 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScatterbrain: Unifying Sparse and Low-rank Attention Approximation
Oct 28, 2021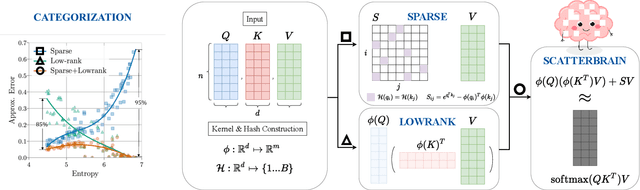


Recent advances in efficient Transformers have exploited either the sparsity or low-rank properties of attention matrices to reduce the computational and memory bottlenecks of modeling long sequences. However, it is still challenging to balance the trade-off between model quality and efficiency to perform a one-size-fits-all approximation for different tasks. To better understand this trade-off, we observe that sparse and low-rank approximations excel in different regimes, determined by the softmax temperature in attention, and sparse + low-rank can outperform each individually. Inspired by the classical robust-PCA algorithm for sparse and low-rank decomposition, we propose Scatterbrain, a novel way to unify sparse (via locality sensitive hashing) and low-rank (via kernel feature map) attention for accurate and efficient approximation. The estimation is unbiased with provably low error. We empirically show that Scatterbrain can achieve 2.1x lower error than baselines when serving as a drop-in replacement in BigGAN image generation and pre-trained T2T-ViT. On a pre-trained T2T Vision transformer, even without fine-tuning, Scatterbrain can reduce 98% of attention memory at the cost of only 1% drop in accuracy. We demonstrate Scatterbrain for end-to-end training with up to 4 points better perplexity and 5 points better average accuracy than sparse or low-rank efficient transformers on language modeling and long-range-arena tasks.
Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers
Oct 26, 2021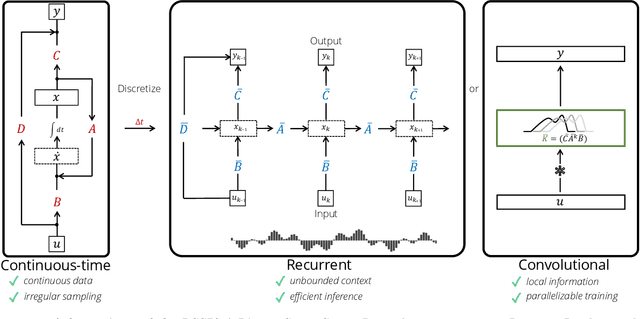
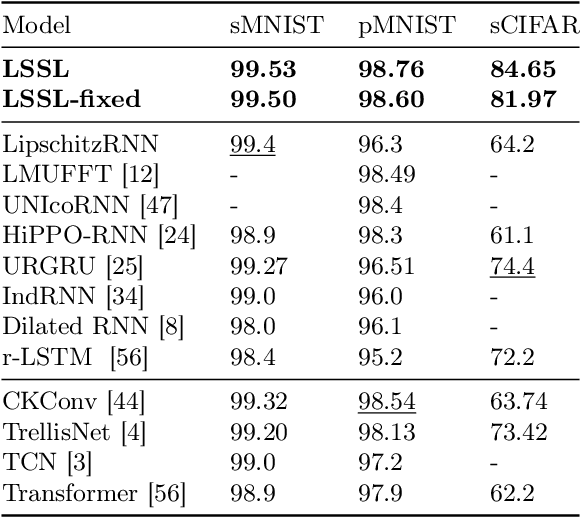
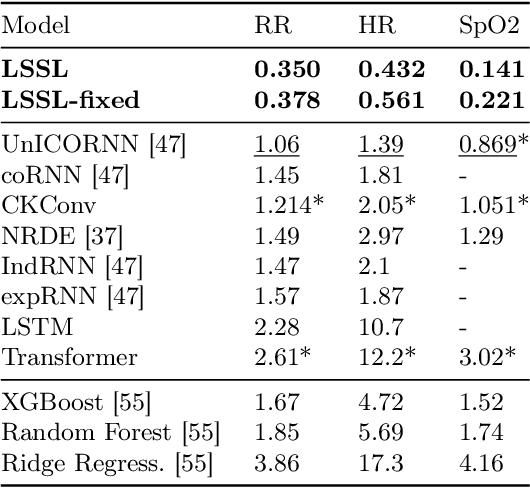
Recurrent neural networks (RNNs), temporal convolutions, and neural differential equations (NDEs) are popular families of deep learning models for time-series data, each with unique strengths and tradeoffs in modeling power and computational efficiency. We introduce a simple sequence model inspired by control systems that generalizes these approaches while addressing their shortcomings. The Linear State-Space Layer (LSSL) maps a sequence $u \mapsto y$ by simply simulating a linear continuous-time state-space representation $\dot{x} = Ax + Bu, y = Cx + Du$. Theoretically, we show that LSSL models are closely related to the three aforementioned families of models and inherit their strengths. For example, they generalize convolutions to continuous-time, explain common RNN heuristics, and share features of NDEs such as time-scale adaptation. We then