 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards measuring fairness in AI: the Casual Conversations dataset
Apr 06, 2021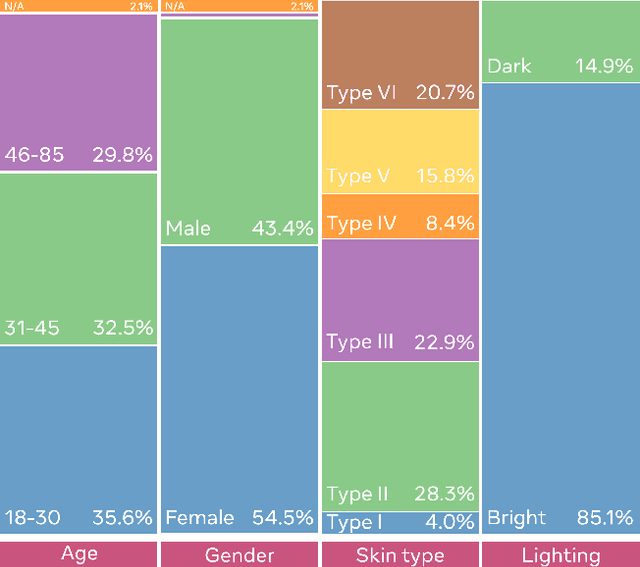



This paper introduces a novel dataset to help researchers evaluate their computer vision and audio models for accuracy across a diverse set of age, genders, apparent skin tones and ambient lighting conditions. Our dataset is composed of 3,011 subjects and contains over 45,000 videos, with an average of 15 videos per person. The videos were recorded in multiple U.S. states with a diverse set of adults in various age, gender and apparent skin tone groups. A key feature is that each subject agreed to participate for their likenesses to be used. Additionally, our age and gender annotations are provided by the subjects themselves. A group of trained annotators labeled the subjects' apparent skin tone using the Fitzpatrick skin type scale. Moreover, annotations for videos recorded in low ambient lighting are also provided. As an application to measure robustness of predictions across certain attributes, we provide a comprehensive study on the top five winners of the DeepFake Detection Challenge (DFDC). Experimental evaluation shows that the winning models are less performant on some specific groups of people, such as subjects with darker skin tones and thus may not generalize to all people. In addition, we also evaluate the state-of-the-art apparent age and gender classification methods. Our experiments provides a through analysis on these models in terms of fair treatment of people from various backgrounds.
Adversarial Evaluation of Multimodal Models under Realistic Gray Box Assumption
Nov 26, 2020
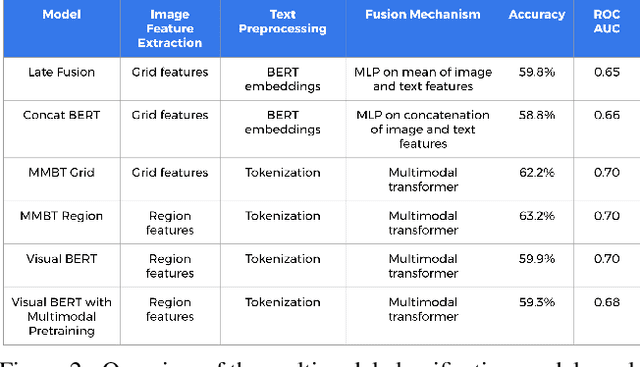
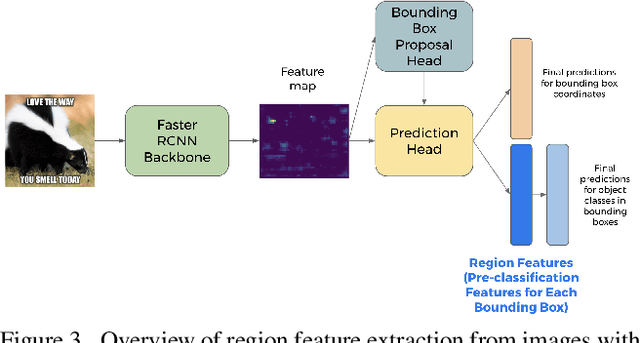

This work examines the vulnerability of multimodal (image + text) models to adversarial threats similar to those discussed in previous literature on unimodal (image- or text-only) models. We introduce realistic assumptions of partial model knowledge and access, and discuss how these assumptions differ from the standard "black-box"/"white-box" dichotomy common in current literature on adversarial attacks. Working under various levels of these "gray-box" assumptions, we develop new attack methodologies unique to multimodal classification and evaluate them on the Hateful Memes Challenge classification task. We find that attacking multiple modalities yields stronger attacks than unimodal attacks alone (inducing errors in up to 73% of cases), and that the unimodal image attacks on multimodal classifiers we explored were stronger than character-based text augmentation attacks (inducing errors on average in 45% and 30% of cases, respectively).
