 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCANet: A Context-Aware Network for Shadow Removal
Aug 23, 2021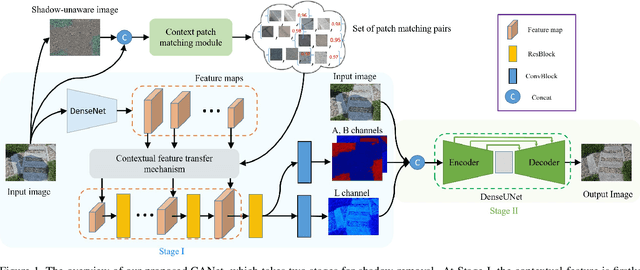
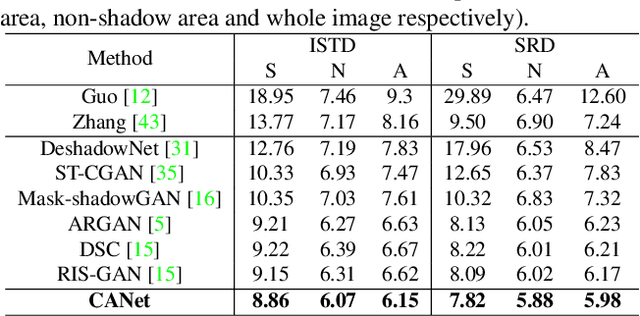
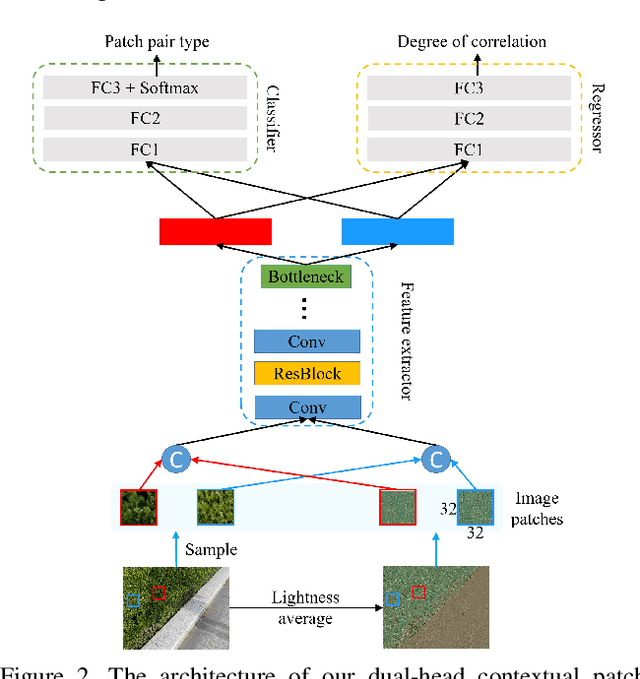
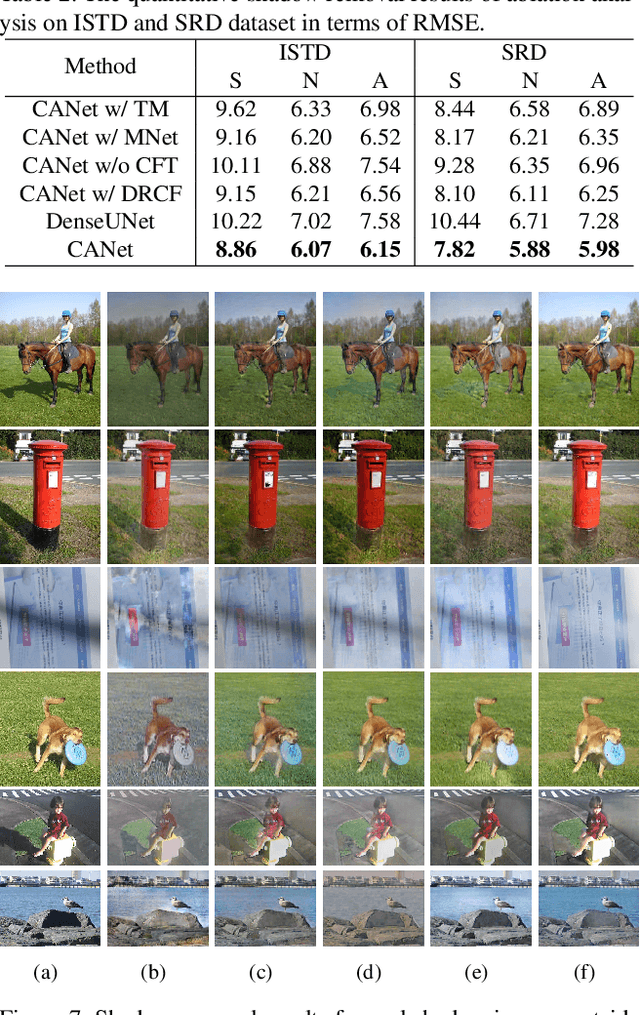
In this paper, we propose a novel two-stage context-aware network named CANet for shadow removal, in which the contextual information from non-shadow regions is transferred to shadow regions at the embedded feature spaces. At Stage-I, we propose a contextual patch matching (CPM) module to generate a set of potential matching pairs of shadow and non-shadow patches. Combined with the potential contextual relationships between shadow and non-shadow regions, our well-designed contextual feature transfer (CFT) mechanism can transfer contextual information from non-shadow to shadow regions at different scales. With the reconstructed feature maps, we remove shadows at L and A/B channels separately. At Stage-II, we use an encoder-decoder to refine current results and generate the final shadow removal results. We evaluate our proposed CANet on two benchmark datasets and some real-world shadow images with complex scenes. Extensive experimental results strongly demonstrate the efficacy of our proposed CANet and exhibit superior performance to state-of-the-arts.
Dual Graph Convolutional Networks with Transformer and Curriculum Learning for Image Captioning
Aug 05, 2021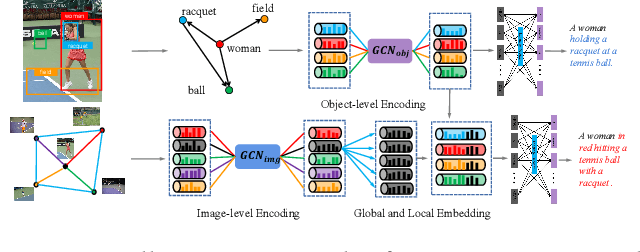

