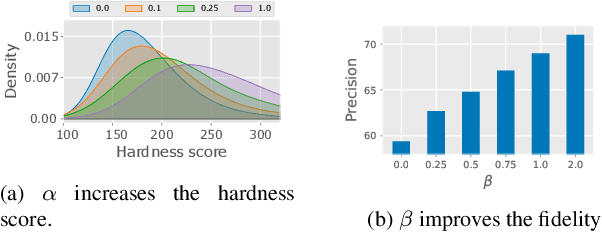
Our work focuses on addressing sample deficiency from low-density regions of data manifold in common image datasets. We leverage diffusion process based generative models to synthesize novel images from low-density regions. We observe that uniform sampling from diffusion models predominantly samples from high-density regions of the data manifold. Therefore, we modify the sampling process to guide it towards low-density regions while simultaneously maintaining the fidelity of synthetic data. We rigorously demonstrate that our process successfully generates novel high fidelity samples from low-density regions. We further examine generated samples and show that the model does not memorize low-density data and indeed learns to generate novel samples from low-density regions.
Results and findings of the 2021 Image Similarity Challenge
Feb 08, 2022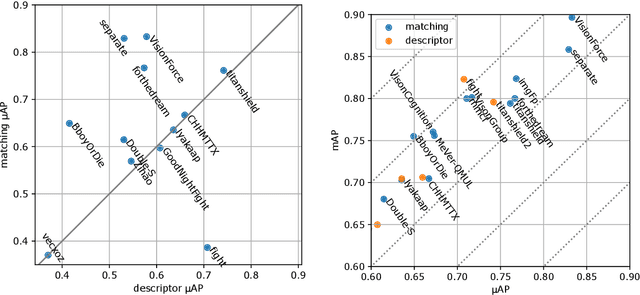
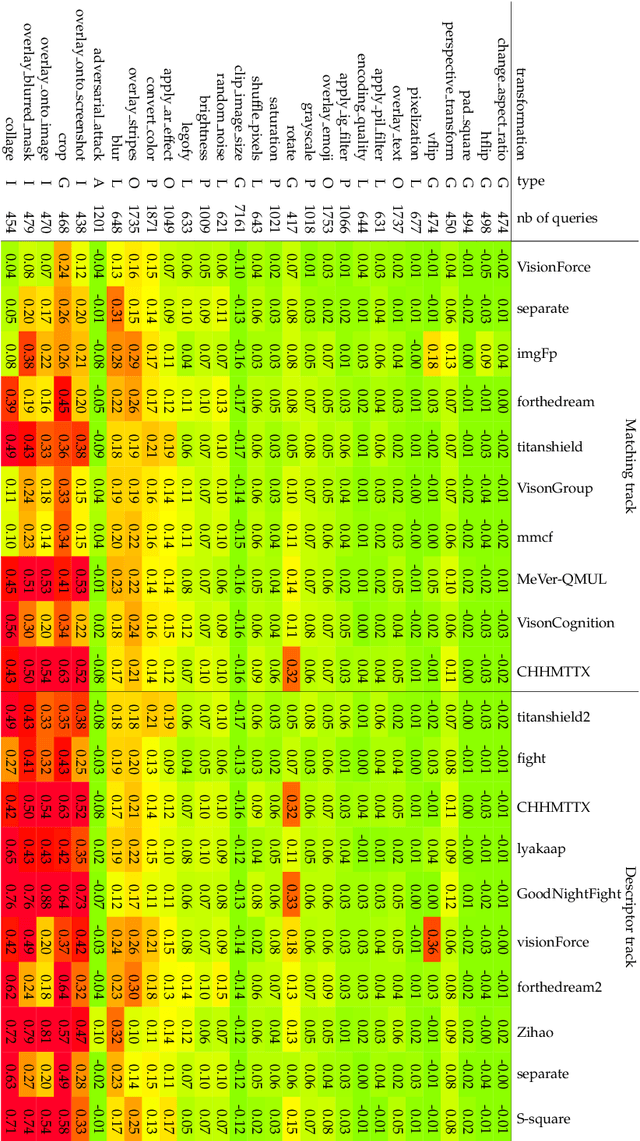
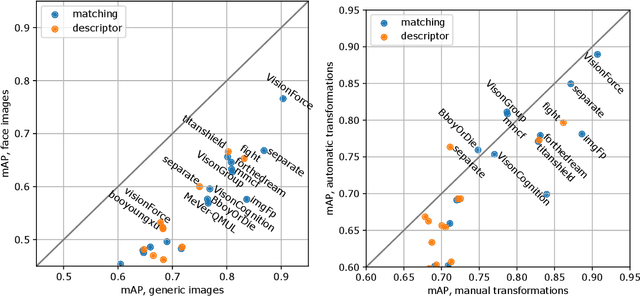
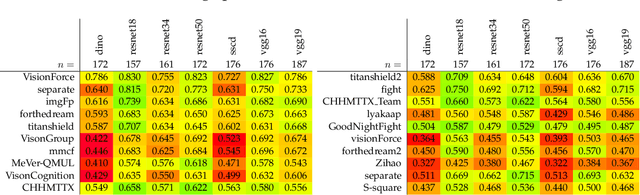
The 2021 Image Similarity Challenge introduced a dataset to serve as a new benchmark to evaluate recent image copy detection methods. There were 200 participants to the competition. This paper presents a quantitative and qualitative analysis of the top submissions. It appears that the most difficult image transformations involve either severe image crops or hiding into unrelated images, combined with local pixel perturbations. The key algorithmic elements in the winning submissions are: training on strong augmentations, self-supervised learning, score normalization, explicit overlay detection, and global descriptor matching followed by pairwise image comparison.