Adversarial Threats to DeepFake Detection: A Practical Perspective
Nov 19, 2020
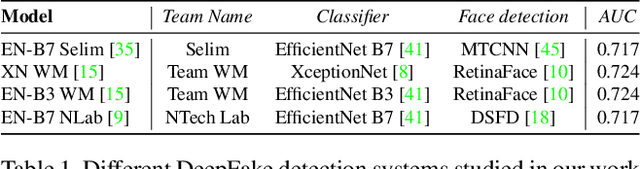
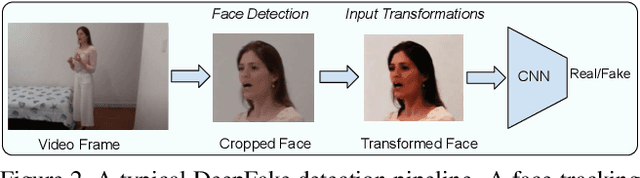

Facially manipulated images and videos or DeepFakes can be used maliciously to fuel misinformation or defame individuals. Therefore, detecting DeepFakes is crucial to increase the credibility of social media platforms and other media sharing web sites. State-of-the art DeepFake detection techniques rely on neural network based classification models which are known to be vulnerable to adversarial examples. In this work, we study the vulnerabilities of state-of-the-art DeepFake detection methods from a practical stand point. We perform adversarial attacks on DeepFake detectors in a black box setting where the adversary does not have complete knowledge of the classification models. We study the extent to which adversarial perturbations transfer across different models and propose techniques to improve the transferability of adversarial examples. We also create more accessible attacks using Universal Adversarial Perturbations which pose a very feasible attack scenario since they can be easily shared amongst attackers. We perform our evaluations on the winning entries of the DeepFake Detection Challenge (DFDC) and demonstrate that they can be easily bypassed in a practical attack scenario by designing transferable and accessible adversarial attacks.
Adversarial collision attacks on image hashing functions
Nov 18, 2020
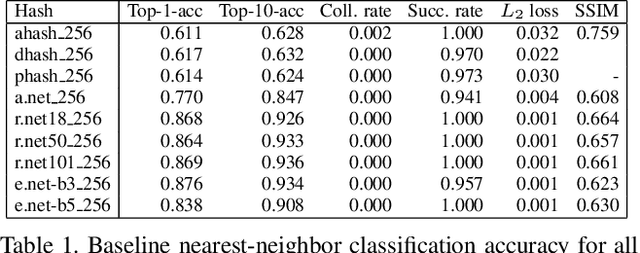
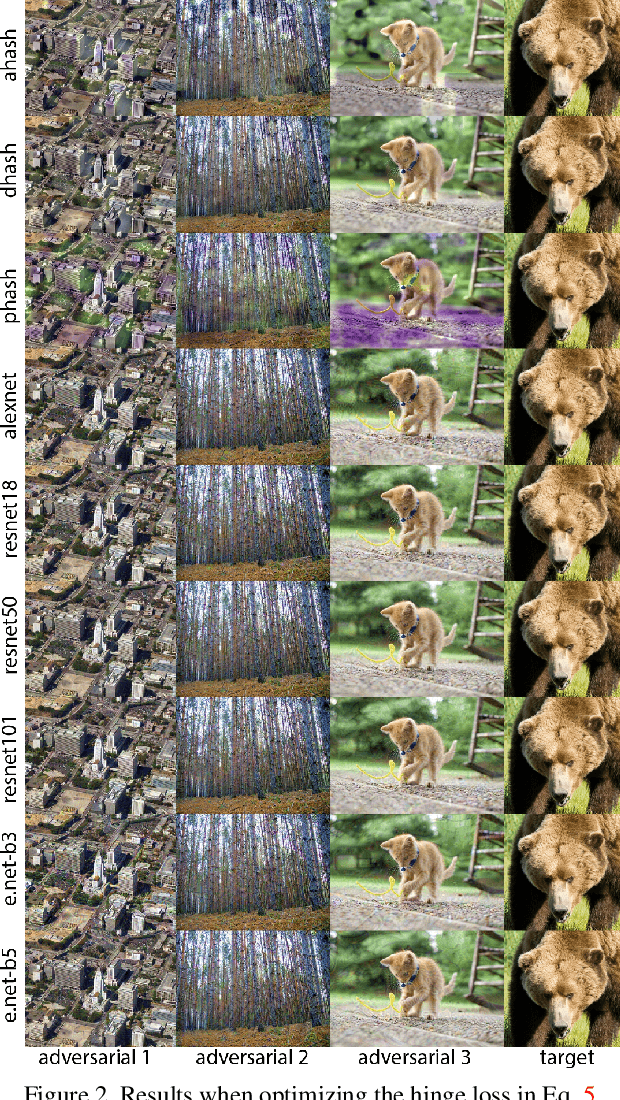
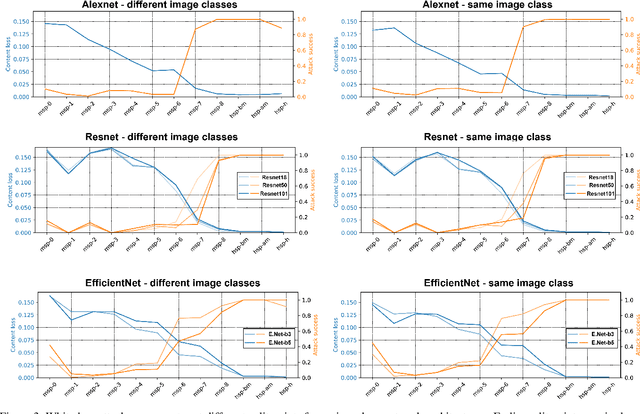