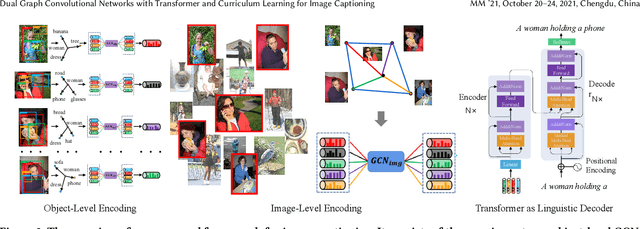
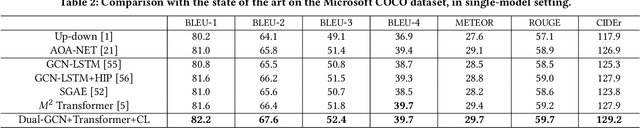
Existing image captioning methods just focus on understanding the relationship between objects or instances in a single image, without exploring the contextual correlation existed among contextual image. In this paper, we propose Dual Graph Convolutional Networks (Dual-GCN) with transformer and curriculum learning for image captioning. In particular, we not only use an object-level GCN to capture the object to object spatial relation within a single image, but also adopt an image-level GCN to capture the feature information provided by similar images. With the well-designed Dual-GCN, we can make the linguistic transformer better understand the relationship between different objects in a single image and make full use of similar images as auxiliary information to generate a reasonable caption description for a single image. Meanwhile, with a cross-review strategy introduced to determine difficulty levels, we adopt curriculum learning as the training strategy to increase the robustness and generalization of our proposed model. We conduct extensive experiments on the large-scale MS COCO dataset, and the experimental results powerfully demonstrate that our proposed method outperforms recent state-of-the-art approaches. It achieves a BLEU-1 score of 82.2 and a BLEU-2 score of 67.6. Our source code is available at {\em \color{magenta}{\url{https://github.com/Unbear430/DGCN-for-image-captioning}}}.
