 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural-Symbolic Descriptive Planning Models via Cube-Space Priors: The Voyage Home (to STRIPS)
Apr 27, 2020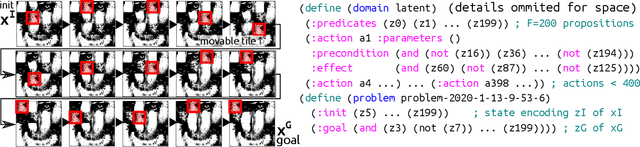



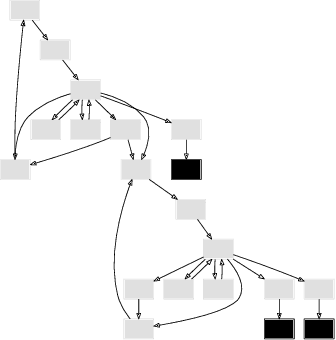
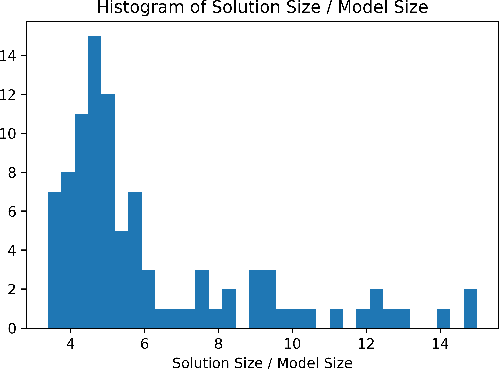
We achieved a new milestone in the difficult task of enabling agents to learn about their environment autonomously. Our neuro-symbolic architecture is trained end-to-end to produce a succinct and effective discrete state transition model from images alone. Our target representation (the Planning Domain Definition Language) is already in a form that off-the-shelf solvers can consume, and opens the door to the rich array of modern heuristic search capabilities. We demonstrate how the sophisticated innate prior we place on the learning process significantly reduces the complexity of the learned representation, and reveals a connection to the graph-theoretic notion of "cube-like graphs", thus opening the door to a deeper understanding of the ideal properties for learned symbolic representations. We show that the powerful domain-independent heuristics allow our system to solve visual 15-Puzzle instances which are beyond the reach of blind search, without resorting to the Reinforcement Learning approach that requires a huge amount of training on the domain-dependent reward information.
Planning for Goal-Oriented Dialogue Systems
Oct 17, 2019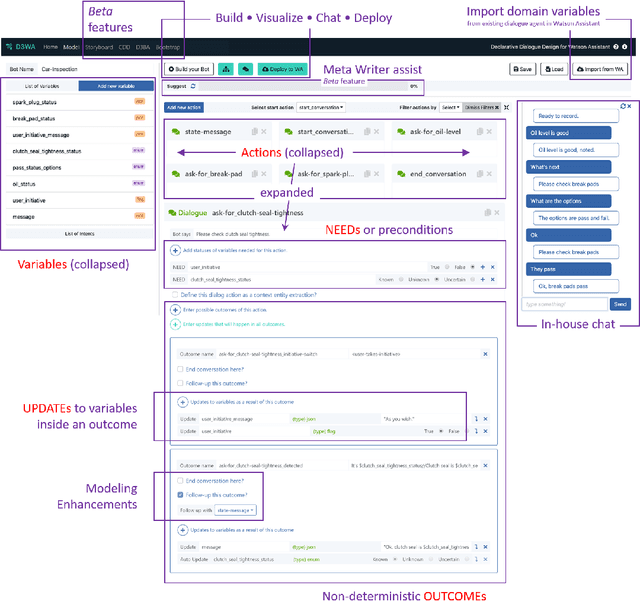
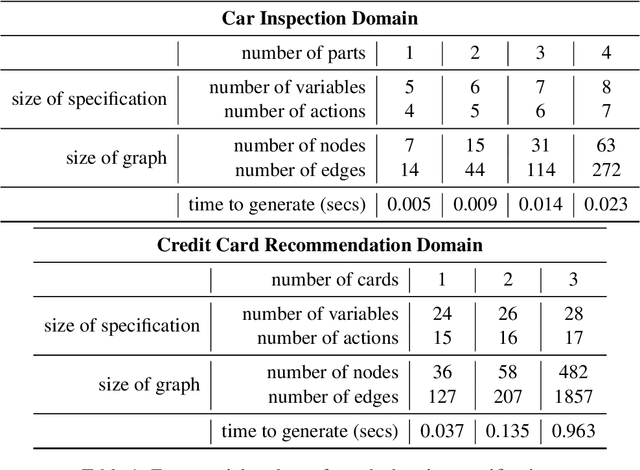
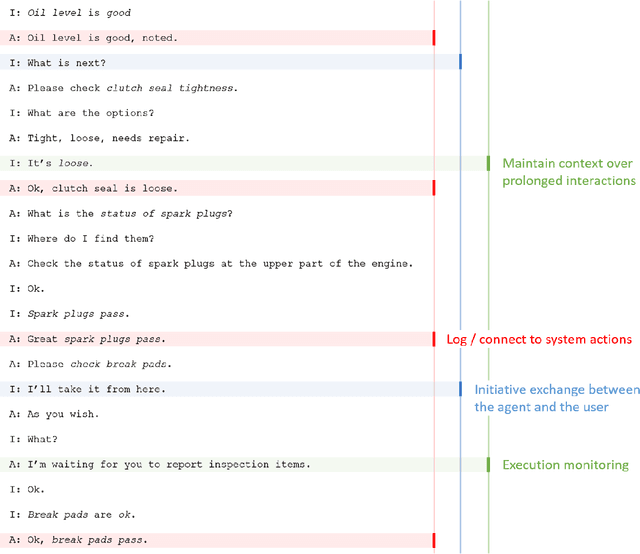
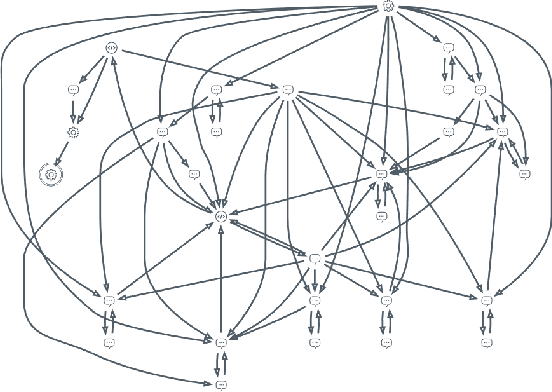
Generating complex multi-turn goal-oriented dialogue agents is a difficult problem that has seen a considerable focus from many leaders in the tech industry, including IBM, Google, Amazon, and Microsoft. This is in large part due to the rapidly growing market demand for dialogue agents capable of goal-oriented behaviour. Due to the business process nature