 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Stupid robot, I want to speak to a human!" User Frustration Detection in Task-Oriented Dialog Systems
Nov 26, 2024



Detecting user frustration in modern-day task-oriented dialog (TOD) systems is imperative for maintaining overall user satisfaction, engagement, and retention. However, most recent research is focused on sentiment and emotion detection in academic settings, thus failing to fully encapsulate implications of real-world user data. To mitigate this gap, in this work, we focus on user frustration in a deployed TOD system, assessing the feasibility of out-of-the-box solutions for user frustration detection. Specifically, we compare the performance of our deployed keyword-based approach, open-source approaches to sentiment analysis, dialog breakdown detection methods, and emerging in-context learning LLM-based detection. Our analysis highlights the limitations of open-source methods for real-world frustration detection, while demonstrating the superior performance of the LLM-based approach, achieving a 16\% relative improvement in F1 score on an internal benchmark. Finally, we analyze advantages and limitations of our methods and provide an insight into user frustration detection task for industry practitioners.
Reliable LLM-based User Simulator for Task-Oriented Dialogue Systems
Feb 20, 2024



In the realm of dialogue systems, user simulation techniques have emerged as a game-changer, redefining the evaluation and enhancement of task-oriented dialogue (TOD) systems. These methods are crucial for replicating real user interactions, enabling applications like synthetic data augmentation, error detection, and robust evaluation. However, existing approaches often rely on rigid rule-based methods or on annotated data. This paper introduces DAUS, a Domain-Aware User Simulator. Leveraging large language models, we fine-tune DAUS on real examples of task-oriented dialogues. Results on two relevant benchmarks showcase significant improvements in terms of user goal fulfillment. Notably, we have observed that fine-tuning enhances the simulator's coherence with user goals, effectively mitigating hallucinations -- a major source of inconsistencies in simulator responses.
Dataflow Dialogue Generation
Aug 04, 2023



We demonstrate task-oriented dialogue generation within the dataflow dialogue paradigm. We show an example of agenda driven dialogue generation for the MultiWOZ domain, and an example of generation without an agenda for the SMCalFlow domain, where we show an improvement in the accuracy of the translation of user requests to dataflow expressions when the generated dialogues are used to augment the translation training dataset.
MultiWOZ-DF -- A Dataflow implementation of the MultiWOZ dataset
Nov 04, 2022



Semantic Machines (SM) have introduced the use of the dataflow (DF) paradigm to dialogue modelling, using computational graphs to hierarchically represent user requests, data, and the dialogue history [Semantic Machines et al. 2020]. Although the main focus of that paper was the SMCalFlow dataset (to date, the only dataset with "native" DF annotations), they also reported some results of an experiment using a transformed version of the commonly used MultiWOZ dataset [Budzianowski et al. 2018] into a DF format. In this paper, we expand the experiments using DF for the MultiWOZ dataset, exploring some additional experimental set-ups. The code and instructions to reproduce the experiments reported here have been released. The contributions of this paper are: 1.) A DF implementation capable of executing MultiWOZ dialogues; 2.) Several versions of conversion of MultiWOZ into a DF format are presented; 3.) Experimental results on state match and translation accuracy.
NeuralLog: a Neural Logic Language
May 04, 2021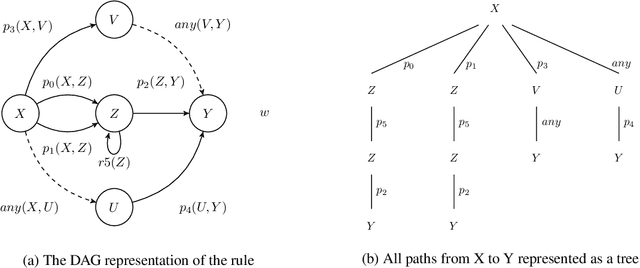
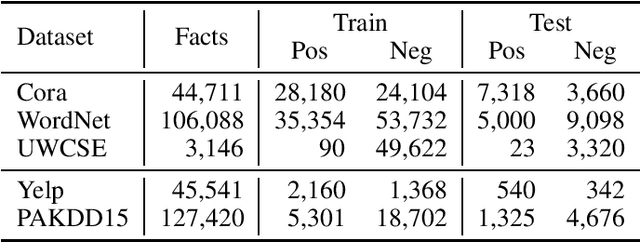

