 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Efficacy of Sampling Adapters
Jul 07, 2023Sampling is a common strategy for generating text from probabilistic models, yet standard ancestral sampling often results in text that is incoherent or ungrammatical. To alleviate this issue, various modifications to a model's sampling distribution, such as nucleus or top-k sampling, have been introduced and are now ubiquitously used in language generation systems. We propose a unified framework for understanding these techniques, which we term sampling adapters. Sampling adapters often lead to qualitatively better text, which raises the question: From a formal perspective, how are they changing the (sub)word-level distributions of language generation models? And why do these local changes lead to higher-quality text? We argue that the shift they enforce can be viewed as a trade-off between precision and recall: while the model loses its ability to produce certain strings, its precision rate on desirable text increases. While this trade-off is not reflected in standard metrics of distribution quality (such as perplexity), we find that several precision-emphasizing measures indeed indicate that sampling adapters can lead to probability distributions more aligned with the true distribution. Further, these measures correlate with higher sequence-level quality scores, specifically, Mauve.
Tokenization and the Noiseless Channel
Jun 29, 2023



Subword tokenization is a key part of many NLP pipelines. However, little is known about why some tokenizer and hyperparameter combinations lead to better downstream model performance than others. We propose that good tokenizers lead to \emph{efficient} channel usage, where the channel is the means by which some input is conveyed to the model and efficiency can be quantified in information-theoretic terms as the ratio of the Shannon entropy to the maximum possible entropy of the token distribution. Yet, an optimal encoding according to Shannon entropy assigns extremely long codes to low-frequency tokens and very short codes to high-frequency tokens. Defining efficiency in terms of R\'enyi entropy, on the other hand, penalizes distributions with either very high or very low-frequency tokens. In machine translation, we find that across multiple tokenizers, the R\'enyi entropy with $\alpha = 2.5$ has a very strong correlation with \textsc{Bleu}: $0.78$ in comparison to just $-0.32$ for compressed length.
A Formal Perspective on Byte-Pair Encoding
Jun 29, 2023



Byte-Pair Encoding (BPE) is a popular algorithm used for tokenizing data in NLP, despite being devised initially as a compression method. BPE appears to be a greedy algorithm at face value, but the underlying optimization problem that BPE seeks to solve has not yet been laid down. We formalize BPE as a combinatorial optimization problem. Via submodular functions, we prove that the iterative greedy version is a $\frac{1}{{\sigma(\boldsymbol{\mu}^\star)}}(1-e^{-{\sigma(\boldsymbol{\mu}^\star)}})$-approximation of an optimal merge sequence, where ${\sigma(\boldsymbol{\mu}^\star)}$ is the total backward curvature with respect to the optimal merge sequence $\boldsymbol{\mu}^\star$. Empirically the lower bound of the approximation is $\approx 0.37$. We provide a faster implementation of BPE which improves the runtime complexity from $\mathcal{O}\left(N M\right)$ to $\mathcal{O}\left(N \log M\right)$, where $N$ is the sequence length and $M$ is the merge count. Finally, we optimize the brute-force algorithm for optimal BPE using memoization.
A Cross-Linguistic Pressure for Uniform Information Density in Word Order
Jun 06, 2023While natural languages differ widely in both canonical word order and word order flexibility, their word orders still follow shared cross-linguistic statistical patterns, often attributed to functional pressures. In the effort to identify these pressures, prior work has compared real and counterfactual word orders. Yet one functional pressure has been overlooked in such investigations: the uniform information density (UID) hypothesis, which holds that information should be spread evenly throughout an utterance. Here, we ask whether a pressure for UID may have influenced word order patterns cross-linguistically. To this end, we use computational models to test whether real orders lead to greater information uniformity than counterfactual orders. In our empirical study of 10 typologically diverse languages, we find that: (i) among SVO languages, real word orders consistently have greater uniformity than reverse word orders, and (ii) only linguistically implausible counterfactual orders consistently exceed the uniformity of real orders. These findings are compatible with a pressure for information uniformity in the development and usage of natural languages.
A Measure-Theoretic Characterization of Tight Language Models
Dec 20, 2022
Language modeling, a central task in natural language processing, involves estimating a probability distribution over strings. In most cases, the estimated distribution sums to 1 over all finite strings. However, in some pathological cases, probability mass can ``leak'' onto the set of infinite sequences. In order to characterize the notion of leakage more precisely, this paper offers a measure-theoretic treatment of language modeling. We prove that many popular language model families are in fact tight, meaning that they will not leak in this sense. We also generalize characterizations of tightness proposed in previous works.
