 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Dialogue Agents via Automated Planning
Feb 02, 2019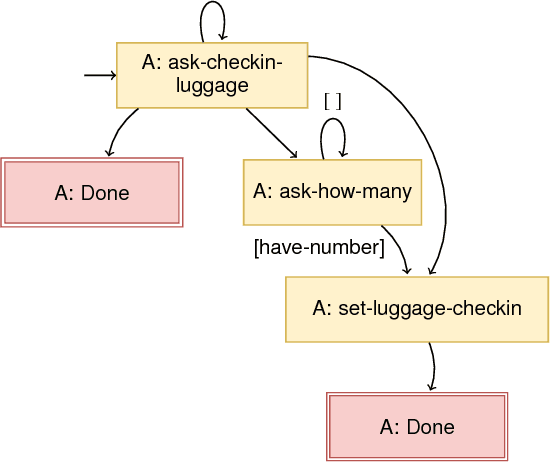
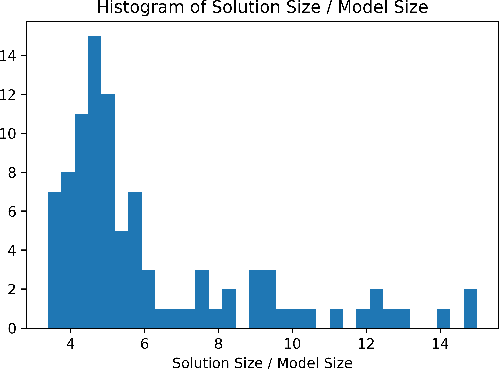
Dialogue systems have many applications such as customer support or question answering. Typically they have been limited to shallow single turn interactions. However more advanced applications such as career coaching or planning a trip require a much more complex multi-turn dialogue. Current limitations of conversational systems have made it difficult to support applications that require personalization, customization and context dependent interactions. We tackle this challenging problem by using domain-independent AI planning to automatically create dialogue plans, customized to guide a dialogue towards achieving a given goal. The input includes a library of atomic dialogue actions, an initial state of the dialogue, and a goal. Dialogue plans are plugged into a dialogue system capable to orchestrate their execution. Use cases demonstrate the viability of the approach. Our work on dialogue planning has been integrated into a product, and it is in the process of being deployed into another.
A Survey of Parallel A*
Aug 16, 2017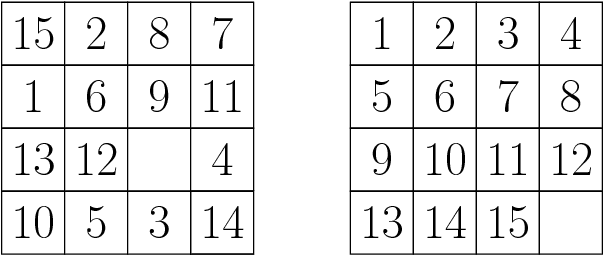
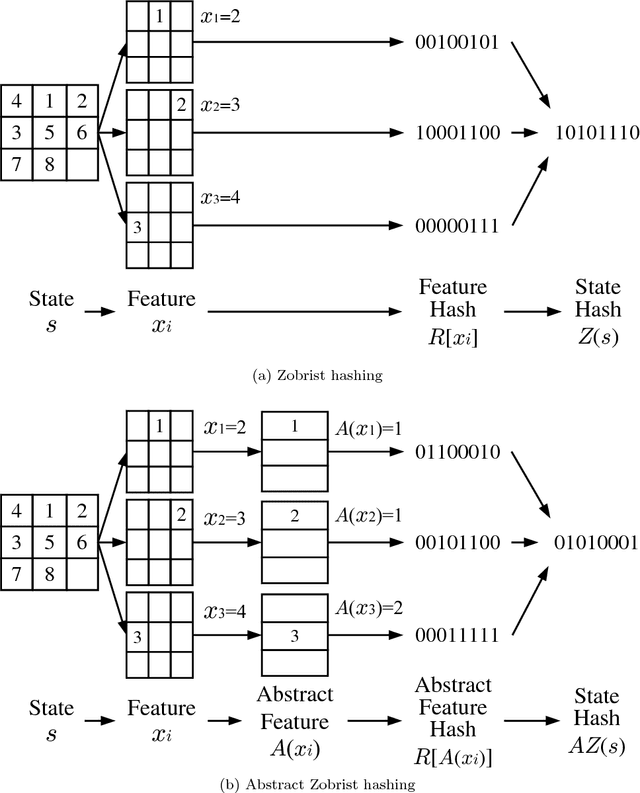
A* is a best-first search algorithm for finding optimal-cost paths in graphs. A* benefits significantly from parallelism because in many applications, A* is limited by memory usage, so distributed memory implementations of A* that use all of the aggregate memory on the cluster enable problems that can not be solved by serial, single-machine implementations to be solved. We survey approaches to parallel A*, focusing on decentralized approaches to A* which partition the state space among processors. We also survey approaches to parallel, limited-memory variants of A* such as parallel IDA*.