Scene Inference for Object Illumination Editing
Jul 31, 2021

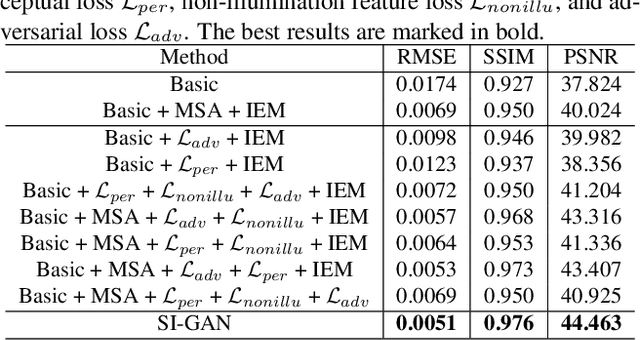
The seamless illumination integration between a foreground object and a background scene is an important but challenging task in computer vision and augmented reality community. However, to our knowledge, there is no publicly available high-quality dataset that meets the illumination seamless integration task, which greatly hinders the development of this research direction. To this end, we apply a physically-based rendering method to create a large-scale, high-quality dataset, named IH dataset, which provides rich illumination information for seamless illumination integration task. In addition, we propose a deep learning-based SI-GAN method, a multi-task collaborative network, which makes full use of the multi-scale attention mechanism and adversarial learning strategy to directly infer mapping relationship between the inserted foreground object and corresponding background environment, and edit object illumination according to the proposed illumination exchange mechanism in parallel network. By this means, we can achieve the seamless illumination integration without explicit estimation of 3D geometric information. Comprehensive experiments on both our dataset and real-world images collected from the Internet show that our proposed SI-GAN provides a practical and effective solution for image-based object illumination editing, and validate the superiority of our method against state-of-the-art methods.
CRD-CGAN: Category-Consistent and Relativistic Constraints for Diverse Text-to-Image Generation
Jul 28, 2021
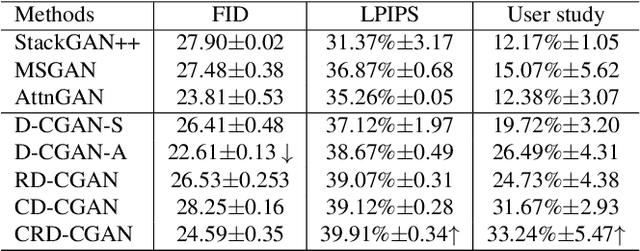

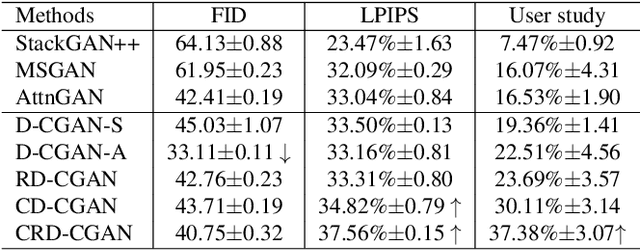
Generating photo-realistic images from a text description is a challenging problem in computer vision. Previous works have shown promising performance to generate synthetic images conditional on text by Generative Adversarial Networks (GANs). In this paper, we focus on the category-consistent and relativistic diverse constraints to optimize the diversity of synthetic images. Based on those constraints, a category-consistent and relativistic diverse conditional GAN (CRD-CGAN) is proposed to synthesize $K$ photo-realistic images simultaneously. We use the attention loss and diversity loss to improve the sensitivity of the GAN to word attention and noises. Then, we employ the relativistic conditional loss to estimate the probability of relatively real or fake for synthetic images, which can improve the performance of basic conditional loss. Finally, we introduce a category-consistent loss to alleviate the over-category issues between K synthetic images. We evaluate our approach using the Birds-200-2011, Oxford-102 flower and MSCOCO 2014 datasets, and the extensive experiments demonstrate superiority of the proposed method in comparison with state-of-the-art methods in terms of photorealistic and diversity of the generated synthetic images.
