 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Soft Advantage Fitting: Imitation Learning without Policy Optimization
Jun 23, 2020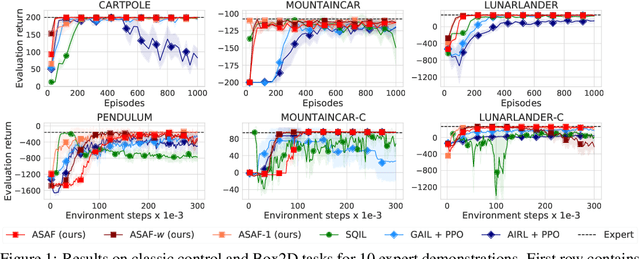
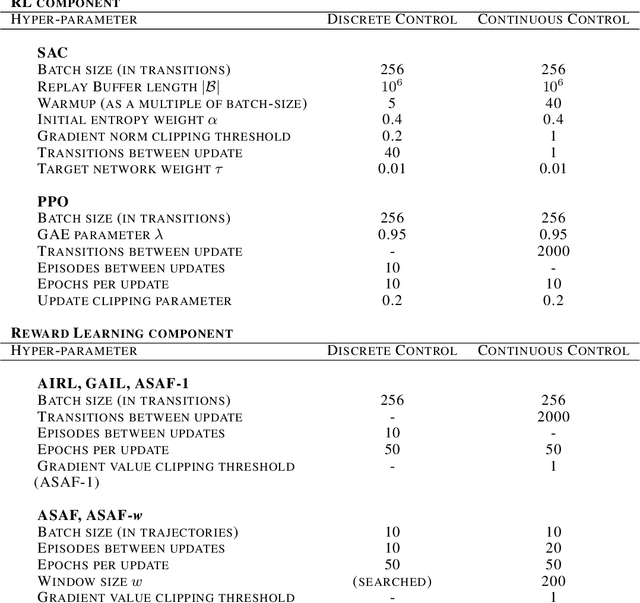
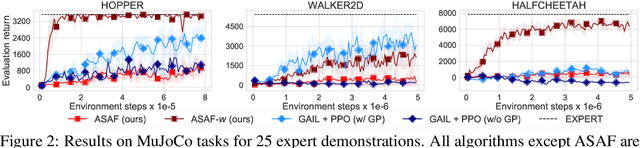
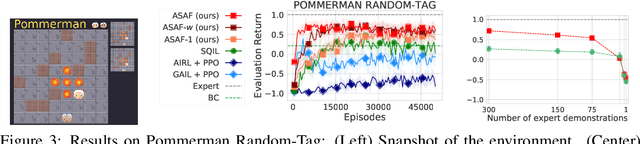
Adversarial imitation learning alternates between learning a discriminator -- which tells apart expert's demonstrations from generated ones -- and a generator's policy to produce trajectories that can fool this discriminator. This alternated optimization is known to be delicate in practice since it compounds unstable adversarial training with brittle and sample-inefficient reinforcement learning. We propose to remove the burden of the policy optimization steps by leveraging a novel discriminator formulation. Specifically, our discriminator is explicitly conditioned on two policies: the one from the previous generator's iteration and a learnable policy. When optimized, this discriminator directly learns the optimal generator's policy. Consequently, our discriminator's update solves the generator's optimization problem for free: learning a policy that imitates the expert does not require an additional optimization loop. This formulation effectively cuts by half the implementation and computational burden of adversarial imitation learning algorithms by removing the reinforcement learning phase altogether. We show on a variety of tasks that our simpler approach is competitive to prevalent imitation learning methods.