Hashing images with a perceptual algorithm is a common approach to solving duplicate image detection problems. However, perceptual image hashing algorithms are differentiable, and are thus vulnerable to gradient-based adversarial attacks. We demonstrate that not only is it possible to modify an image to produce an unrelated hash, but an exact image hash collision between a source and target image can be produced via minuscule adversarial perturbations. In a white box setting, these collisions can be replicated across nearly every image pair and hash type (including both deep and non-learned hashes). Furthermore, by attacking points other than the output of a hashing function, an attacker can avoid having to know the details of a particular algorithm, resulting in collisions that transfer across different hash sizes or model architectures. Using these techniques, an adversary can poison the image lookup table of a duplicate image detection service, resulting in undefined or unwanted behavior. Finally, we offer several potential mitigations to gradient-based image hash attacks.
The DeepFake Detection Challenge Dataset
Jun 25, 2020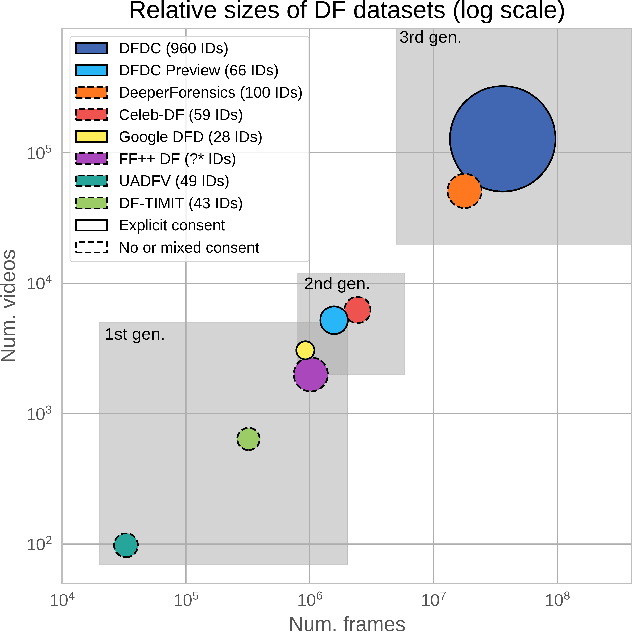
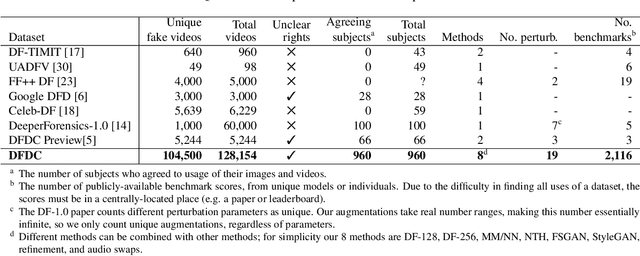

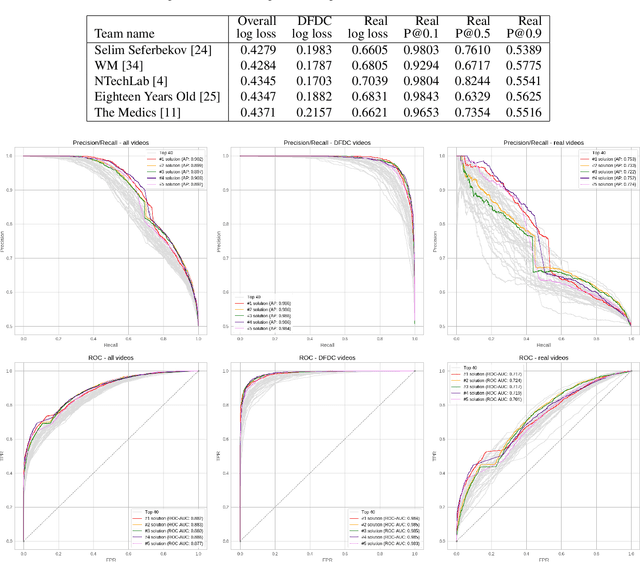
Deepfakes are a recent off-the-shelf manipulation technique that allows anyone to swap two identities in a single video. In addition to Deepfakes, a variety of GAN-based face swapping methods have also been published with accompanying code. To counter this emerging threat, we have constructed an extremely large face swap video dataset to enable the training of detection models, and organized the accompanying DeepFake Detection Challenge (DFDC) Kaggle competition. Importantly, all recorded subjects agreed to participate in and have their likenesses modified during the construction of the face-swapped dataset. The DFDC dataset is by far the largest currently and publicly available face swap video dataset, with over 100,000 total clips sourced