A Natural Bias for Language Generation Models
Dec 19, 2022



After just a few hundred training updates, a standard probabilistic model for language generation has likely not yet learnt many semantic or syntactic rules of natural language, which inherently makes it difficult to estimate the right probability distribution over next tokens. Yet around this point, these models have identified a simple, loss-minimising behaviour: to output the unigram distribution of the target training corpus. The use of such a crude heuristic raises the question: Rather than wasting precious compute resources and model capacity for learning this strategy at early training stages, can we initialise our models with this behaviour? Here, we show that we can effectively endow our model with a separate module that reflects unigram frequency statistics as prior knowledge. Standard neural language generation architectures offer a natural opportunity for implementing this idea: by initialising the bias term in a model's final linear layer with the log-unigram distribution. Experiments in neural machine translation demonstrate that this simple technique: (i) improves learning efficiency; (ii) achieves better overall performance; and (iii) appears to disentangle strong frequency effects, encouraging the model to specialise in non-frequency-related aspects of language.
On the Effect of Anticipation on Reading Times
Nov 25, 2022Over the past two decades, numerous studies have demonstrated how less predictable (i.e. higher surprisal) words take more time to read. In general, these previous studies implicitly assumed the reading process to be purely responsive: readers observe a new word and allocate time to read it as required. These results, however, are also compatible with a reading time that is anticipatory: readers could, e.g., allocate time to a future word based on their expectation about it. In this work, we examine the anticipatory nature of reading by looking at how people's predictions about upcoming material influence reading times. Specifically, we test anticipation by looking at the effects of surprisal and contextual entropy on four reading-time datasets: two self-paced and two eye-tracking. In three of four datasets tested, we find that the entropy predicts reading times as well as (or better than) the surprisal. We then hypothesise four cognitive mechanisms through which the contextual entropy could impact RTs -- three of which we design experiments to analyse. Overall, our results support a view of reading that is both anticipatory and responsive.
Mutual Information Alleviates Hallucinations in Abstractive Summarization
Oct 29, 2022Despite significant progress in the quality of language generated from abstractive summarization models, these models still exhibit the tendency to hallucinate, i.e., output content not supported by the source document. A number of works have tried to fix--or at least uncover the source of--the problem with limited success. In this paper, we identify a simple criterion under which models are significantly more likely to assign more probability to hallucinated content during generation: high model uncertainty. This finding offers a potential explanation for hallucinations: models default to favoring text with high marginal probability, i.e., high-frequency occurrences in the training set, when uncertain about a continuation. It also motivates possible routes for real-time intervention during decoding to prevent such hallucinations. We propose a decoding strategy that switches to optimizing for pointwise mutual information of the source and target token--rather than purely the probability of the target token--when the model exhibits uncertainty. Experiments on the XSum dataset show that our method decreases the probability of hallucinated tokens while maintaining the Rouge and BertS scores of top-performing decoding strategies.