AR-DAE: Towards Unbiased Neural Entropy Gradient Estimation
Jun 09, 2020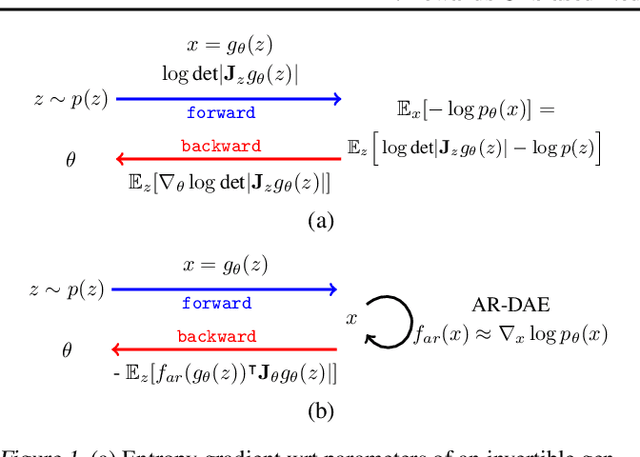
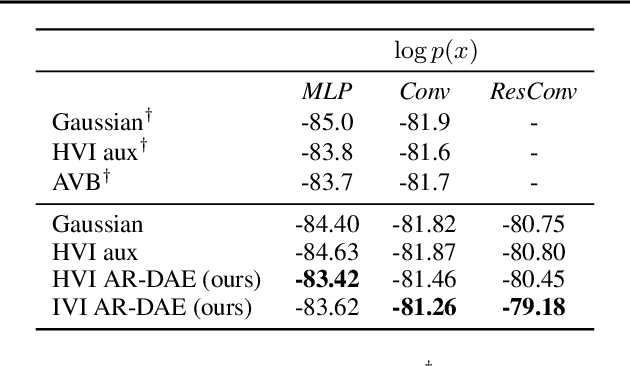
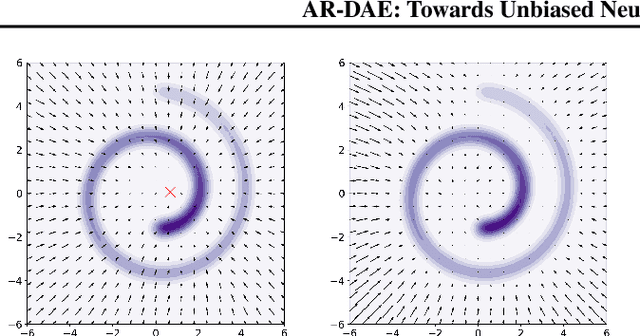

Entropy is ubiquitous in machine learning, but it is in general intractable to compute the entropy of the distribution of an arbitrary continuous random variable. In this paper, we propose the amortized residual denoising autoencoder (AR-DAE) to approximate the gradient of the log density function, which can be used to estimate the gradient of entropy. Amortization allows us to significantly reduce the error of the gradient approximator by approaching asymptotic optimality of a regular DAE, in which case the estimation is in theory unbiased. We conduct theoretical and experimental analyses on the approximation error of the proposed method, as well as extensive studies on heuristics to ensure its robustness. Finally, using the proposed gradient approximator to estimate the gradient of entropy, we demonstrate state-of-the-art performance on density estimation with variational autoencoders and continuous control with soft actor-critic.
On the impressive performance of randomly weighted encoders in summarization tasks
Feb 21, 2020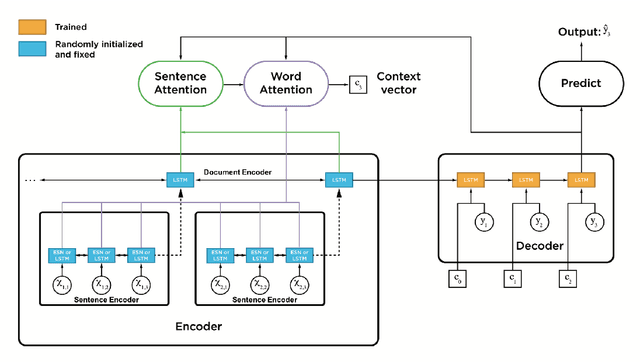
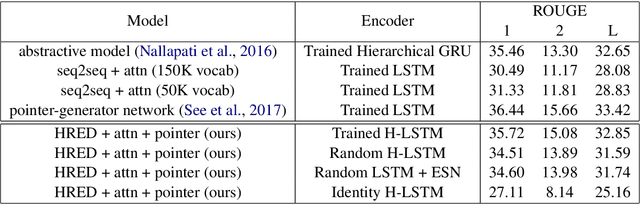
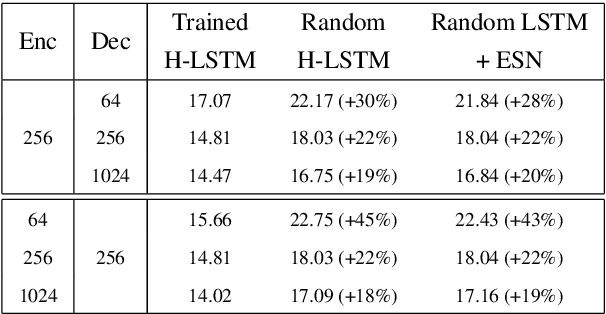
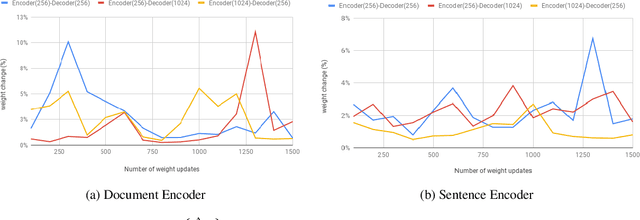
In this work, we investigate the performance of untrained randomly initialized encoders in a general class of sequence to sequence models and compare their performance with that of fully-trained encoders on the task of abstractive summarization. We hypothesize that random projections of an input text have enough representational power to encode the hierarchical structure of sentences and semantics of documents. Using a trained decoder to produce abstractive text summaries, we empirically demonstrate that architectures