of these conversations, end-to-end machine learning systems are generally not a viable option, as the generated dialogue agents must be deployable and verifiable on behalf of the businesses authoring them. In this work, we propose a paradigm shift in the creation of goal-oriented complex dialogue systems that dramatically eliminates the need for a designer to manually specify a dialogue tree, which nearly all current systems have to resort to when the interaction pattern falls outside standard patterns such as slot filling. We propose a declarative representation of the dialogue agent to be processed by state-of-the-art planning technology. Our proposed approach covers all aspects of the process; from model solicitation to the execution of the generated plans/dialogue agents. Along the way, we introduce novel planning encodings for declarative dialogue synthesis, a variety of interfaces for working with the specification as a dialogue architect, and a robust executor for generalized contingent plans. We have created prototype implementations of all components, and in this paper, we further demonstrate the resulting system empirically.
Planning with Explanatory Actions: A Joint Approach to Plan Explicability and Explanations in Human-Aware Planning
Mar 21, 2019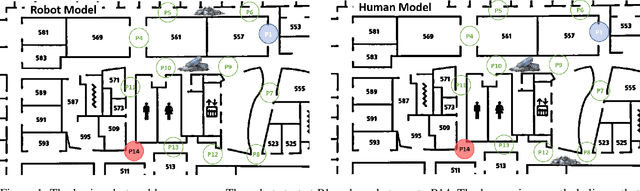
In this work, we formulate the process of generating explanations as model reconciliation for planning problems as one of planning with explanatory actions. We show that these problems could be better understood within the framework of epistemic planning and that, in fact, most earlier works on explanation as model reconciliation correspond to tractable subsets of epistemic planning problems. We empirically show how our approach is computationally more efficient than existing techniques for explanation generation and we end the paper with a discussion of how this formulation could be extended to generate novel explanatory behaviors.