incorporate and generalize recent theory on continuous-time memorization to introduce a trainable subset of structured matrices $A$ that endow LSSLs with long-range memory. Empirically, stacking LSSL layers into a simple deep neural network obtains state-of-the-art results across time series benchmarks for long dependencies in sequential image classification, real-world healthcare regression tasks, and speech. On a difficult speech classification task with length-16000 sequences, LSSL outperforms prior approaches by 24 accuracy points, and even outperforms baselines that use hand-crafted features on 100x shorter sequences.
Cross-Domain Data Integration for Named Entity Disambiguation in Biomedical Text
Oct 15, 2021Named entity disambiguation (NED), which involves mapping textual mentions to structured entities, is particularly challenging in the medical domain due to the presence of rare entities. Existing approaches are limited by the presence of coarse-grained structural resources in biomedical knowledge bases as well as the use of training datasets that provide low coverage over uncommon resources. In this work, we address these issues by proposing a cross-domain data integration method that transfers structural knowledge from a general text knowledge base to the medical domain. We utilize our integration scheme to augment structural resources and generate a large biomedical NED dataset for pretraining. Our pretrained model with injected structural knowledge achieves state-of-the-art performance on two benchmark medical NED datasets: MedMentions and BC5CDR. Furthermore, we improve disambiguation of rare entities by up to 57 accuracy points.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Challenges for cognitive decoding using deep learning methods
Aug 16, 2021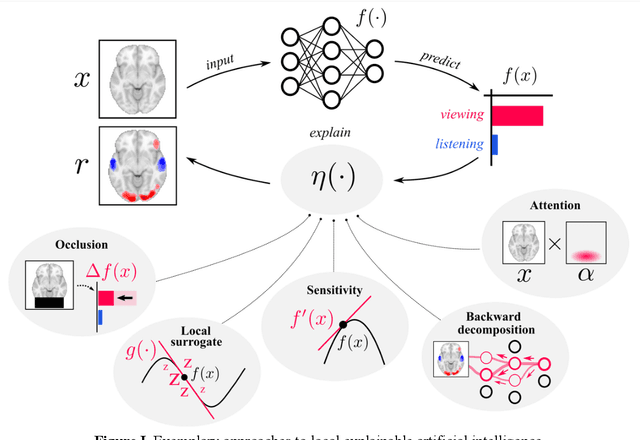
In cognitive decoding, researchers aim to characterize a brain region's representations by identifying the cognitive states (e.g., accepting/rejecting a gamble) that can be identified from the region's activity. Deep learning (DL) methods are highly promising for cognitive decoding, with their unmatched ability to learn versatile representations of complex data. Yet, their widespread application in cognitive decoding is hindered by their general lack of interpretability as well as difficulties in applying them to small datasets and in ensuring their reproducibility and robustness. We propose to approach these challenges by leveraging recent advances in explainable artificial intelligence and transfer learning, while also providing specific recommendations on how to improve the reproducibility and robustness of DL modeling results.
