 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-Bench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
May 04, 2025Reasoning stands as a cornerstone of intelligence, enabling the synthesis of existing knowledge to solve complex problems. Despite remarkable progress, existing reasoning benchmarks often fail to rigorously evaluate the nuanced reasoning capabilities required for complex, real-world problemsolving, particularly in multi-disciplinary and multimodal contexts. In this paper, we introduce a graduate-level, multi-disciplinary, EnglishChinese benchmark, dubbed as Reasoning Bench (R-Bench), for assessing the reasoning capability of both language and multimodal models. RBench spans 1,094 questions across 108 subjects for language model evaluation and 665 questions across 83 subjects for multimodal model testing in both English and Chinese. These questions are meticulously curated to ensure rigorous difficulty calibration, subject balance, and crosslinguistic alignment, enabling the assessment to be an Olympiad-level multi-disciplinary benchmark. We evaluate widely used models, including OpenAI o1, GPT-4o, DeepSeek-R1, etc. Experimental results indicate that advanced models perform poorly on complex reasoning, especially multimodal reasoning. Even the top-performing model OpenAI o1 achieves only 53.2% accuracy on our multimodal evaluation. Data and code are made publicly available at here.
Dual Graph Convolutional Networks with Transformer and Curriculum Learning for Image Captioning
Aug 05, 2021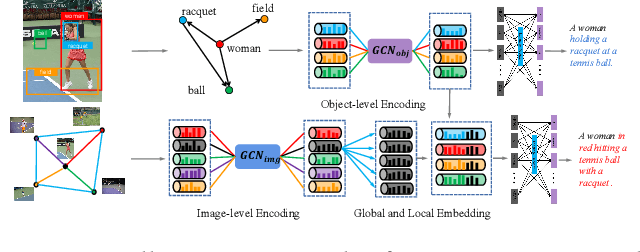

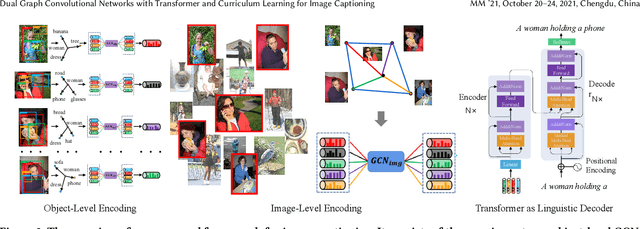
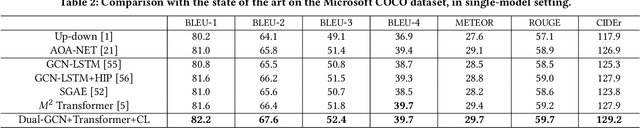
Existing image captioning methods just focus on understanding the relationship between objects or instances in a single image, without exploring the contextual correlation existed among contextual image. In this paper, we propose Dual Graph Convolutional Networks (Dual-GCN) with transformer and curriculum learning for image captioning. In particular, we not only use an object-level GCN to capture the object to object spatial relation within a single image, but also adopt an image-level GCN to capture the feature information provided by similar images. With the well-designed Dual-GCN, we can make the linguistic transformer better understand the relationship between different objects in a single image and make full use of similar images as auxiliary information to generate a reasonable caption description for a single image. Meanwhile, with a cross-review strategy introduced to determine difficulty levels, we adopt curriculum learning as the training strategy to increase the robustness and generalization of our proposed model. We conduct extensive experiments on the large-scale MS COCO dataset, and the experimental results powerfully demonstrate that our proposed method outperforms recent state-of-the-art approaches. It achieves a BLEU-1 score of 82.2 and a BLEU-2 score of 67.6. Our source code is available at {\em \color{magenta}{\url{https://github.com/Unbear430/DGCN-for-image-captioning}}}.