Detail Preserved Point Cloud Completion via Separated Feature Aggregation
Jul 05, 2020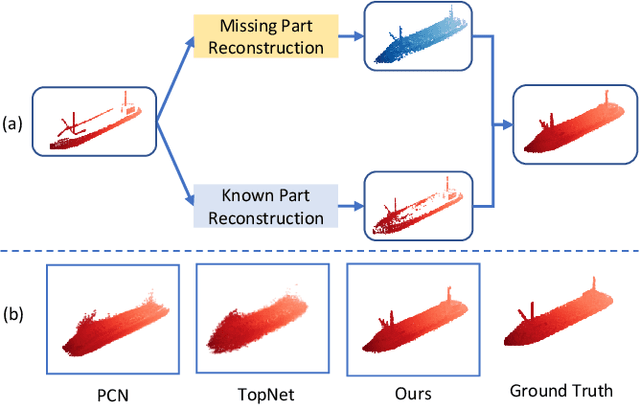
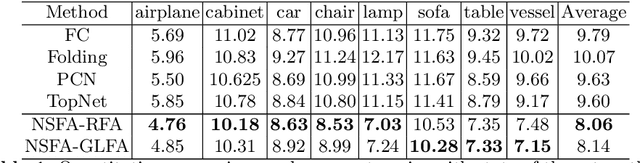
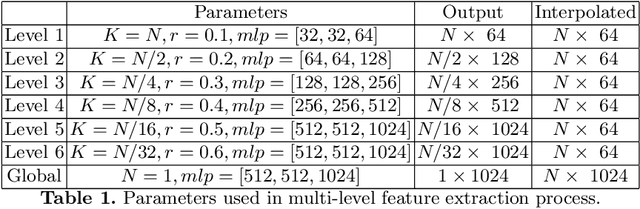
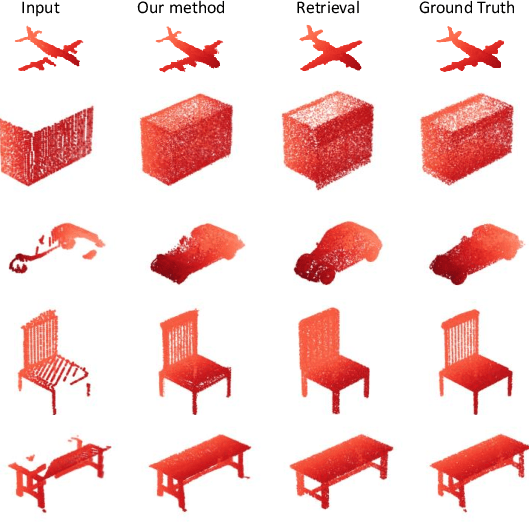
Point cloud shape completion is a challenging problem in 3D vision and robotics. Existing learning-based frameworks leverage encoder-decoder architectures to recover the complete shape from a highly encoded global feature vector. Though the global feature can approximately represent the overall shape of 3D objects, it would lead to the loss of shape details during the completion process. In this work, instead of using a global feature to recover the whole complete surface, we explore the functionality of multi-level features and aggregate different features to represent the known part and the missing part separately. We propose two different feature aggregation strategies, named global \& local feature aggregation(GLFA) and residual feature aggregation(RFA), to express the two kinds of features and reconstruct coordinates from their combination. In addition, we also design a refinement component to prevent the generated point cloud from non-uniform distribution and outliers. Extensive experiments have been conducted on the ShapeNet dataset. Qualitative and quantitative evaluations demonstrate that our proposed network outperforms current state-of-the art methods especially on detail preservation.