Declarative Machine Learning Systems
Jul 16, 2021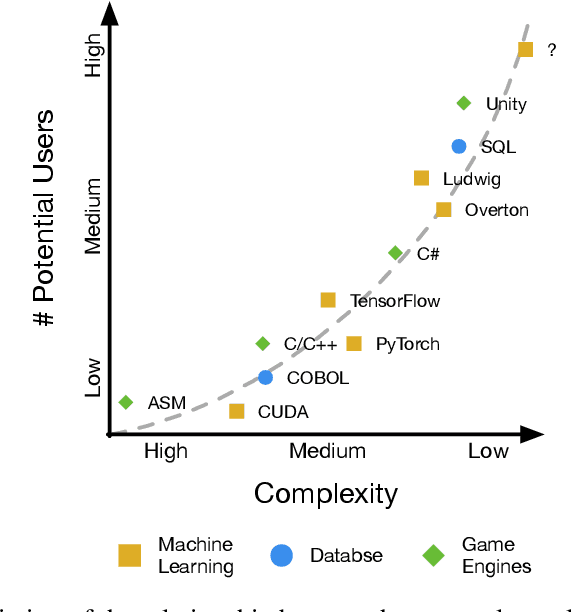
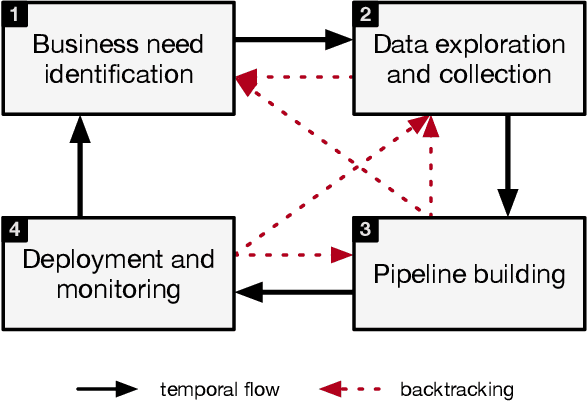


In the last years machine learning (ML) has moved from a academic endeavor to a pervasive technology adopted in almost every aspect of computing. ML-powered products are now embedded in our digital lives: from recommendations of what to watch, to divining our search intent, to powering virtual assistants in consumer and enterprise settings. Recent successes in applying ML in natural sciences revealed that ML can be used to tackle some of the hardest real-world problems humanity faces today. For these reasons ML has become central in the strategy of tech companies and has gathered even more attention from academia than ever before. Despite these successes, what we have witnessed so far is just the beginning. Right now the people training and using ML models are expert developers working within large organizations, but we believe the next wave of ML systems will allow a larger amount of people, potentially without coding skills, to perform the same tasks. These new ML systems will not require users to fully understand all the details of how models are trained and utilized for obtaining predictions. Declarative interfaces are well suited for this goal, by hiding complexity and favouring separation of interests, and can lead to increased productivity. We worked on such abstract interfaces by developing two declarative ML systems, Overton and Ludwig, that require users to declare only their data schema (names and types of inputs) and tasks rather then writing low level ML code. In this article we will describe how ML systems are currently structured, highlight important factors for their success and adoption, what are the issues current ML systems are facing and how the systems we developed addressed them. Finally we will talk about learnings from the development of ML systems throughout the years and how we believe the next generation of ML systems will look like.