from 3,426 paid actors, produced with several Deepfake, GAN-based, and non-learned methods. In addition to describing the methods used to construct the dataset, we provide a detailed analysis of the top submissions from the Kaggle contest. We show although Deepfake detection is extremely difficult and still an unsolved problem, a Deepfake detection model trained only on the DFDC can generalize to real "in-the-wild" Deepfake videos, and such a model can be a valuable analysis tool when analyzing potentially Deepfaked videos. Training, validation and testing corpuses can be downloaded from https://ai.facebook.com/datasets/dfdc.
Deep Poisoning Functions: Towards Robust Privacy-safe Image Data Sharing
Dec 14, 2019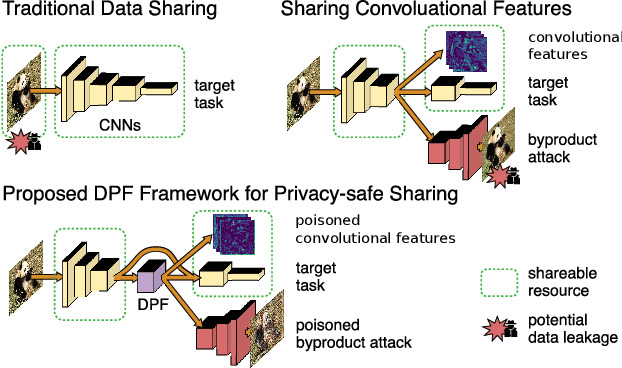
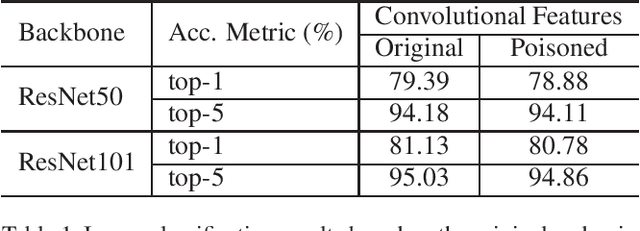
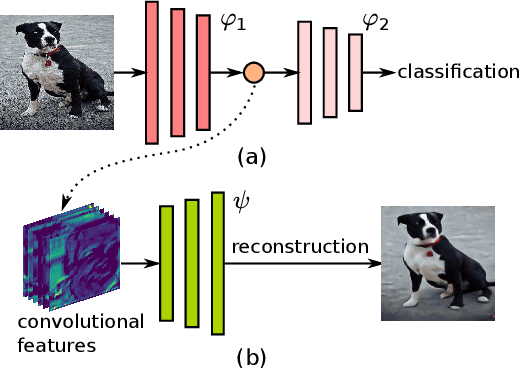
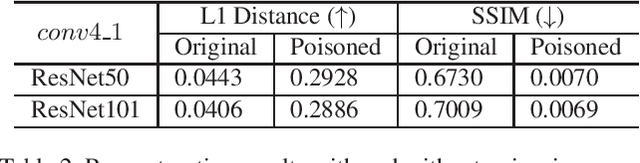
As deep networks are applied to an ever-expanding set of computer vision tasks, protecting general privacy in image data has become a critically important goal. This paper presents a new framework for privacy-preserving data sharing that is robust to adversarial attacks and overcomes the known issues existing in previous approaches. We introduce the concept of a Deep Poisoning Function (DPF), which is a module inserted into a pre-trained deep network designed to perform a specific vision task. The DPF is optimized to deliberately poison image data to prevent known adversarial attacks, while ensuring that the altered image data is functionally equivalent to the non-poisoned data for the original task. Given this equivalence, both poisoned and non-poisoned data can be used for further retraining or fine-tuning. Experimental results on image classification and face recognition tasks prove the efficacy of the proposed method.
