 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Implicit Generative Models by Matching Perceptual Features
Apr 04, 2019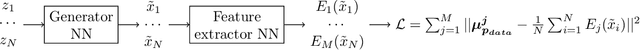



Perceptual features (PFs) have been used with great success in tasks such as transfer learning, style transfer, and super-resolution. However, the efficacy of PFs as key source of information for learning generative models is not well studied. We investigate here the use of PFs in the context of learning implicit generative models through moment matching (MM). More specifically, we propose a new effective MM approach that learns implicit generative models by performing mean and covariance matching of features extracted from pretrained ConvNets. Our proposed approach improves upon existing MM methods by: (1) breaking away from the problematic min/max game of adversarial learning; (2) avoiding online learning of kernel functions; and (3) being efficient with respect to both number of used moments and required minibatch size. Our experimental results demonstrate that, due to the expressiveness of PFs from pretrained deep ConvNets, our method achieves state-of-the-art results for challenging benchmarks.
Fighting Offensive Language on Social Media with Unsupervised Text Style Transfer
May 20, 2018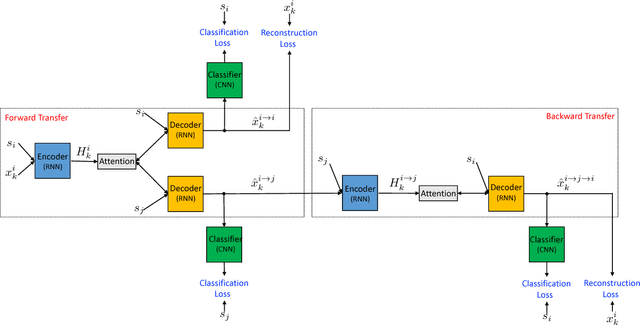
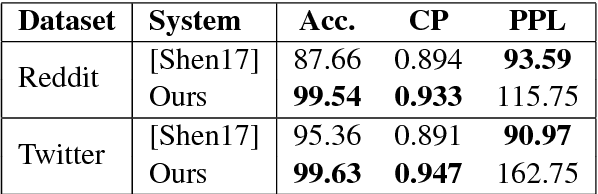


We introduce a new approach to tackle the problem of offensive language in online social media. Our approach uses unsupervised text style transfer to translate offensive sentences into non-offensive ones. We propose a new method for training encoder-decoders using non-parallel data that combines a collaborative classifier, attention and the cycle consistency loss. Experimental results on data from Twitter and Reddit show that our method outperforms a state-of-the-art text style transfer system in two out of three quantitative metrics and produces reliable non-offensive transferred sentences.
Neural Coreference Resolution with Deep Biaffine Attention by Joint Mention Detection and Mention Clustering
May 13, 2018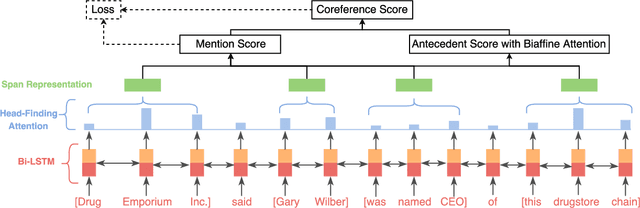
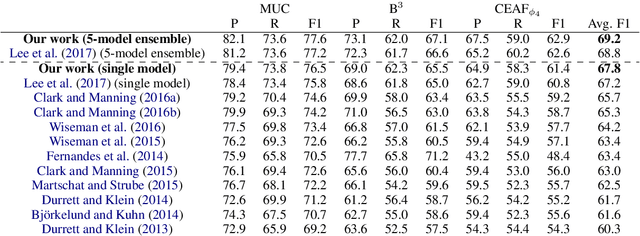
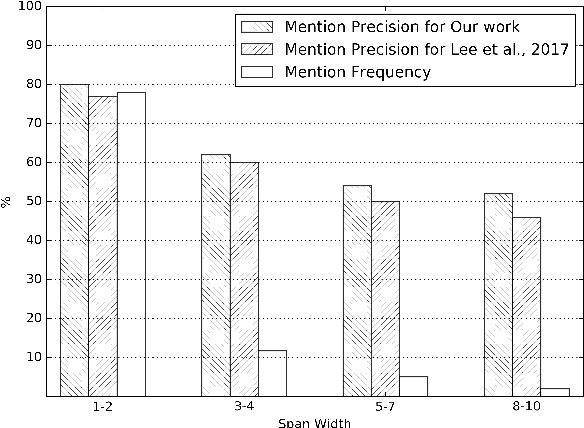

Coreference resolution aims to identify in a text all mentions that refer to the same real-world entity. The state-of-the-art end-to-end neural coreference model considers all text spans in a document as potential mentions and learns to link an antecedent for each possible mention. In this paper, we propose to improve the end-to-end coreference resolution system by (1) using a biaffine attention model to get antecedent scores for each possible mention, and (2) jointly optimizing the mention detection accuracy and the mention clustering log-likelihood given the mention cluster labels. Our model achieves the state-of-the-art performance on the CoNLL-2012 Shared Task English test set.