The 2021 Image Similarity Dataset and Challenge
Jul 01, 2021
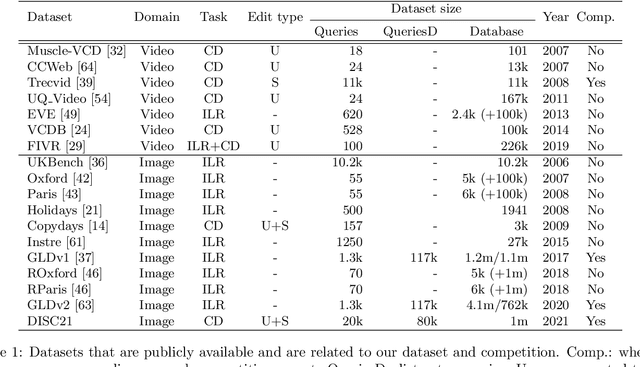
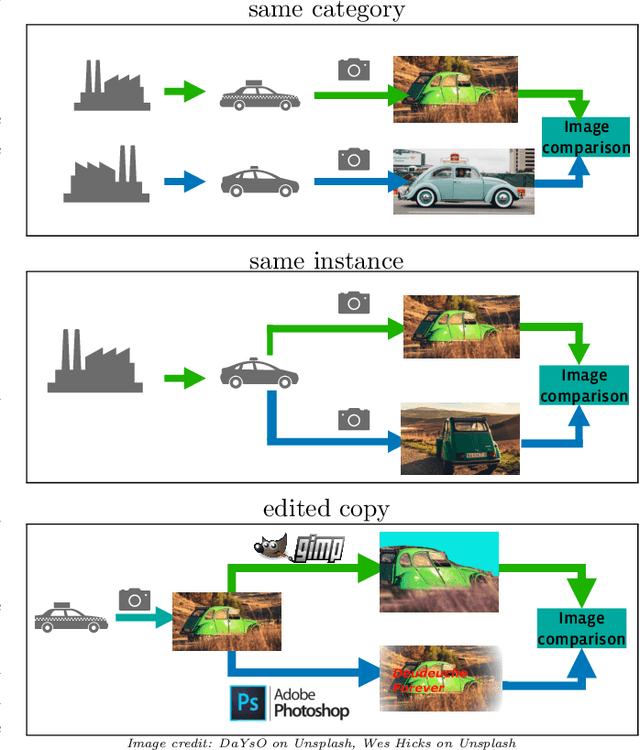

This paper introduces a new benchmark for large-scale image similarity detection. This benchmark is used for the Image Similarity Challenge at NeurIPS'21 (ISC2021). The goal is to determine whether a query image is a modified copy of any image in a reference corpus of size 1~million. The benchmark features a variety of image transformations such as automated transformations, hand-crafted image edits and machine-learning based manipulations. This mimics real-life cases appearing in social media, for example for integrity-related problems dealing with misinformation and objectionable content. The strength of the image manipulations, and therefore the difficulty of the benchmark, is calibrated according to the performance of a set of baseline approaches. Both the query and reference set contain a majority of "distractor" images that do not match, which corresponds to a real-life needle-in-haystack setting, and the evaluation metric reflects that. We expect the DISC21 benchmark to promote image copy detection as an important and challenging computer vision task and refresh the state of the art.