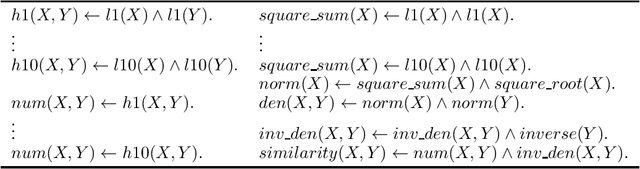
Application domains that require considering relationships among objects which have real-valued attributes are becoming even more important. In this paper we propose NeuralLog, a first-order logic language that is compiled to a neural network. The main goal of NeuralLog is to bridge logic programming and deep learning, allowing advances in both fields to be combined in order to obtain better machine learning models. The main advantages of NeuralLog are: to allow neural networks to be defined as logic programs; and to be able to handle numeric attributes and functions. We compared NeuralLog with two distinct systems that use first-order logic to build neural networks. We have also shown that NeuralLog can learn link prediction and classification tasks, using the same theory as the compared systems, achieving better results for the area under the ROC curve in four datasets: Cora and UWCSE for link prediction; and Yelp and PAKDD15 for classification; and comparable results for link prediction in the WordNet dataset.
Boosting Named Entity Recognition with Neural Character Embeddings
May 25, 2015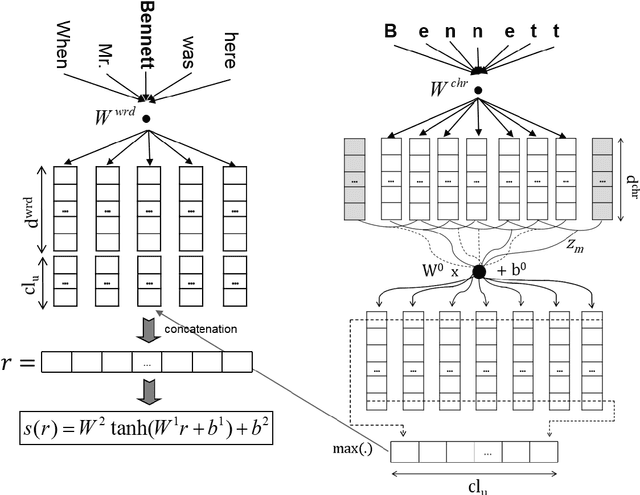
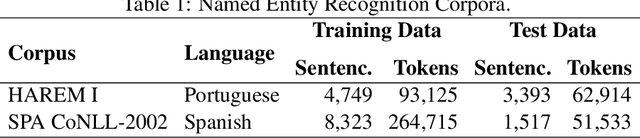

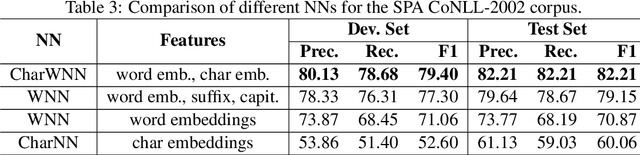
Most state-of-the-art named entity recognition (NER) systems rely on handcrafted features and on the output of other NLP tasks such as part-of-speech (POS) tagging and text chunking. In this work we propose a language-independent NER system that uses automatically learned features only. Our approach is based on the CharWNN deep neural network, which uses word-level and character-level representations (embeddings) to perform sequential classification. We perform an extensive number of experiments using two annotated corpora in two different languages: HAREM I corpus, which contains texts in Portuguese; and the SPA CoNLL-2002 corpus, which contains texts in Spanish. Our experimental results shade light on the contribution of neural character embeddings for NER. Moreover, we demonstrate that the same neural network which has been successfully applied to POS tagging can also achieve state-of-the-art results for language-independet NER, using the same hyperparameters, and without any handcrafted features. For the HAREM I corpus, CharWNN outperforms the state-of-the-art system by 7.9 points in the F1-score for the total scenario (ten NE classes), and by 7.2 points in the F1 for the selective scenario (five NE classes).