Improved Neural Text Attribute Transfer with Non-parallel Data
Dec 04, 2017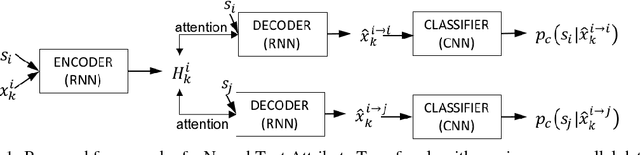
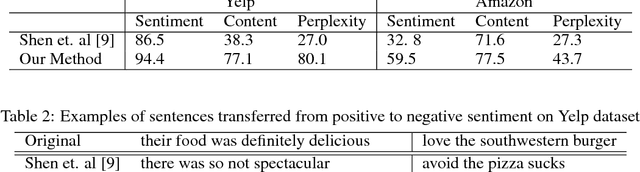
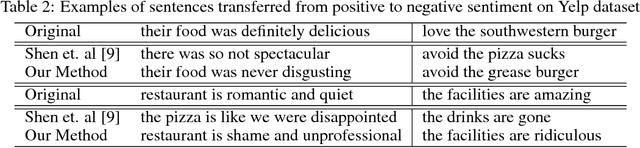
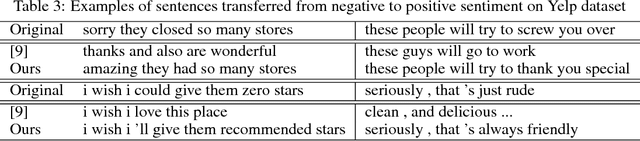
Text attribute transfer using non-parallel data requires methods that can perform disentanglement of content and linguistic attributes. In this work, we propose multiple improvements over the existing approaches that enable the encoder-decoder framework to cope with the text attribute transfer from non-parallel data. We perform experiments on the sentiment transfer task using two datasets. For both datasets, our proposed method outperforms a strong baseline in two of the three employed evaluation metrics.
Learning Loss Functions for Semi-supervised Learning via Discriminative Adversarial Networks
Jul 07, 2017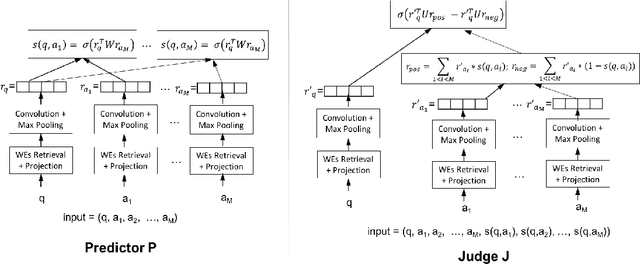
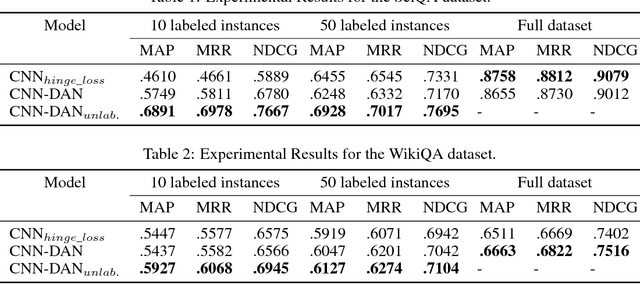
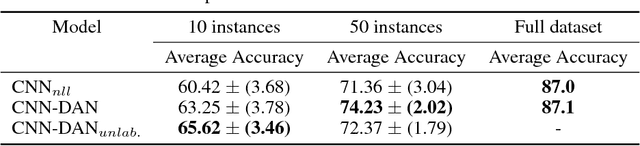
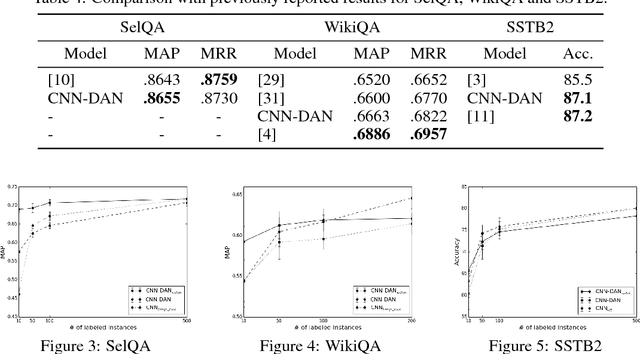
We propose discriminative adversarial networks (DAN) for semi-supervised learning and loss function learning. Our DAN approach builds upon generative adversarial networks (GANs) and conditional GANs but includes the key differentiator of using two discriminators instead of a generator and a discriminator. DAN can be seen as a framework to learn loss functions for predictors that also implements semi-supervised learning in a straightforward manner. We propose instantiations of DAN for two different prediction tasks: classification and ranking. Our experimental results on three datasets of different tasks demonstrate that DAN is a promising framework for both semi-supervised learning and learning loss functions for predictors. For all tasks, the semi-supervised capability of DAN can significantly boost the predictor performance for small labeled sets with minor architecture changes across tasks. Moreover, the loss functions automatically learned by DANs are very competitive and usually outperform the standard pairwise and negative log-likelihood loss functions for both semi-supervised and supervised learning.