with untrained randomly initialized encoders perform competitively with respect to the equivalent architectures with fully-trained encoders. We further find that the capacity of the encoder not only improves overall model generalization but also closes the performance gap between untrained randomly initialized and full-trained encoders. To our knowledge, it is the first time that general sequence to sequence models with attention are assessed for trained and randomly projected representations on abstractive summarization.
Exploring Structural Inductive Biases in Emergent Communication
Feb 04, 2020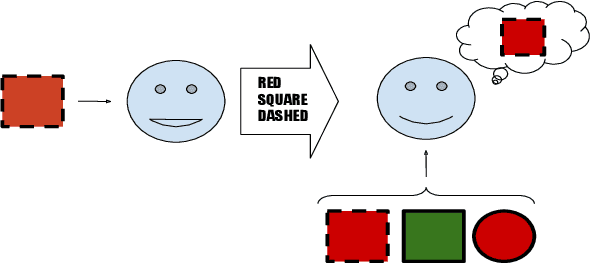
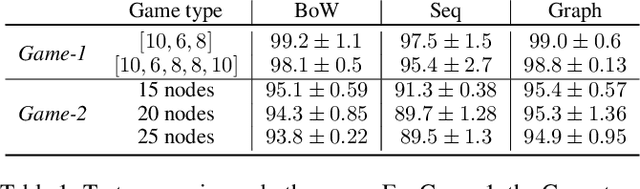
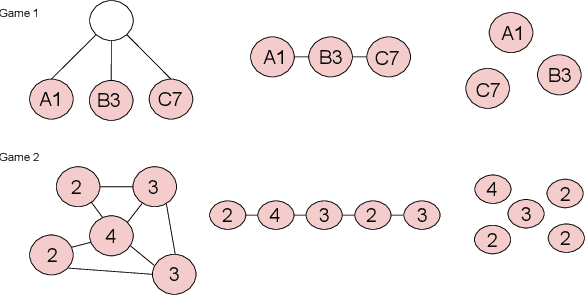
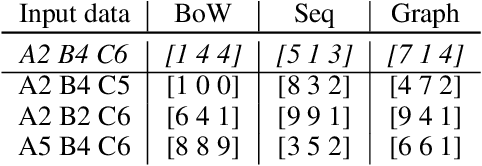
Human language and thought are characterized by the ability to systematically generate a potentially infinite number of complex structures (e.g., sentences) from a finite set of familiar components (e.g., words). Recent works in emergent communication have discussed the propensity of artificial agents to develop a systematically compositional language through playing co-operative referential games. The degree of structure in the input data was found to affect the compositionality of the emerged communication protocols. Thus, we explore various structural priors in multi-agent communication and propose a novel graph referential game. We compare the effect of structural inductive bias (bag-of-words, sequences and graphs) on the emergence of compositional understanding of the input concepts measured by topographic similarity and generalization to unseen combinations of familiar properties. We empirically show that graph neural networks induce a better compositional language prior and a stronger generalization to out-of-domain data. We further perform ablation studies that show the robustness of the emerged protocol in graph referential games.