Mandoline: Model Evaluation under Distribution Shift
Jul 01, 2021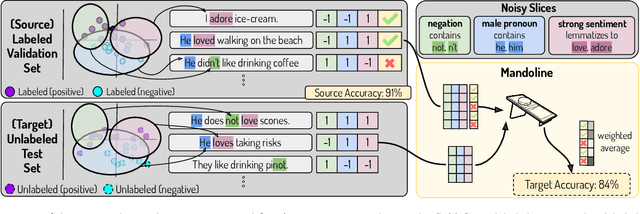
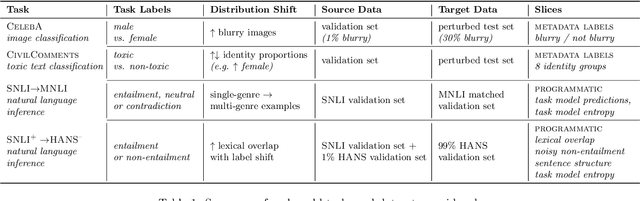
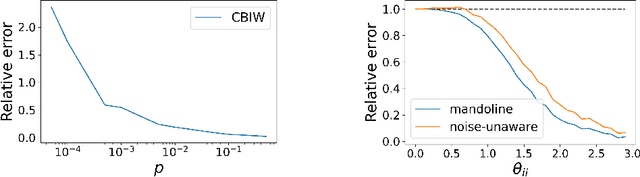
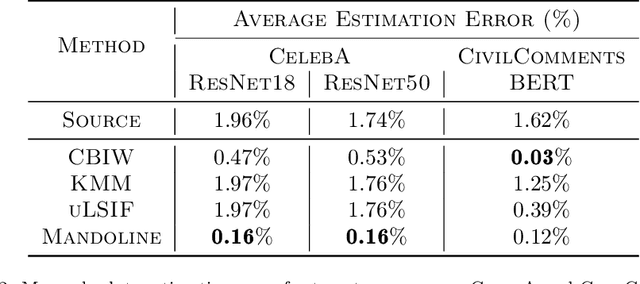
Machine learning models are often deployed in different settings than they were trained and validated on, posing a challenge to practitioners who wish to predict how well the deployed model will perform on a target distribution. If an unlabeled sample from the target distribution is available, along with a labeled sample from a possibly different source distribution, standard approaches such as importance weighting can be applied to estimate performance on the target. However, importance weighting struggles when the source and target distributions have non-overlapping support or are high-dimensional. Taking inspiration from fields such as epidemiology and polling, we develop Mandoline, a new evaluation framework that mitigates these issues. Our key insight is that practitioners may have prior knowledge about the ways in which the distribution shifts, which we can use to better guide the importance weighting procedure. Specifically, users write simple "slicing functions" - noisy, potentially correlated binary functions intended to capture possible axes of distribution shift - to compute reweighted performance estimates. We further describe a density ratio estimation framework for the slices and show how its estimation error scales with slice quality and dataset size. Empirical validation on NLP and vision tasks shows that \name can estimate performance on the target distribution up to $3\times$ more accurately compared to standard baselines.
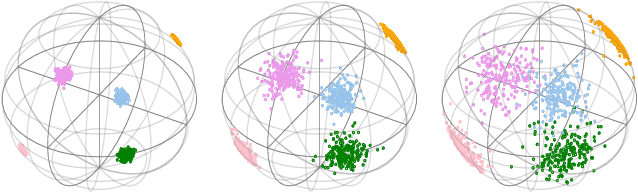
HoroPCA: Hyperbolic Dimensionality Reduction via Horospherical Projections
Jun 07, 2021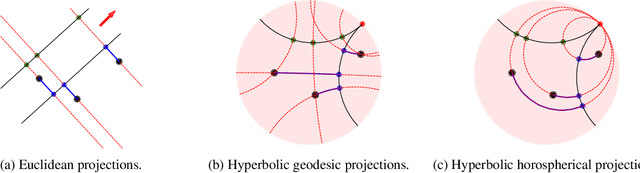
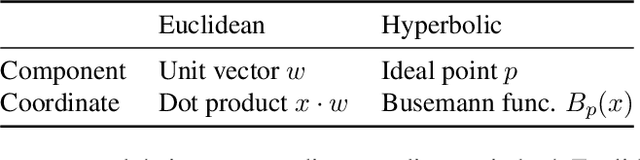
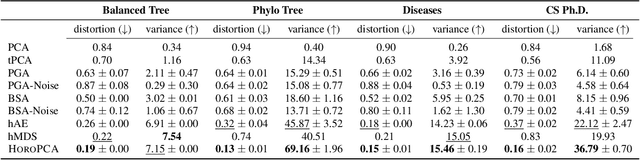
This paper studies Principal Component Analysis (PCA) for data lying in hyperbolic spaces. Given directions, PCA relies on: (1) a parameterization of subspaces spanned by these directions, (2) a method of projection onto subspaces that preserves information in these directions, and (3) an objective to optimize, namely the variance explained by projections. We generalize each of these concepts to the hyperbolic space and propose HoroPCA, a method for hyperbolic dimensionality reduction. By focusing on the core problem of extracting principal directions, HoroPCA theoretically better preserves information in the original data such as distances, compared to previous generalizations of PCA. Empirically, we validate that HoroPCA outperforms existing dimensionality reduction methods, significantly reducing error in distance preservation. As a data whitening method, it improves downstream classification by up to 3.9% compared to methods that don't use whitening. Finally, we show that HoroPCA can be used to visualize hyperbolic data in two dimensions.