A Structured Self-attentive Sentence Embedding
Mar 09, 2017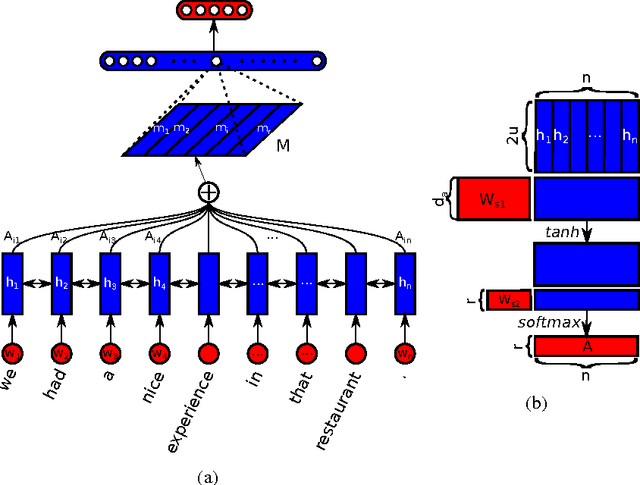


This paper proposes a new model for extracting an interpretable sentence embedding by introducing self-attention. Instead of using a vector, we use a 2-D matrix to represent the embedding, with each row of the matrix attending on a different part of the sentence. We also propose a self-attention mechanism and a special regularization term for the model. As a side effect, the embedding comes with an easy way of visualizing what specific parts of the sentence are encoded into the embedding. We evaluate our model on 3 different tasks: author profiling, sentiment classification, and textual entailment. Results show that our model yields a significant performance gain compared to other sentence embedding methods in all of the 3 tasks.
Boosting Named Entity Recognition with Neural Character Embeddings
May 25, 2015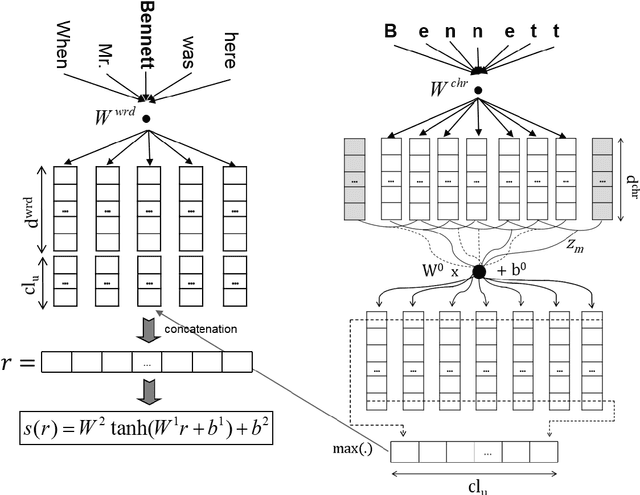
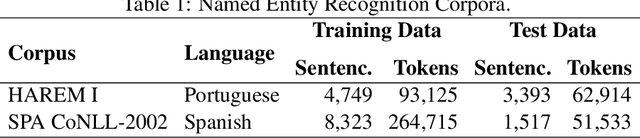

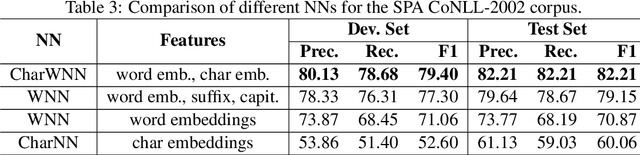
Most state-of-the-art named entity recognition (NER) systems rely on handcrafted features and on the output of other NLP tasks such as part-of-speech (POS) tagging and text chunking. In this work we propose a language-independent NER system that uses automatically learned features only. Our approach is based on the CharWNN deep neural network, which uses word-level and character-level representations (embeddings) to perform sequential classification. We perform an extensive number of experiments using two annotated corpora in two different languages: HAREM I corpus, which contains texts in Portuguese; and the SPA CoNLL-2002 corpus, which contains texts in Spanish. Our experimental results shade light on the contribution of neural character embeddings for NER. Moreover, we demonstrate that the same neural network which has been successfully applied to POS tagging can also achieve state-of-the-art results for language-independet NER, using the same hyperparameters, and without any handcrafted features. For the HAREM I corpus, CharWNN outperforms the state-of-the-art system by 7.9 points in the F1-score for the total scenario (ten NE classes), and by 7.2 points in the F1 for the selective scenario (five NE classes).