Real-Time Reinforcement Learning
Dec 12, 2019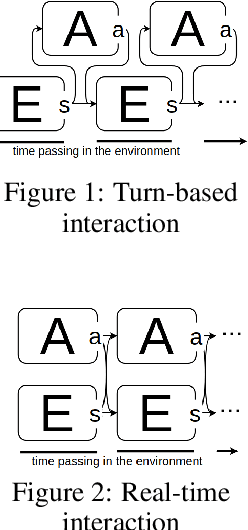
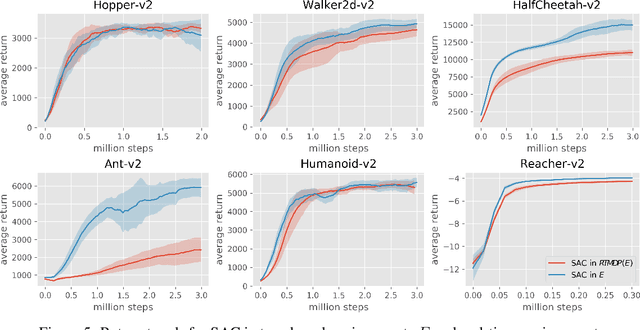
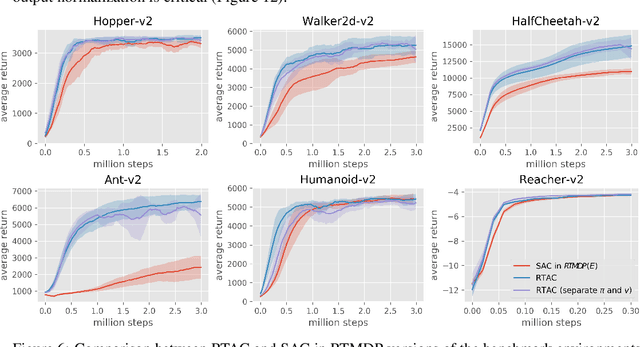
Markov Decision Processes (MDPs), the mathematical framework underlying most algorithms in Reinforcement Learning (RL), are often used in a way that wrongfully assumes that the state of an agent's environment does not change during action selection. As RL systems based on MDPs begin to find application in real-world safety critical situations, this mismatch between the assumptions underlying classical MDPs and the reality of real-time computation may lead to undesirable outcomes. In this paper, we introduce a new framework, in which states and actions evolve simultaneously and show how it is related to the classical MDP formulation. We analyze existing algorithms under the new real-time formulation and show why they are suboptimal when used in real-time. We then use those insights to create a new algorithm Real-Time Actor-Critic (RTAC) that outperforms the existing state-of-the-art continuous control algorithm Soft Actor-Critic both in real-time and non-real-time settings. Code and videos can be found at https://github.com/rmst/rtrl.
