 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Recommender Ecosystems: Research Challenges at the Intersection of Mechanism Design, Reinforcement Learning and Generative Models
Sep 22, 2023
Modern recommender systems lie at the heart of complex ecosystems that couple the behavior of users, content providers, advertisers, and other actors. Despite this, the focus of the majority of recommender research -- and most practical recommenders of any import -- is on the local, myopic optimization of the recommendations made to individual users. This comes at a significant cost to the long-term utility that recommenders could generate for its users. We argue that explicitly modeling the incentives and behaviors of all actors in the system -- and the interactions among them induced by the recommender's policy -- is strictly necessary if one is to maximize the value the system brings to these actors and improve overall ecosystem "health". Doing so requires: optimization over long horizons using techniques such as reinforcement learning; making inevitable tradeoffs in the utility that can be generated for different actors using the methods of social choice; reducing information asymmetry, while accounting for incentives and strategic behavior, using the tools of mechanism design; better modeling of both user and item-provider behaviors by incorporating notions from behavioral economics and psychology; and exploiting recent advances in generative and foundation models to make these mechanisms interpretable and actionable. We propose a conceptual framework that encompasses these elements, and articulate a number of research challenges that emerge at the intersection of these different disciplines.
Content Prompting: Modeling Content Provider Dynamics to Improve User Welfare in Recommender Ecosystems
Sep 02, 2023Users derive value from a recommender system (RS) only to the extent that it is able to surface content (or items) that meet their needs/preferences. While RSs often have a comprehensive view of user preferences across the entire user base, content providers, by contrast, generally have only a local view of the preferences of users that have interacted with their content. This limits a provider's ability to offer new content to best serve the broader population. In this work, we tackle this information asymmetry with content prompting policies. A content prompt is a hint or suggestion to a provider to make available novel content for which the RS predicts unmet user demand. A prompting policy is a sequence of such prompts that is responsive to the dynamics of a provider's beliefs, skills and incentives. We aim to determine a joint prompting policy that induces a set of providers to make content available that optimizes user social welfare in equilibrium, while respecting the incentives of the providers themselves. Our contributions include: (i) an abstract model of the RS ecosystem, including content provider behaviors, that supports such prompting; (ii) the design and theoretical analysis of sequential prompting policies for individual providers; (iii) a mixed integer programming formulation for optimal joint prompting using path planning in content space; and (iv) simple, proof-of-concept experiments illustrating how such policies improve ecosystem health and user welfare.
DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models
May 25, 2023



Learning from human feedback has been shown to improve text-to-image models. These techniques first learn a reward function that captures what humans care about in the task and then improve the models based on the learned reward function. Even though relatively simple approaches (e.g., rejection sampling based on reward scores) have been investigated, fine-tuning text-to-image models with the reward function remains challenging. In this work, we propose using online reinforcement learning (RL) to fine-tune text-to-image models. We focus on diffusion models, defining the fine-tuning task as an RL problem, and updating the pre-trained text-to-image diffusion models using policy gradient to maximize the feedback-trained reward. Our approach, coined DPOK, integrates policy optimization with KL regularization. We conduct an analysis of KL regularization for both RL fine-tuning and supervised fine-tuning. In our experiments, we show that DPOK is generally superior to supervised fine-tuning with respect to both image-text alignment and image quality.
Aligning Text-to-Image Models using Human Feedback
Feb 23, 2023