RIS-GAN: Explore Residual and Illumination with Generative Adversarial Networks for Shadow Removal
Dec 24, 2019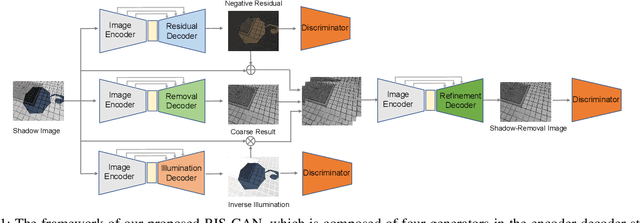
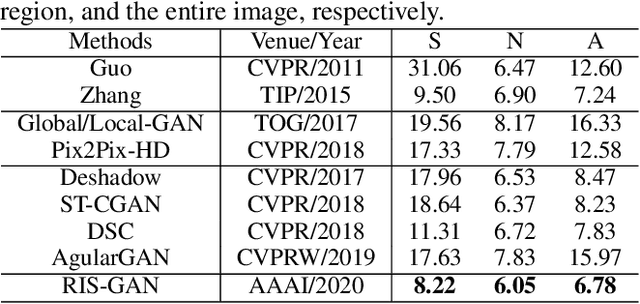

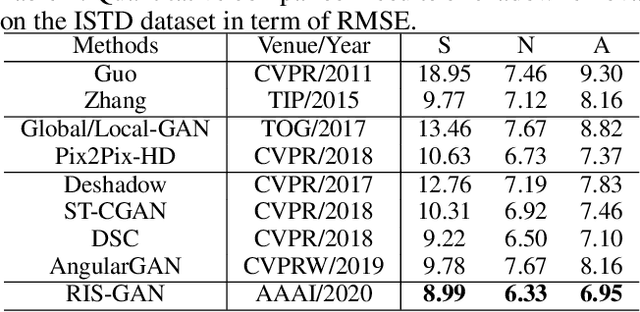
Residual images and illumination estimation have been proved very helpful in image enhancement. In this paper, we propose a general and novel framework RIS-GAN which explores residual and illumination with Generative Adversarial Networks for shadow removal. Combined with the coarse shadow-removal image, the estimated negative residual images and inverse illumination maps can be used to generate indirect shadow-removal images to refine the coarse shadow-removal result to the fine shadow-free image in a coarse-to-fine fashion. Three discriminators are designed to distinguish whether the predicted negative residual images, shadow-removal images, and the inverse illumination maps are real or fake jointly compared with the corresponding ground-truth information. To our best knowledge, we are the first one to explore residual and illumination for shadow removal. We evaluate our proposed method on two benchmark datasets, i.e., SRD and ISTD, and the extensive experiments demonstrate that our proposed method achieves the superior performance to state-of-the-arts, although we have no particular shadow-aware components designed in our generators.
ARGAN: Attentive Recurrent Generative Adversarial Network for Shadow Detection and Removal
Aug 04, 2019
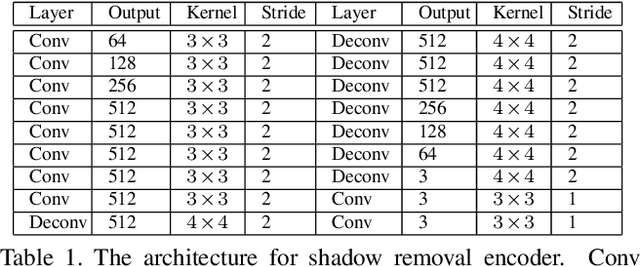
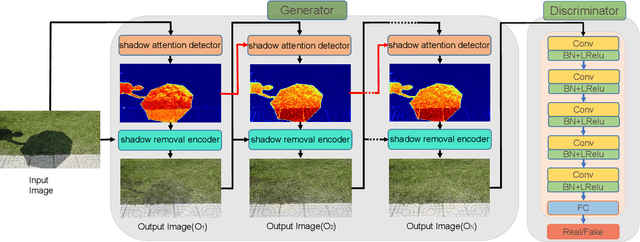
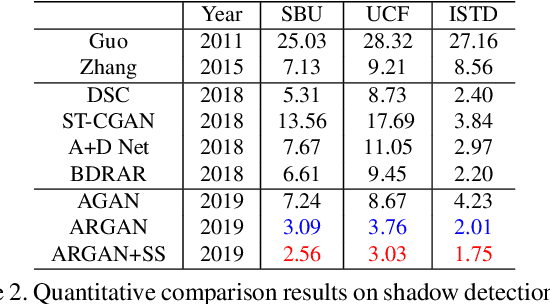
In this paper we propose an attentive recurrent generative adversarial network (ARGAN) to detect and remove shadows in an image. The generator consists of multiple progressive steps. At each step a shadow attention detector is firstly exploited to generate an attention map which specifies shadow regions in the input image.Given the attention map, a negative residual by a shadow remover encoder will recover a shadow-lighter or even a shadow-free image. A discriminator is designed to classify whether the output image in the last progressive step is real or fake. Moreover, ARGAN is suitable to be trained with a semi-supervised strategy to make full use of sufficient unsupervised data. The experiments on four public datasets have demonstrated that our ARGAN is robust to detect both simple and complex shadows and to produce more realistic shadow removal results. It outperforms the state-of-the-art methods, especially in detail of recovering shadow areas.