Localized Uncertainty Attacks
Jun 17, 2021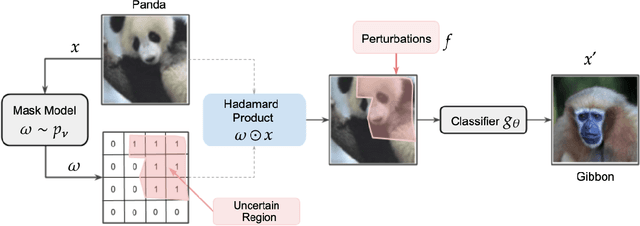
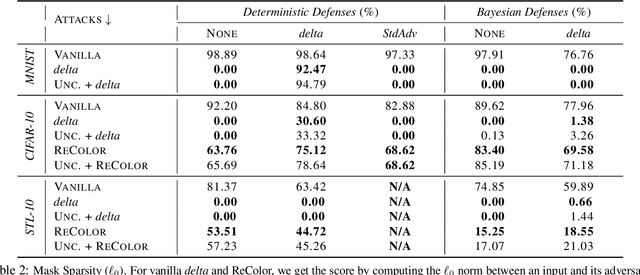
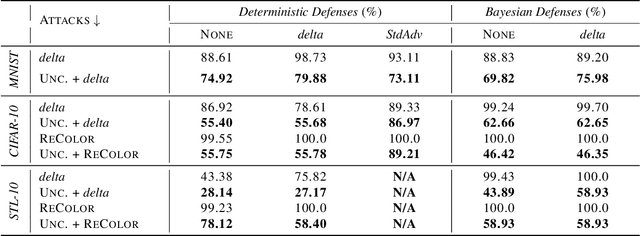

The susceptibility of deep learning models to adversarial perturbations has stirred renewed attention in adversarial examples resulting in a number of attacks. However, most of these attacks fail to encompass a large spectrum of adversarial perturbations that are imperceptible to humans. In this paper, we present localized uncertainty attacks, a novel class of threat models against deterministic and stochastic classifiers. Under this threat model, we create adversarial examples by perturbing only regions in the inputs where a classifier is uncertain. To find such regions, we utilize the predictive uncertainty of the classifier when the classifier is stochastic or, we learn a surrogate model to amortize the uncertainty when it is deterministic. Unlike $\ell_p$ ball or functional attacks which perturb inputs indiscriminately, our targeted changes can be less perceptible. When considered under our threat model, these attacks still produce strong adversarial examples; with the examples retaining a greater degree of similarity with the inputs.
Towards measuring fairness in AI: the Casual Conversations dataset
Apr 06, 2021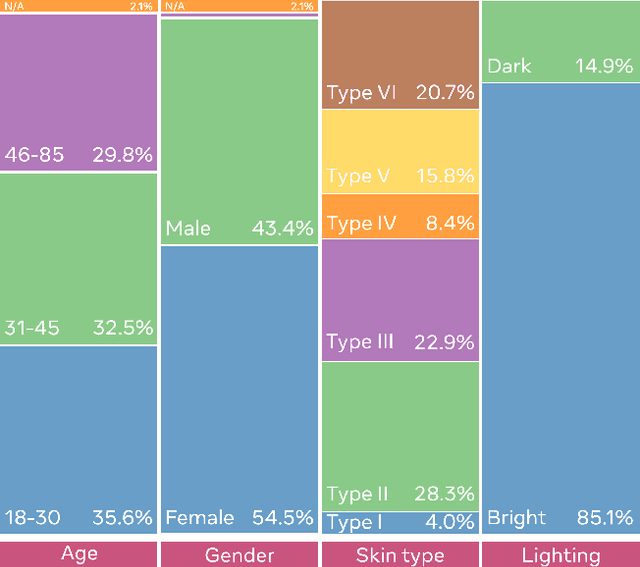



This paper introduces a novel dataset to help researchers evaluate their computer vision and audio models for accuracy across a diverse set of age, genders, apparent skin tones and ambient lighting conditions. Our dataset is composed of 3,011 subjects and contains over 45,000 videos, with an average of 15 videos per person. The videos were recorded in multiple U.S. states with a diverse set of adults in various age, gender and apparent skin tone groups. A key feature is that each subject agreed to participate for their likenesses to be used. Additionally, our age and gender annotations are provided by the subjects themselves. A group of trained annotators labeled the subjects' apparent skin tone using the Fitzpatrick skin type scale. Moreover, annotations for videos recorded in low ambient lighting are also provided. As an application to measure robustness of predictions across certain attributes, we provide a comprehensive study on the top five winners of the DeepFake Detection Challenge (DFDC). Experimental evaluation shows that the winning models are less performant on some specific groups of people, such as subjects with darker skin tones and thus may not generalize to all people. In addition, we also evaluate the state-of-the-art apparent age and gender classification methods. Our experiments provides a through analysis on these models in terms of fair treatment of people from various backgrounds.
