 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Nucleus Truncation for Long-Form Reasoning
Jun 12, 2026Sampling plays an important role in long-form language-model reasoning. Over thousands of decoding steps, small changes in the candidate token set can compound into different reasoning trajectories, stability profiles, and final answers. Existing truncation methods such as top-$p$, min-$p$, and fixed top-$nσ$ sampling improve over unrestricted sampling, but they rely on fixed thresholds that cannot adapt to changes in entropy, task difficulty, training stage, or generation budget. We introduce Adaptive Nucleus Truncation Sampling (ANTS), which extends top-\(nσ\) sampling from a fixed decoding rule into an adaptive rollout-control mechanism for long-form generation. ANTS selects standardized neighborhoods around the maximum logit before temperature scaling, adapts the truncation width using an entropy-conditioned controller, and retains a no-truncation fallback arm to stabilize training when truncation becomes unsafe. On a 33B-total / 4B-active sparse Mixture-of-Experts reasoning model, ANTS improves average performance over percentage-based benchmarks by +1.9, +3.8, and +5.2 points at 8K, 16K, and 32K generation budgets, respectively. The strongest gains appear on instruction following and mathematical reasoning, with IFBench improving by more than 10 points at 32K and AIME 2025 improving by 7 points. Code generation reveals an important budget interaction. On Codeforces, ANTS trails the baseline at 8K, but reverses this gap and substantially improves ELO at 16K and 32K. These results suggest that sampler design should be treated not just as a decoding hyperparameter, but as part of how we stabilize and scale long-budget reasoning.
Variational Proximal Policy Optimization
Jun 06, 2026Reinforcement Learning from Human Feedback via Proximal Policy Optimization often suffers from policy mode collapse, brittle exploration loops, and distribution drift. This paper introduces Variational Proximal Policy Optimization (\(\textsc{VP}_2\textsc{O}\)), a particle-based variational inference framework that maps policy optimization to Stein Variational Gradient Descent within a Mixture-of-Experts architecture. By leveraging functional kernels over localized expert prototypes alongside an expert orthogonalization loss, \(\textsc{VP}_2\textsc{O}\) introduces a geometry-based proximal-control mechanism that can reduce reliance on fixed clipping or KL schedules. Our results on a 33B/4B sparse Mixture-of-Experts model show several improvements across complex reasoning benchmarks, establishing a \(+\mathbf{179}\) ELO gain on Codeforces and a \(\mathbf{32\%}\) reduction in token count on AIME mathematical reasoning tasks.
Localized Uncertainty Attacks
Jun 17, 2021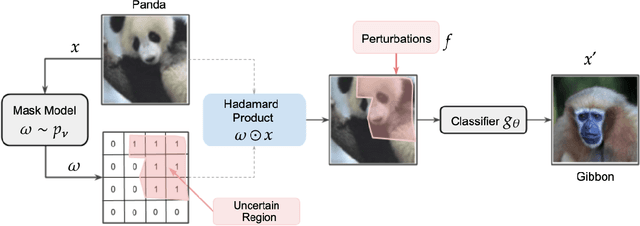
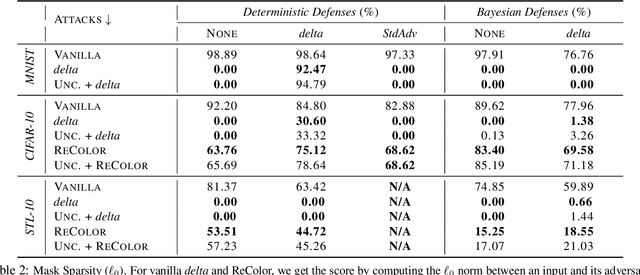
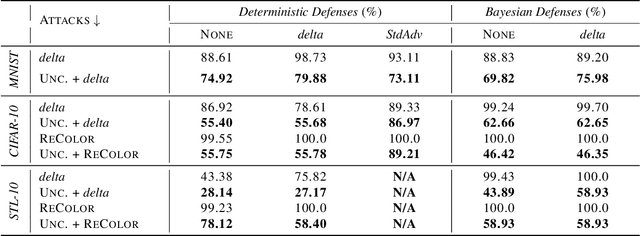

The susceptibility of deep learning models to adversarial perturbations has stirred renewed attention in adversarial examples resulting in a number of attacks. However, most of these attacks fail to encompass a large spectrum of adversarial perturbations that are imperceptible to humans. In this paper, we present localized uncertainty attacks, a novel class of threat models against deterministic and stochastic classifiers. Under this threat model, we create adversarial examples by perturbing only regions in the inputs where a classifier is uncertain. To find such regions, we utilize the predictive uncertainty of the classifier when the classifier is stochastic or, we learn a surrogate model to amortize the uncertainty when it is deterministic. Unlike $\ell_p$ ball or functional attacks which perturb inputs indiscriminately, our targeted changes can be less perceptible. When considered under our threat model, these attacks still produce strong adversarial examples; with the examples retaining a greater degree of similarity with the inputs.
Manifold Preserving Adversarial Learning
Mar 14, 2019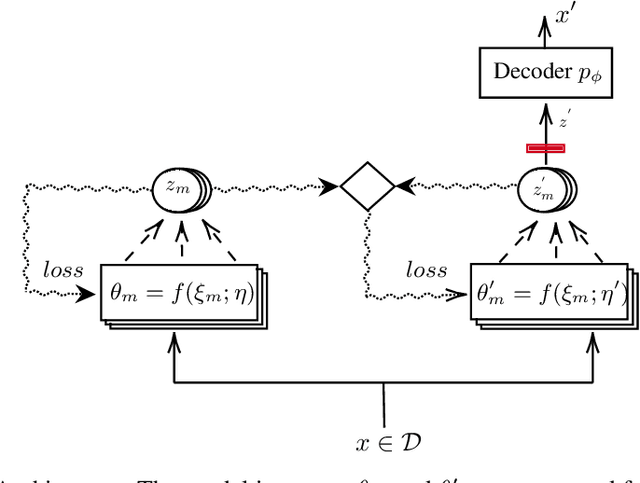

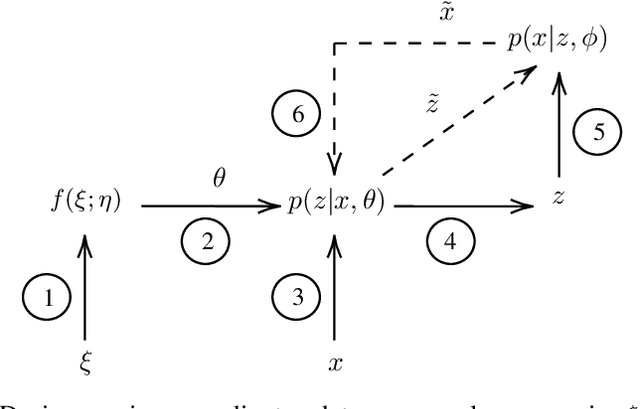

How to generate semantically meaningful and structurally sound adversarial examples? We propose to answer this question by restricting the search for adversaries in the true data manifold. To this end, we introduce a stochastic variational inference method to learn the data manifold, in the presence of continuous latent variables with intractable posterior distributions, without requiring an a priori form for the data underlying distribution. We then propose a manifold perturbation strategy that ensures the cases we perturb remain in the manifold of the original examples and thereby generate the adversaries. We evaluate our approach on a number of image and text datasets. Our results show the effectiveness of our approach in producing coherent, and realistic-looking adversaries that can evade strong defenses known to be resilient to traditional adversarial attacks