Deep generative models have shown impressive results in text-to-image synthesis. However, current text-to-image models often generate images that are inadequately aligned with text prompts. We propose a fine-tuning method for aligning such models using human feedback, comprising three stages. First, we collect human feedback assessing model output alignment from a set of diverse text prompts. We then use the human-labeled image-text dataset to train a reward function that predicts human feedback. Lastly, the text-to-image model is fine-tuned by maximizing reward-weighted likelihood to improve image-text alignment. Our method generates objects with specified colors, counts and backgrounds more accurately than the pre-trained model. We also analyze several design choices and find that careful investigations on such design choices are important in balancing the alignment-fidelity tradeoffs. Our results demonstrate the potential for learning from human feedback to significantly improve text-to-image models.
Offline Reinforcement Learning for Mixture-of-Expert Dialogue Management
Feb 21, 2023Reinforcement learning (RL) has shown great promise for developing dialogue management (DM) agents that are non-myopic, conduct rich conversations, and maximize overall user satisfaction. Despite recent developments in RL and language models (LMs), using RL to power conversational chatbots remains challenging, in part because RL requires online exploration to learn effectively, whereas collecting novel human-bot interactions can be expensive and unsafe. This issue is exacerbated by the combinatorial action spaces facing these algorithms, as most LM agents generate responses at the word level. We develop a variety of RL algorithms, specialized to dialogue planning, that leverage recent Mixture-of-Expert Language Models (MoE-LMs) -- models that capture diverse semantics, generate utterances reflecting different intents, and are amenable for multi-turn DM. By exploiting MoE-LM structure, our methods significantly reduce the size of the action space and improve the efficacy of RL-based DM. We evaluate our methods in open-domain dialogue to demonstrate their effectiveness w.r.t.\ the diversity of intent in generated utterances and overall DM performance.
Reinforcement Learning with History-Dependent Dynamic Contexts
Feb 04, 2023

We introduce Dynamic Contextual Markov Decision Processes (DCMDPs), a novel reinforcement learning framework for history-dependent environments that generalizes the contextual MDP framework to handle non-Markov environments, where contexts change over time. We consider special cases of the model, with a focus on logistic DCMDPs, which break the exponential dependence on history length by leveraging aggregation functions to determine context transitions. This special structure allows us to derive an upper-confidence-bound style algorithm for which we establish regret bounds. Motivated by our theoretical results, we introduce a practical model-based algorithm for logistic DCMDPs that plans in a latent space and uses optimism over history-dependent features. We demonstrate the efficacy of our approach on a recommendation task (using MovieLens data) where user behavior dynamics evolve in response to recommendations.
Gathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report
Oct 27, 2022In September 2021, the "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the second report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Michael Littman of Brown University. The report, entitled "Gathering Strength, Gathering Storms," answers a set of 14 questions probing critical areas of AI development addressing the major risks and dangers of AI, its effects on society, its public perception and the future of the field. The report concludes that AI has made a major leap from the lab to people's lives in recent years, which increases the urgency to understand its potential negative effects. The questions were developed by the AI100 Standing Committee, chaired by Peter Stone of the University of Texas at Austin, consisting of a group of AI leaders with expertise in computer science, sociology, ethics, economics, and other disciplines.
Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning
Jul 25, 2022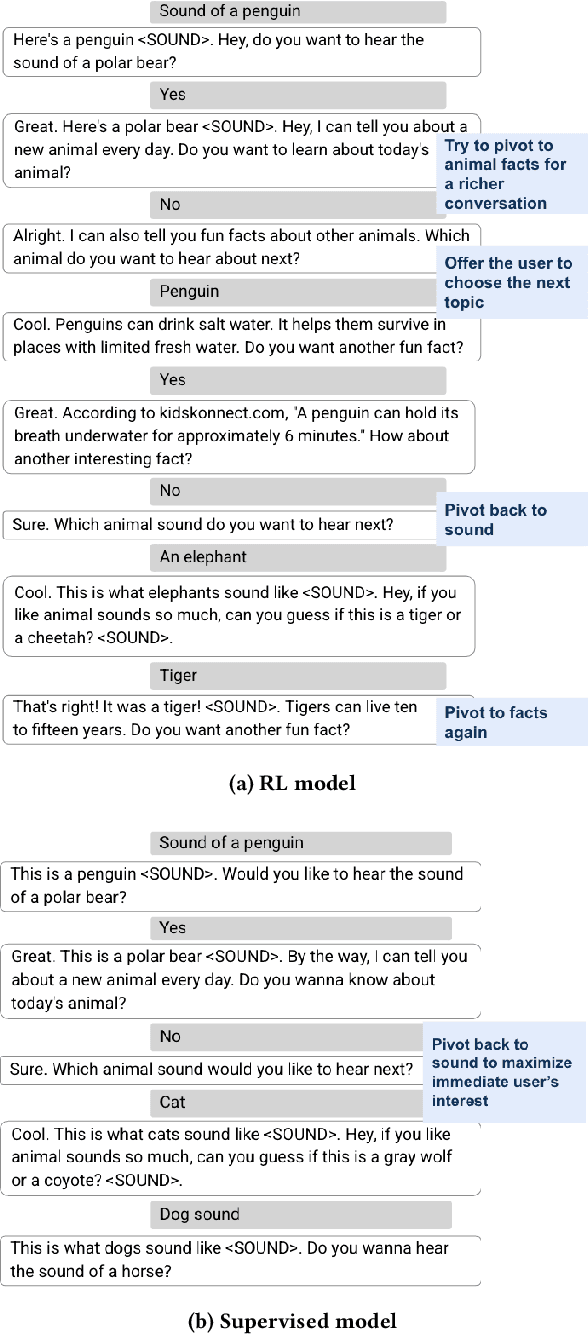
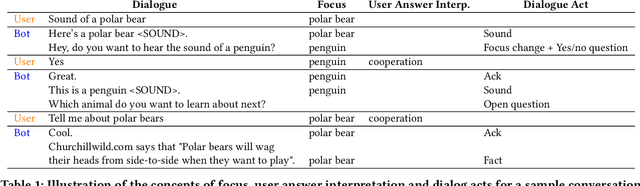