Neural Multisensory Scene Inference
Nov 08, 2019
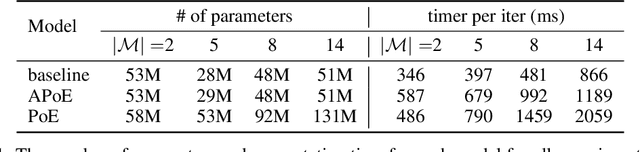
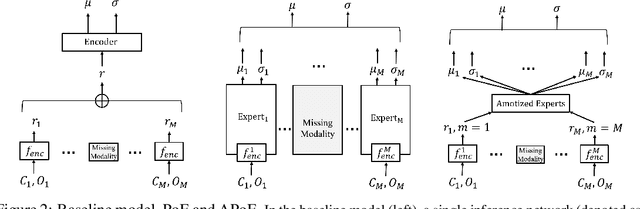
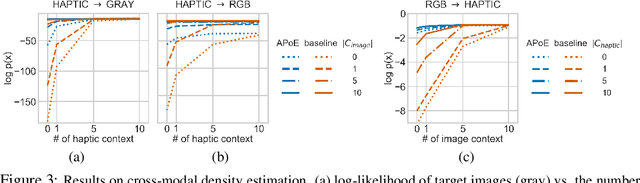
For embodied agents to infer representations of the underlying 3D physical world they inhabit, they should efficiently combine multisensory cues from numerous trials, e.g., by looking at and touching objects. Despite its importance, multisensory 3D scene representation learning has received less attention compared to the unimodal setting. In this paper, we propose the Generative Multisensory Network (GMN) for learning latent representations of 3D scenes which are partially observable through multiple sensory modalities. We also introduce a novel method, called the Amortized Product-of-Experts, to improve the computational efficiency and the robustness to unseen combinations of modalities at test time. Experimental results demonstrate that the proposed model can efficiently infer robust modality-invariant 3D-scene representations from arbitrary combinations of modalities and perform accurate cross-modal generation. To perform this exploration, we also develop the Multisensory Embodied 3D-Scene Environment (MESE).
On Extractive and Abstractive Neural Document Summarization with Transformer Language Models
Sep 07, 2019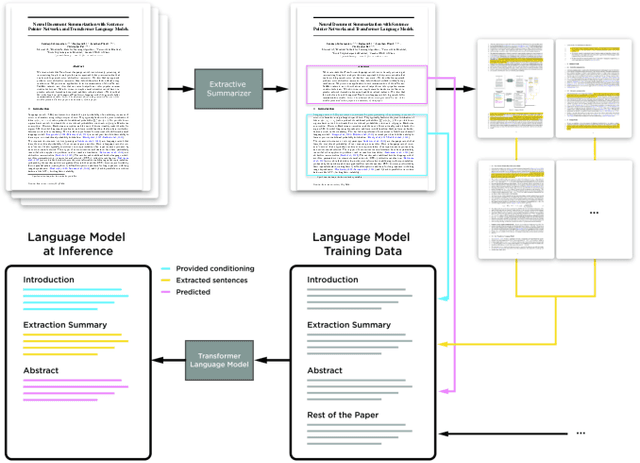
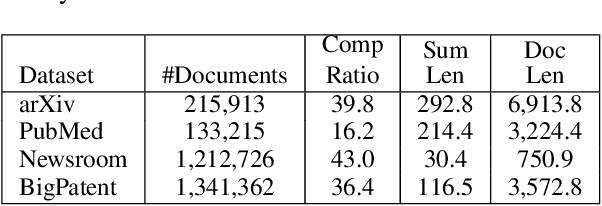
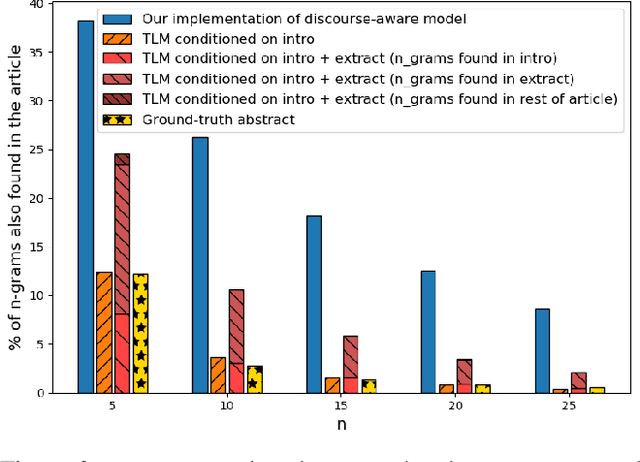
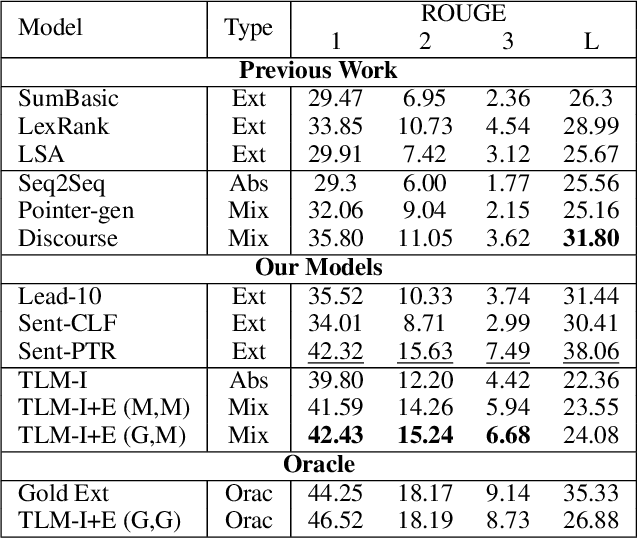
We present a method to produce abstractive summaries of long documents that exceed several thousand words via neural abstractive summarization. We perform a simple extractive step before generating a summary, which is then used to condition the transformer language model on relevant information before being tasked with generating a summary. We show that this extractive step significantly improves summarization results. We also show that this approach produces more abstractive summaries compared to prior work that employs a copy mechanism while still achieving higher rouge scores. Note: The abstract above was not written by the authors, it was generated by one of the models presented in this paper.