The Deepfake Detection Challenge (DFDC) Preview Dataset
Oct 23, 2019


In this paper, we introduce a preview of the Deepfakes Detection Challenge (DFDC) dataset consisting of 5K videos featuring two facial modification algorithms. A data collection campaign has been carried out where participating actors have entered into an agreement to the use and manipulation of their likenesses in our creation of the dataset. Diversity in several axes (gender, skin-tone, age, etc.) has been considered and actors recorded videos with arbitrary backgrounds thus bringing visual variability. Finally, a set of specific metrics to evaluate the performance have been defined and two existing models for detecting deepfakes have been tested to provide a reference performance baseline. The DFDC dataset preview can be downloaded at: deepfakedetectionchallenge.ai
Eye In-Painting with Exemplar Generative Adversarial Networks
Dec 11, 2017
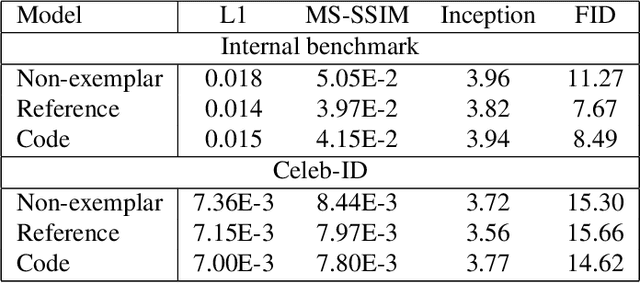
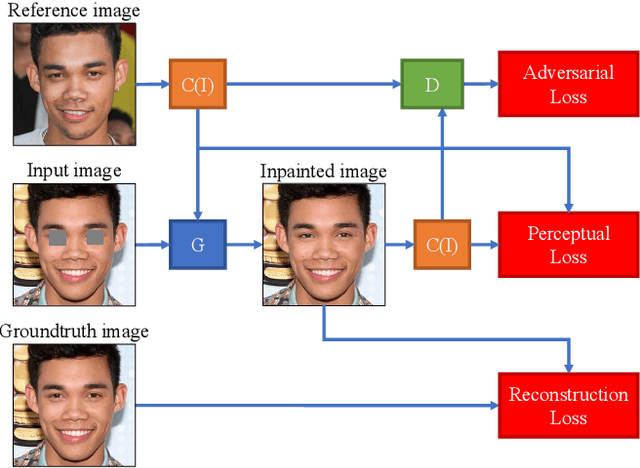
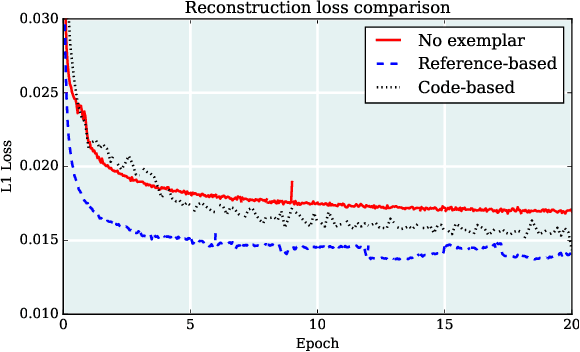
This paper introduces a novel approach to in-painting where the identity of the object to remove or change is preserved and accounted for at inference time: Exemplar GANs (ExGANs). ExGANs are a type of conditional GAN that utilize exemplar information to produce high-quality, personalized in painting results. We propose using exemplar information in the form of a reference image of the region to in-paint, or a perceptual code describing that object. Unlike previous conditional GAN formulations, this extra information can be inserted at multiple points within the adversarial network, thus increasing its descriptive power. We show that ExGANs can produce photo-realistic personalized in-painting results that are both perceptually and semantically plausible by applying them to the task of closed to-open eye in-painting in natural pictures. A new benchmark dataset is also introduced for the task of eye in-painting for future comparisons.