Ember: No-Code Context Enrichment via Similarity-Based Keyless Joins
Jun 02, 2021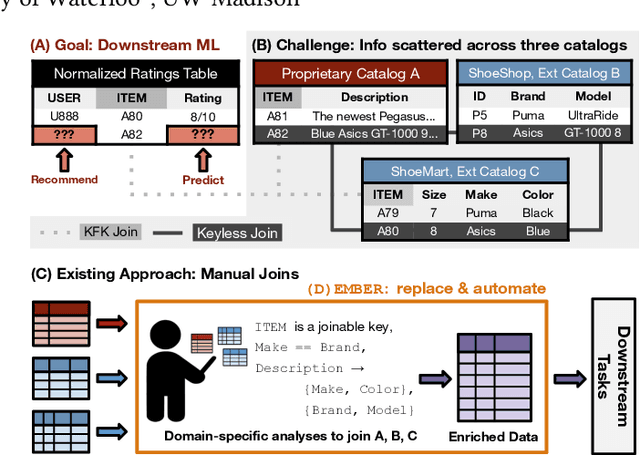
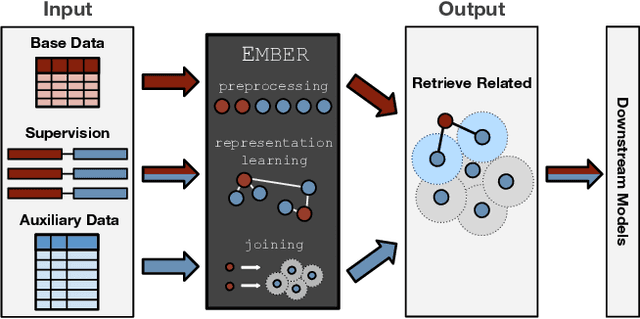
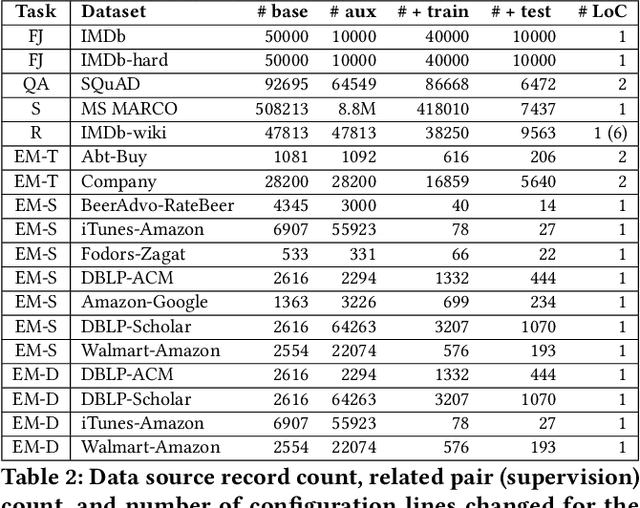
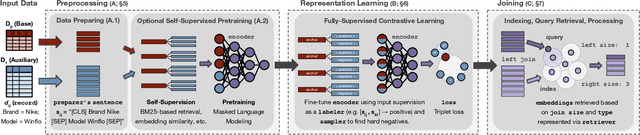
Structured data, or data that adheres to a pre-defined schema, can suffer from fragmented context: information describing a single entity can be scattered across multiple datasets or tables tailored for specific business needs, with no explicit linking keys (e.g., primary key-foreign key relationships or heuristic functions). Context enrichment, or rebuilding fragmented context, using keyless joins is an implicit or explicit step in machine learning (ML) pipelines over structured data sources. This process is tedious, domain-specific, and lacks support in now-prevalent no-code ML systems that let users create ML pipelines using just input data and high-level configuration files. In response, we propose Ember, a system that abstracts and automates keyless joins to generalize context enrichment. Our key insight is that Ember can enable a general keyless join operator by constructing an index populated with task-specific embeddings. Ember learns these embeddings by leveraging Transformer-based representation learning techniques. We describe our core architectural principles and operators when developing Ember, and empirically demonstrate that Ember allows users to develop no-code pipelines for five domains, including search, recommendation and question answering, and can exceed alternatives by up to 39% recall, with as little as a single line configuration change.