Interactive Machine Comprehension with Information Seeking Agents
Sep 04, 2019
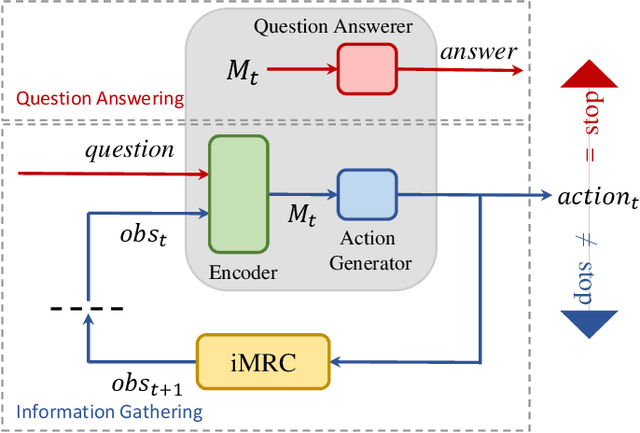
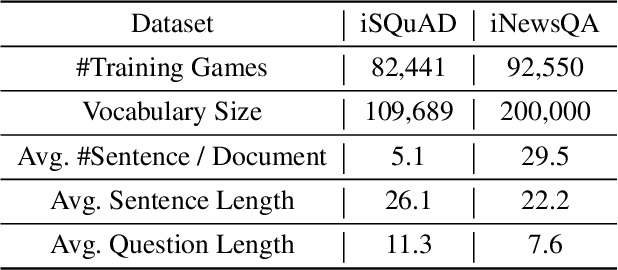
Existing machine reading comprehension (MRC) models do not scale effectively to real-world applications like web-level information retrieval and question answering (QA). We argue that this stems from the nature of MRC datasets: most of these are static environments wherein the supporting documents and all necessary information are fully observed. In this paper, we propose a simple method that reframes existing MRC datasets as interactive, partially observable environments. Specifically, we "occlude" the majority of a document's text and add context-sensitive commands that reveal "glimpses" of the hidden text to a model. We repurpose SQuAD and NewsQA as an initial case study, and then show how the interactive corpora can be used to train a model that seeks relevant information through sequential decision making. We believe that this setting can contribute in scaling models to web-level QA scenarios.