Adversarial Evaluation of Multimodal Models under Realistic Gray Box Assumption
Nov 26, 2020
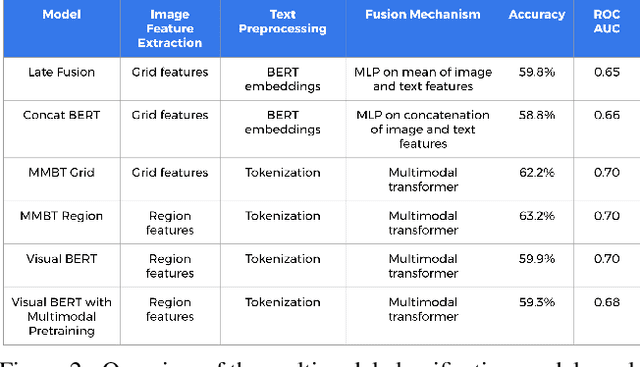
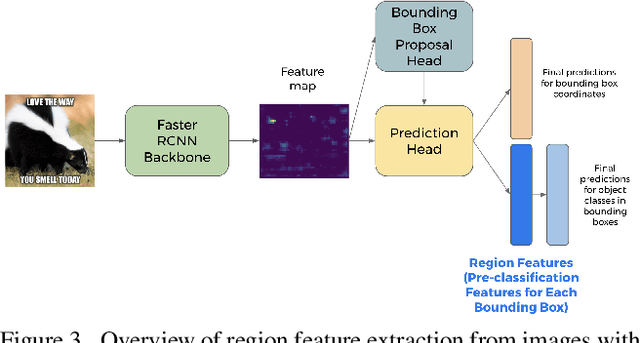

This work examines the vulnerability of multimodal (image + text) models to adversarial threats similar to those discussed in previous literature on unimodal (image- or text-only) models. We introduce realistic assumptions of partial model knowledge and access, and discuss how these assumptions differ from the standard "black-box"/"white-box" dichotomy common in current literature on adversarial attacks. Working under various levels of these "gray-box" assumptions, we develop new attack methodologies unique to multimodal classification and evaluate them on the Hateful Memes Challenge classification task. We find that attacking multiple modalities yields stronger attacks than unimodal attacks alone (inducing errors in up to 73% of cases), and that the unimodal image attacks on multimodal classifiers we explored were stronger than character-based text augmentation attacks (inducing errors on average in 45% and 30% of cases, respectively).
Adversarial Threats to DeepFake Detection: A Practical Perspective
Nov 19, 2020
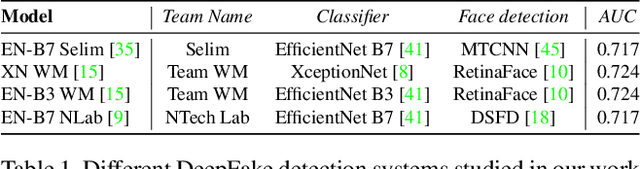
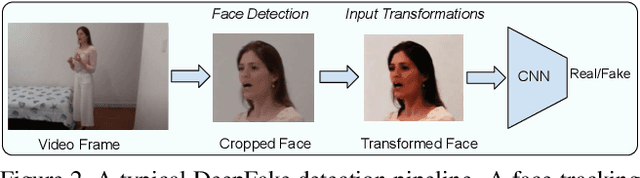

Facially manipulated images and videos or DeepFakes can be used maliciously to fuel misinformation or defame individuals. Therefore, detecting DeepFakes is crucial to increase the credibility of social media platforms and other media sharing web sites. State-of-the art DeepFake detection techniques rely on neural network based classification models which are known to be vulnerable to adversarial examples. In this work, we study the vulnerabilities of state-of-the-art DeepFake detection methods from a practical stand point. We perform adversarial attacks on DeepFake detectors in a black box setting where the adversary does not have complete knowledge of the classification models. We study the extent to which adversarial perturbations transfer across different models and propose techniques to improve the transferability of adversarial examples. We also create more accessible attacks using Universal Adversarial Perturbations which pose a very feasible attack scenario since they can be easily shared amongst attackers. We perform our evaluations on the winning entries of the DeepFake Detection Challenge (DFDC) and demonstrate that they can be easily bypassed in a practical attack scenario by designing transferable and accessible adversarial attacks.