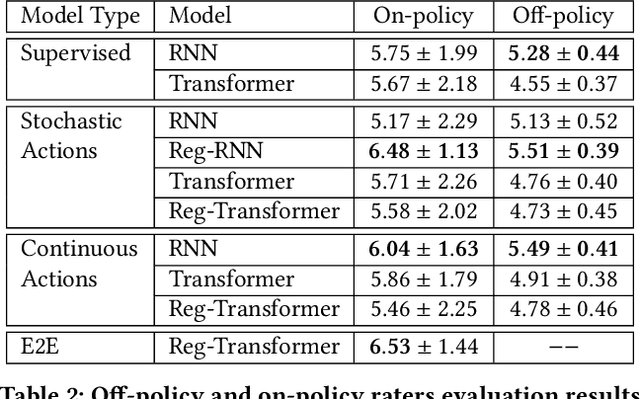
Despite recent advances in natural language understanding and generation, and decades of research on the development of conversational bots, building automated agents that can carry on rich open-ended conversations with humans "in the wild" remains a formidable challenge. In this work we develop a real-time, open-ended dialogue system that uses reinforcement learning (RL) to power a bot's conversational skill at scale. Our work pairs the succinct embedding of the conversation state generated using SOTA (supervised) language models with RL techniques that are particularly suited to a dynamic action space that changes as the conversation progresses. Trained using crowd-sourced data, our novel system is able to substantially exceeds the (strong) baseline supervised model with respect to several metrics of interest in a live experiment with real users of the Google Assistant.
Building Human Values into Recommender Systems: An Interdisciplinary Synthesis
Jul 20, 2022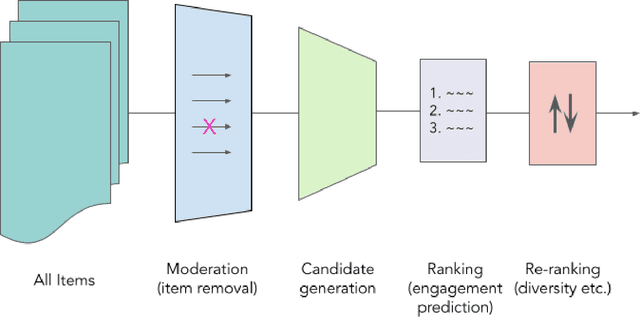
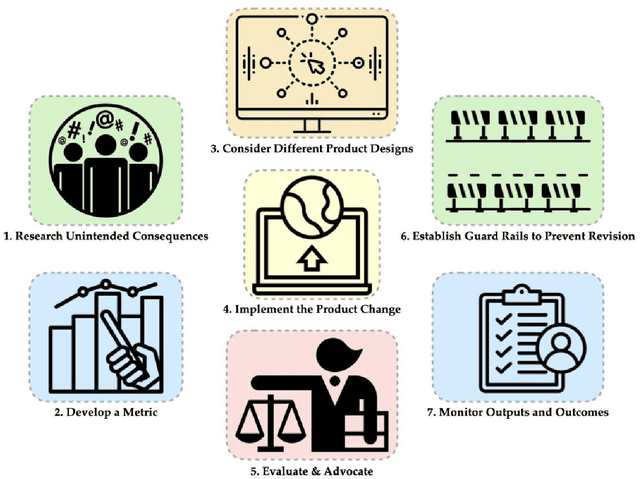
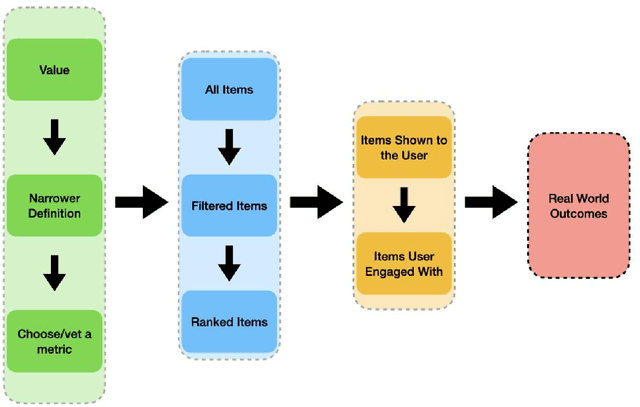