Interactive Language Learning by Question Answering
Aug 28, 2019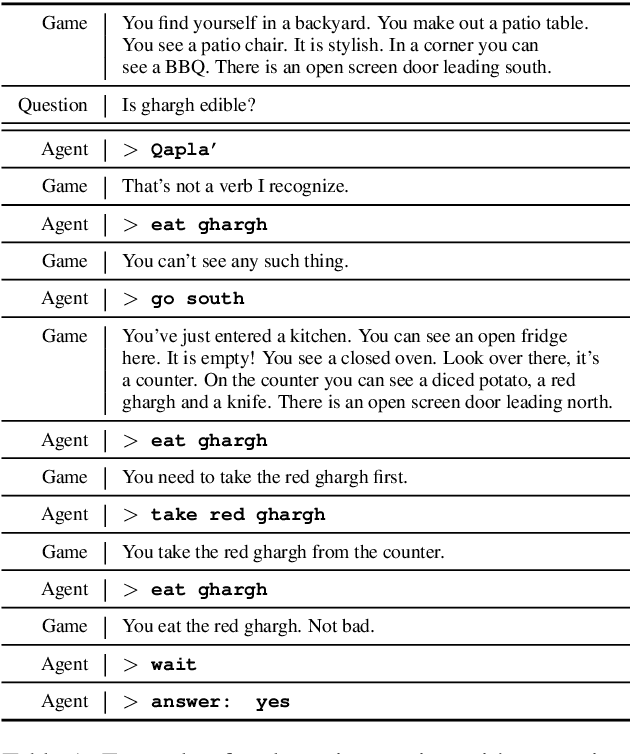
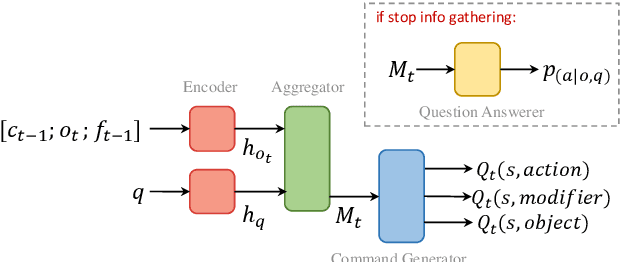
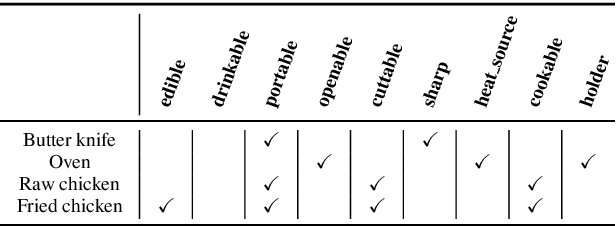
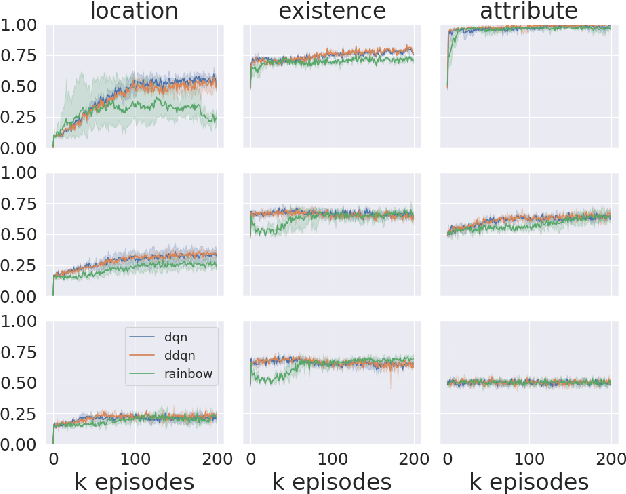
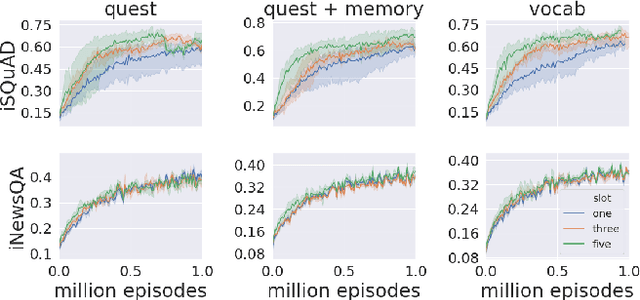
Humans observe and interact with the world to acquire knowledge. However, most existing machine reading comprehension (MRC) tasks miss the interactive, information-seeking component of comprehension. Such tasks present models with static documents that contain all necessary information, usually concentrated in a single short substring. Thus, models can achieve strong performance through simple word- and phrase-based pattern matching. We address this problem by formulating a novel text-based question answering task: Question Answering with Interactive Text (QAit). In QAit, an agent must interact with a partially observable text-based environment to gather information required to answer questions. QAit poses questions about the existence, location, and attributes of objects found in the environment. The data is built using a text-based game generator that defines the underlying dynamics of interaction with the environment. We propose and evaluate a set of baseline models for the QAit task that includes deep reinforcement learning agents. Experiments show that the task presents a major challenge for machine reading systems, while humans solve it with relative ease.