VITAL: A Visual Interpretation on Text with Adversarial Learning for Image Labeling
Aug 01, 2019
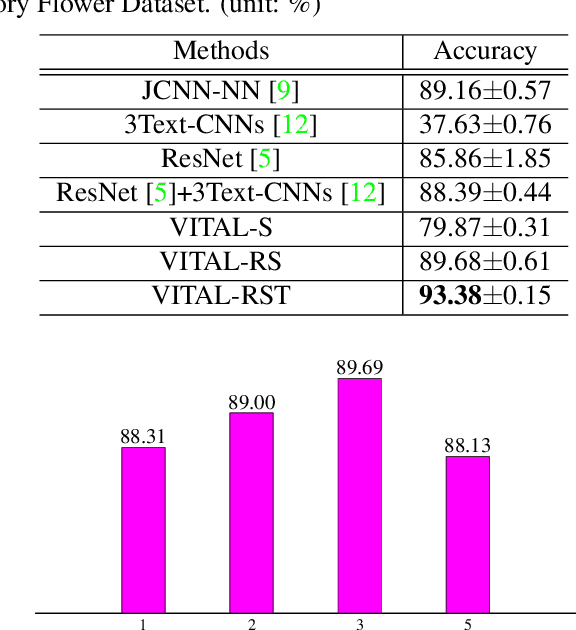
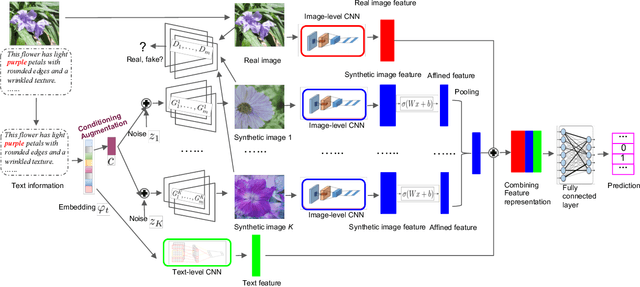
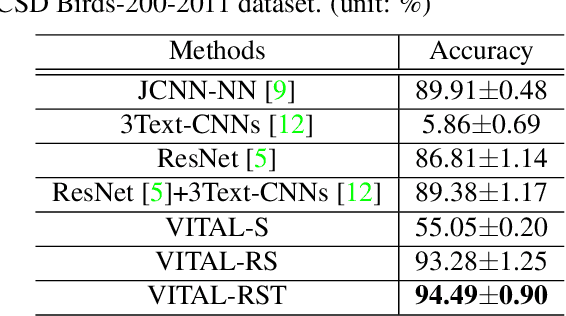
In this paper, we propose a novel way to interpret text information by extracting visual feature presentation from multiple high-resolution and photo-realistic synthetic images generated by Text-to-image Generative Adversarial Network (GAN) to improve the performance of image labeling. Firstly, we design a stacked Generative Multi-Adversarial Network (GMAN), StackGMAN++, a modified version of the current state-of-the-art Text-to-image GAN, StackGAN++, to generate multiple synthetic images with various prior noises conditioned on a text. And then we extract deep visual features from the generated synthetic images to explore the underlying visual concepts for text. Finally, we combine image-level visual feature, text-level feature and visual features based on synthetic images together to predict labels for images. We conduct experiments on two benchmark datasets and the experimental results clearly demonstrate the efficacy of our proposed approach.