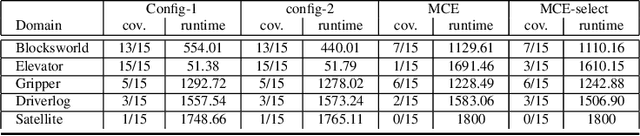
Generating Dialogue Agents via Automated Planning
Feb 02, 2019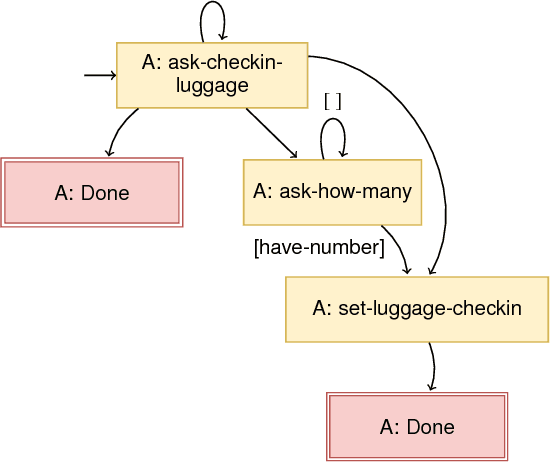
Dialogue systems have many applications such as customer support or question answering. Typically they have been limited to shallow single turn interactions. However more advanced applications such as career coaching or planning a trip require a much more complex multi-turn dialogue. Current limitations of conversational systems have made it difficult to support applications that require personalization, customization and context dependent interactions. We tackle this challenging problem by using domain-independent AI planning to automatically create dialogue plans, customized to guide a dialogue towards achieving a given goal. The input includes a library of atomic dialogue actions, an initial state of the dialogue, and a goal. Dialogue plans are plugged into a dialogue system capable to orchestrate their execution. Use cases demonstrate the viability of the approach. Our work on dialogue planning has been integrated into a product, and it is in the process of being deployed into another.
Finite LTL Synthesis is EXPTIME-complete
Nov 17, 2016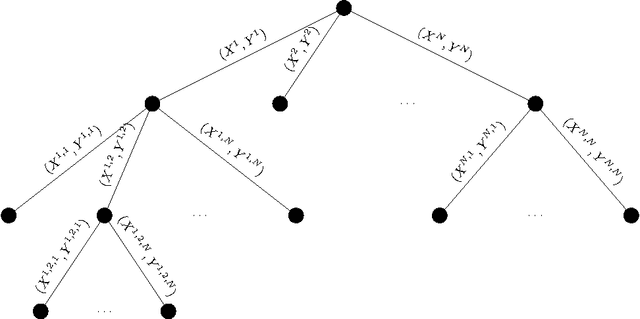
LTL synthesis -- the construction of a function to satisfy a logical specification formulated in Linear Temporal Logic -- is a 2EXPTIME-complete problem with relevant applications in controller synthesis and a myriad of artificial intelligence applications. In this research note we consider De Giacomo and Vardi's variant of the synthesis problem for LTL formulas interpreted over finite rather than infinite traces. Rather surprisingly, given the existing claims on complexity, we establish that LTL synthesis is EXPTIME-complete for the finite interpretation, and not 2EXPTIME-complete as previously reported. Our result coincides nicely with the planning perspective where non-deterministic planning with full observability is EXPTIME-complete and partial observability increases the complexity to 2EXPTIME-complete; a recent related result for LTL synthesis shows that in the finite case with partial observability, the problem is 2EXPTIME-complete.
Social planning for social HRI
Feb 21, 2016Making a computational agent 'social' has implications for how it perceives itself and the environment in which it is situated, including the ability to recognise the behaviours of others. We point to recent work on social planning, i.e. planning in settings where the social context is relevant in the assessment of the beliefs and capabilities of others, and in making appropriate choices of what to do next.