Classifying Relations by Ranking with Convolutional Neural Networks
May 24, 2015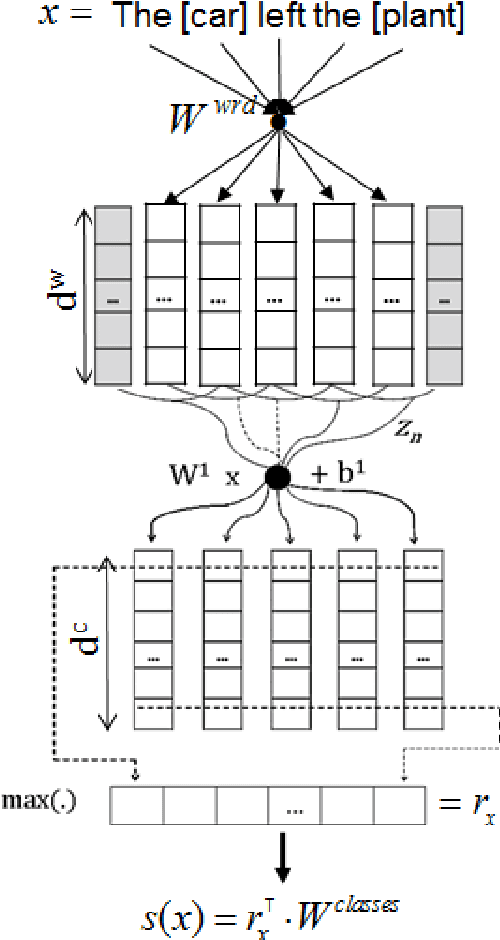

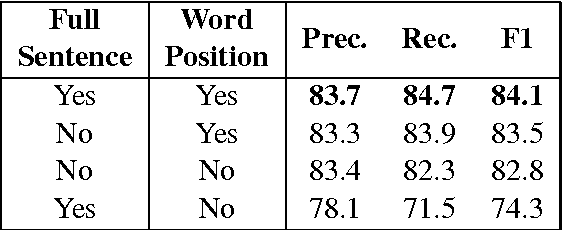
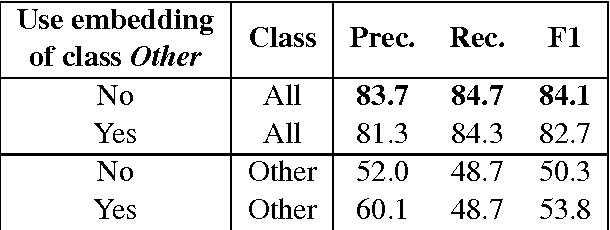
Relation classification is an important semantic processing task for which state-ofthe-art systems still rely on costly handcrafted features. In this work we tackle the relation classification task using a convolutional neural network that performs classification by ranking (CR-CNN). We propose a new pairwise ranking loss function that makes it easy to reduce the impact of artificial classes. We perform experiments using the the SemEval-2010 Task 8 dataset, which is designed for the task of classifying the relationship between two nominals marked in a sentence. Using CRCNN, we outperform the state-of-the-art for this dataset and achieve a F1 of 84.1 without using any costly handcrafted features. Additionally, our experimental results show that: (1) our approach is more effective than CNN followed by a softmax classifier; (2) omitting the representation of the artificial class Other improves both precision and recall; and (3) using only word embeddings as input features is enough to achieve state-of-the-art results if we consider only the text between the two target nominals.