Cluster-based Evaluation of Automatically Generated Text
Jun 01, 2022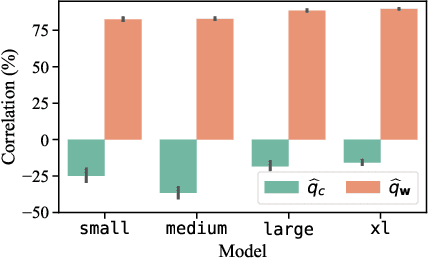
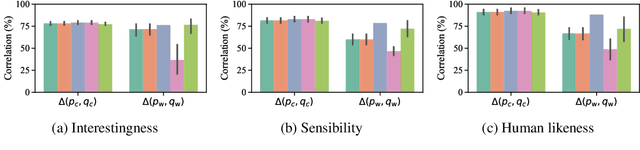
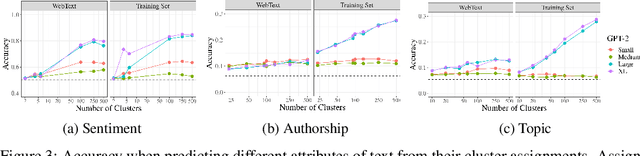
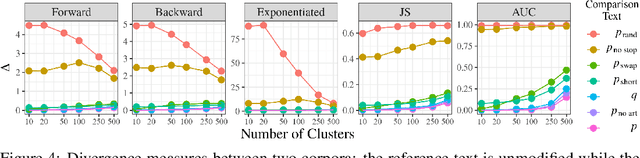
While probabilistic language generators have improved dramatically over the last few years, the automatic evaluation metrics used to assess them have not kept pace with this progress. In the domain of language generation, a good metric must correlate highly with human judgements. Yet, with few exceptions, there is a lack of such metrics in the literature. In this work, we analyse the general paradigm of language generator evaluation. We first discuss the computational and qualitative issues with using automatic evaluation metrics that operate on probability distributions over strings, the backbone of most language generators. We then propose the use of distributions over clusters instead, where we cluster strings based on their text embeddings (obtained from a pretrained language model). While we find the biases introduced by this substitution to be quite strong, we observe that, empirically, this methodology leads to metric estimators with higher correlation with human judgements, while simultaneously reducing estimator variance. We finish the paper with a probing analysis, which leads us to conclude that -- by encoding syntactic- and coherence-level features of text, while ignoring surface-level features -- these clusters may simply be better equipped to evaluate state-of-the-art language models.
Naturalistic Causal Probing for Morpho-Syntax
May 14, 2022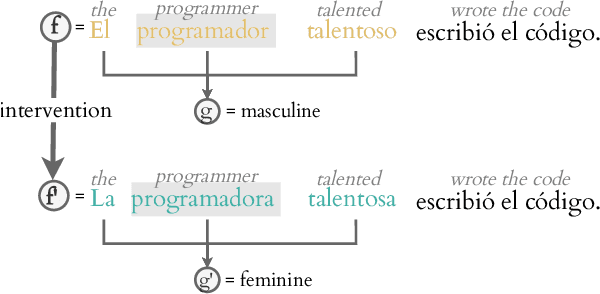
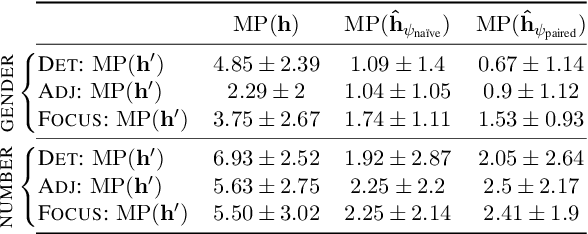
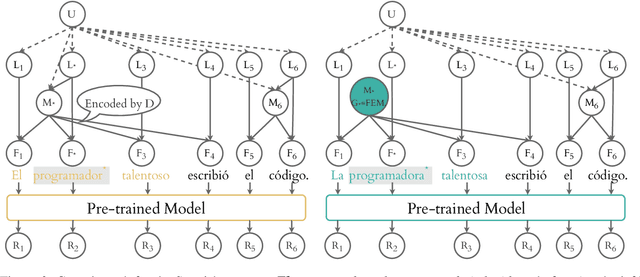
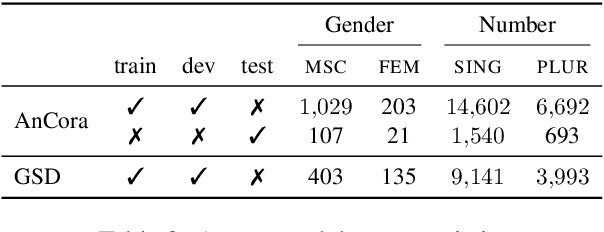
Probing has become a go-to methodology for interpreting and analyzing deep neural models in natural language processing. Yet recently, there has been much debate around the limitations and weaknesses of probes. In this work, we suggest a naturalistic strategy for input-level intervention on real world data in Spanish, which is a language with gender marking. Using our approach, we isolate morpho-syntactic features from counfounders in sentences, e.g. topic, which will then allow us to causally probe pre-trained models. We apply this methodology to analyze causal effects of gender and number on contextualized representations extracted from pre-trained models -- BERT, RoBERTa and GPT-2. Our experiments suggest that naturalistic intervention can give us stable estimates of causal effects, which varies across different words in a sentence. We further show the utility of our estimator in investigating gender bias in adjectives, and answering counterfactual questions in masked prediction. Our probing experiments highlights the importance of conducting causal probing in determining if a particular property is encoded in representations.