Rethinking Neural Operations for Diverse Tasks
Mar 29, 2021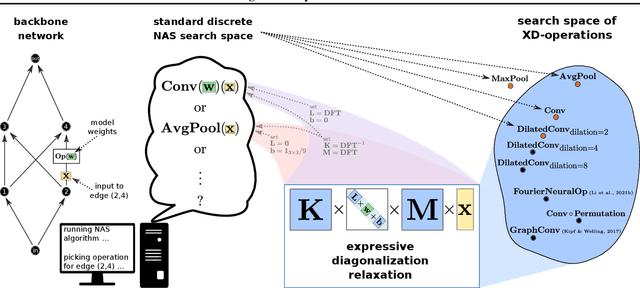
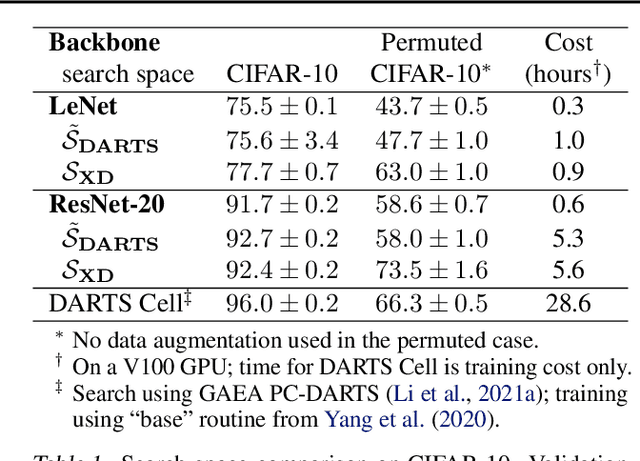
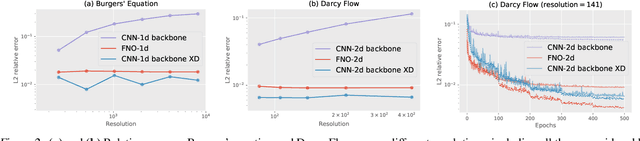

An important goal of neural architecture search (NAS) is to automate-away the design of neural networks on new tasks in under-explored domains. Motivated by this broader vision for NAS, we study the problem of enabling users to discover the right neural operations given data from their specific domain. We introduce a search space of neural operations called XD-Operations that mimic the inductive bias of standard multichannel convolutions while being much more expressive: we prove that XD-operations include many named operations across several application areas. Starting with any standard backbone network such as LeNet or ResNet, we show how to transform it into an architecture search space over XD-operations and how to traverse the space using a simple weight-sharing scheme. On a diverse set of applications--image classification, solving partial differential equations (PDEs), and sequence modeling--our approach consistently yields models with lower error than baseline networks and sometimes even lower error than expert-designed domain-specific approaches.