Recommender systems are the algorithms which select, filter, and personalize content across many of the worlds largest platforms and apps. As such, their positive and negative effects on individuals and on societies have been extensively theorized and studied. Our overarching question is how to ensure that recommender systems enact the values of the individuals and societies that they serve. Addressing this question in a principled fashion requires technical knowledge of recommender design and operation, and also critically depends on insights from diverse fields including social science, ethics, economics, psychology, policy and law. This paper is a multidisciplinary effort to synthesize theory and practice from different perspectives, with the goal of providing a shared language, articulating current design approaches, and identifying open problems. It is not a comprehensive survey of this large space, but a set of highlights identified by our diverse author cohort. We collect a set of values that seem most relevant to recommender systems operating across different domains, then examine them from the perspectives of current industry practice, measurement, product design, and policy approaches. Important open problems include multi-stakeholder processes for defining values and resolving trade-offs, better values-driven measurements, recommender controls that people use, non-behavioral algorithmic feedback, optimization for long-term outcomes, causal inference of recommender effects, academic-industry research collaborations, and interdisciplinary policy-making.
A Mixture-of-Expert Approach to RL-based Dialogue Management
May 31, 2022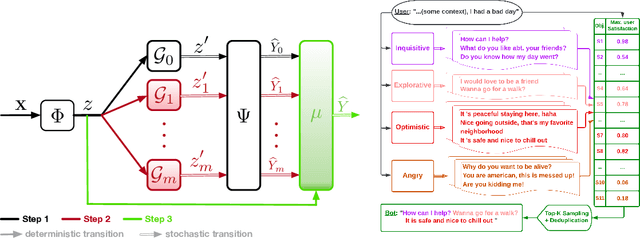

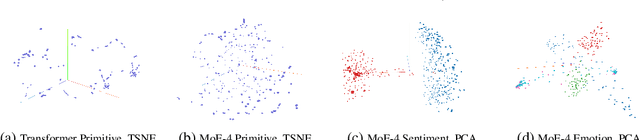

Despite recent advancements in language models (LMs), their application to dialogue management (DM) problems and ability to carry on rich conversations remain a challenge. We use reinforcement learning (RL) to develop a dialogue agent that avoids being short-sighted (outputting generic utterances) and maximizes overall user satisfaction. Most existing RL approaches to DM train the agent at the word-level, and thus, have to deal with a combinatorially complex action space even for a medium-size vocabulary. As a result, they struggle to produce a successful and engaging dialogue even if they are warm-started with a pre-trained LM. To address this issue, we develop a RL-based DM using a novel mixture of expert language model (MoE-LM) that consists of (i) a LM capable of learning diverse semantics for conversation histories, (ii) a number of {\em specialized} LMs (or experts) capable of generating utterances corresponding to a particular attribute or personality, and (iii) a RL-based DM that performs dialogue planning with the utterances generated by the experts. Our MoE approach provides greater flexibility to generate sensible utterances with different intents and allows RL to focus on conversational-level DM. We compare it with SOTA baselines on open-domain dialogues and demonstrate its effectiveness both in terms of the diversity and sensibility of the generated utterances and the overall DM performance.