Projected Model Counting
Jul 28, 2015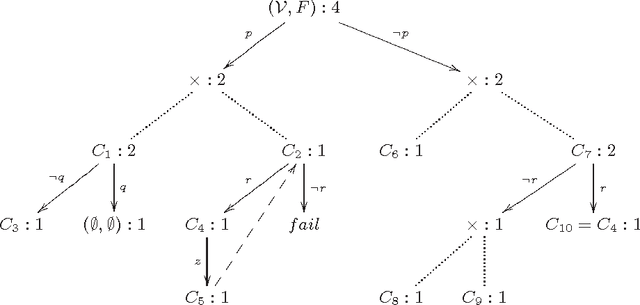


Model counting is the task of computing the number of assignments to variables V that satisfy a given propositional theory F. Model counting is an essential tool in probabilistic reasoning. In this paper, we introduce the problem of model counting projected on a subset P of original variables that we call 'priority' variables. The task is to compute the number of assignments to P such that there exists an extension to 'non-priority' variables V\P that satisfies F. Projected model counting arises when some parts of the model are irrelevant to the counts, in particular when we require additional variables to model the problem we are counting in SAT. We discuss three different approaches to projected model counting (two of which are novel), and compare their performance on different benchmark problems. To appear in 18th International Conference on Theory and Applications of Satisfiability Testing, September 24-27, 2015, Austin, Texas, USA
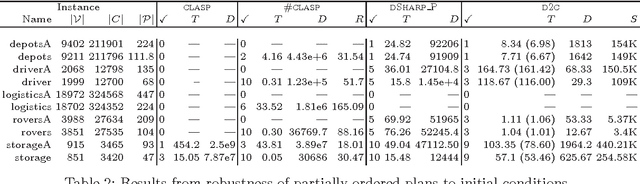
Stable Model Counting and Its Application in Probabilistic Logic Programming
Nov 20, 2014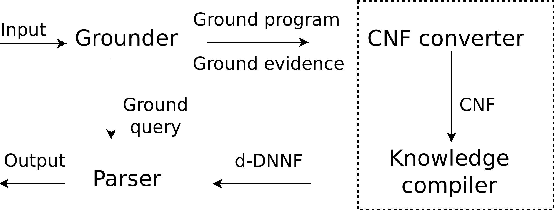
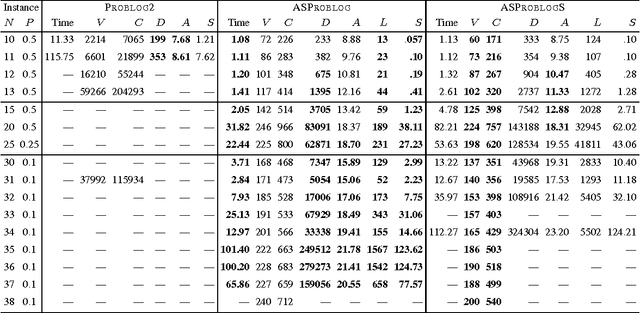
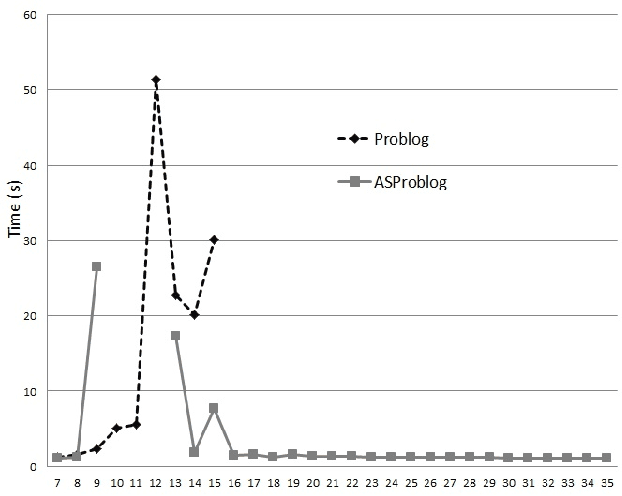
Model counting is the problem of computing the number of models that satisfy a given propositional theory. It has recently been applied to solving inference tasks in probabilistic logic programming, where the goal is to compute the probability of given queries being true provided a set of mutually independent random variables, a model (a logic program) and some evidence. The core of solving this inference task involves translating the logic program to a propositional theory and using a model counter. In this paper, we show that for some problems that involve inductive definitions like reachability in a graph, the translation of logic programs to SAT can be expensive for the purpose of solving inference tasks. For such problems, direct implementation of stable model semantics allows for more efficient solving. We present two implementation techniques, based on unfounded set detection, that extend a propositional model counter to a stable model counter. Our experiments show that for particular problems, our approach can outperform a state-of-the-art probabilistic logic programming solver by several orders of magnitude in terms of running time and space requirements, and can solve instances of significantly larger sizes on which the current solver runs out of time or memory.