Promoting Coordination through Policy Regularization in Multi-Agent Reinforcement Learning
Aug 06, 2019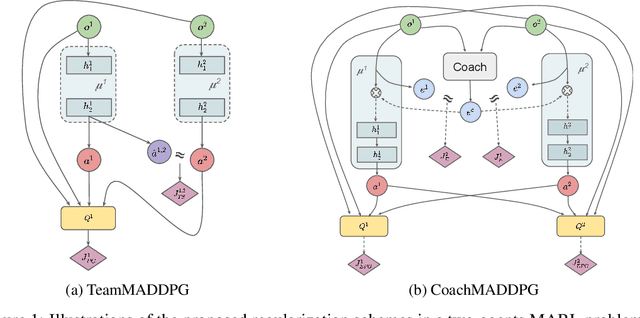
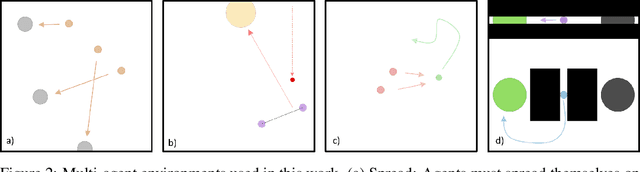
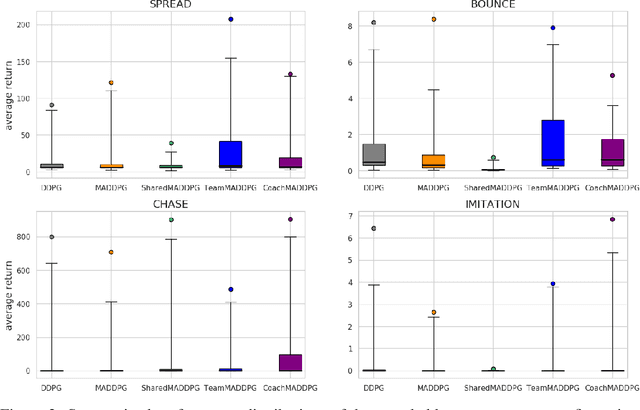
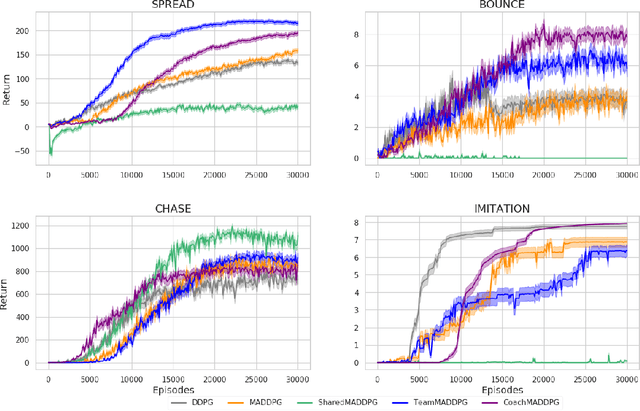
A central challenge in multi-agent reinforcement learning is the induction of coordination between agents of a team. In this work, we investigate how to promote inter-agent coordination and discuss two possible avenues based respectively on inter-agent modelling and guided synchronized sub-policies. We test each approach in four challenging continuous control tasks with sparse rewards and compare them against three variants of MADDPG, a state-of-the-art multi-agent reinforcement learning algorithm. To ensure a fair comparison, we rely on a thorough hyper-parameter selection and training methodology that allows a fixed hyper-parameter search budget for each algorithm and environment. We consequently assess both the hyper-parameter sensitivity, sample-efficiency and asymptotic performance of each learning method. Our experiments show that our proposed algorithms are more robust to the hyper-parameter choice and reliably lead to strong results.