Enhancing Underexposed Photos using Perceptually Bidirectional Similarity
Jul 25, 2019



This paper addresses the problem of enhancing underexposed photos. Existing methods have tackled this problem from many different perspectives and achieved remarkable progress. However, they may fail to produce satisfactory results due to the presence of visual artifacts such as color distortion, loss of details and uneven exposure, etc. To obtain high-quality results free of these artifacts, we present a novel underexposed photo enhancement approach in this paper. Our main observation is that, the reason why existing methods induce the artifacts is because they break a perceptual consistency between the input and the enhanced output. Based on this observation, an effective criterion, called perceptually bidirectional similarity (PBS) is proposed for preserving the perceptual consistency during enhancement. Particularly, we cast the underexposed photo enhancement as PBS-constrained illumination estimation optimization, where the PBS is defined as three constraints for estimating the illumination that can recover the enhancement results with normal exposure, distinct contrast, clear details and vivid color. To make our method more efficient and scalable to high-resolution images, we introduce a sampling-based strategy for accelerating the illumination estimation. Moreover, we extend our method to handle underexposed videos. Qualitative and quantitative comparisons as well as the user study demonstrate the superiority of our method over the state-of-the-art methods.
PCAN: 3D Attention Map Learning Using Contextual Information for Point Cloud Based Retrieval
Apr 22, 2019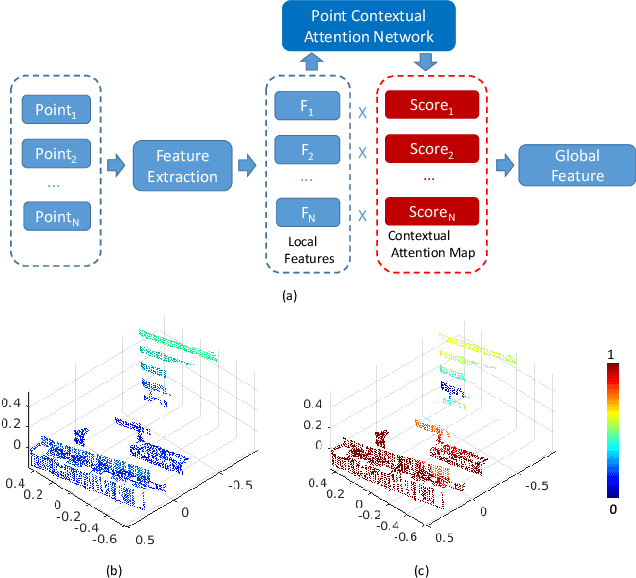

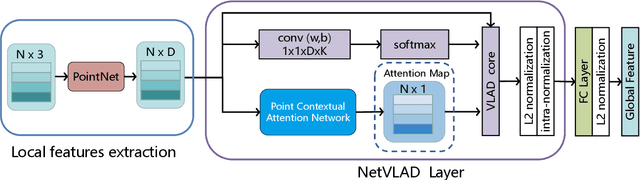
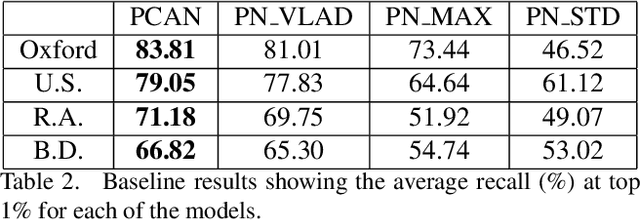
Point cloud based retrieval for place recognition is an emerging problem in vision field. The main challenge is how to find an efficient way to encode the local features into a discriminative global descriptor. In this paper, we propose a Point Contextual Attention Network (PCAN), which can predict the significance of each local point feature based on point context. Our network makes it possible to pay more attention to the task-relevent features when aggregating local features. Experiments on various benchmark datasets show that the proposed network can provide outperformance than current state-of-the-art approaches.