MAPP: a Scalable Multi-Agent Path Planning Algorithm with Tractability and Completeness Guarantees
Jan 16, 2014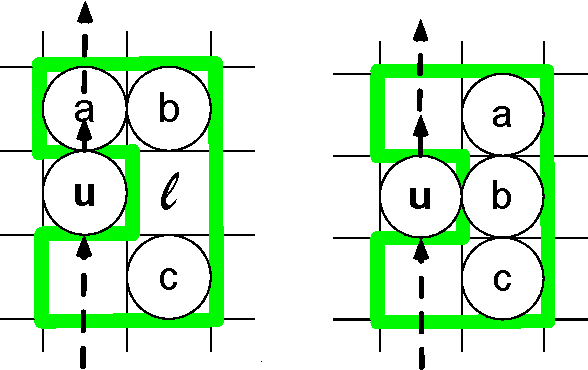
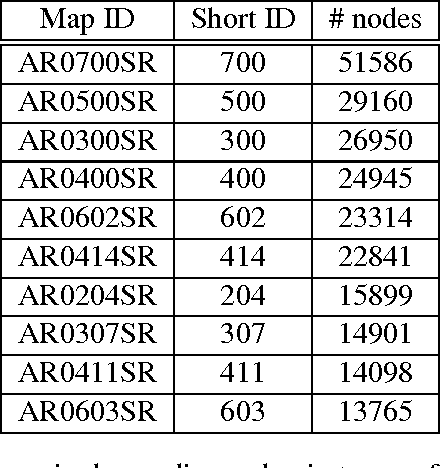
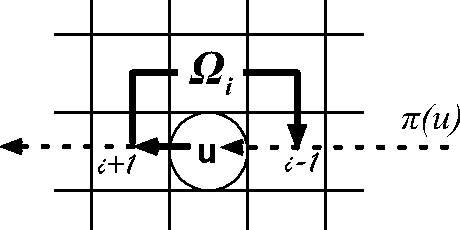
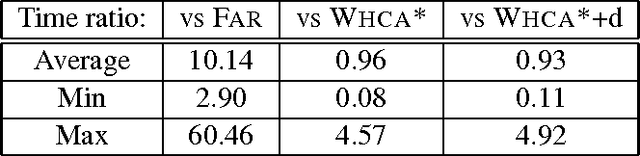
Multi-agent path planning is a challenging problem with numerous real-life applications. Running a centralized search such as A* in the combined state space of all units is complete and cost-optimal, but scales poorly, as the state space size is exponential in the number of mobile units. Traditional decentralized approaches, such as FAR and WHCA*, are faster and more scalable, being based on problem decomposition. However, such methods are incomplete and provide no guarantees with respect to the running time or the solution quality. They are not necessarily able to tell in a reasonable time whether they would succeed in finding a solution to a given instance. We introduce MAPP, a tractable algorithm for multi-agent path planning on undirected graphs. We present a basic version and several extensions. They have low-polynomial worst-case upper bounds for the running time, the memory requirements, and the length of solutions. Even though all algorithmic versions are incomplete in the general case, each provides formal guarantees on problems it can solve. For each version, we discuss the algorithms completeness with respect to clearly defined subclasses of instances. Experiments were run on realistic game grid maps. MAPP solved 99.86% of all mobile units, which is 18--22% better than the percentage of FAR and WHCA*. MAPP marked 98.82% of all units as provably solvable during the first stage of plan computation. Parts of MAPPs computation can be re-used across instances on the same map. Speed-wise, MAPP is competitive or significantly faster than WHCA*, depending on whether MAPP performs all computations from scratch. When data that MAPP can re-use are preprocessed offline and readily available, MAPP is slower than the very fast FAR algorithm by a factor of 2.18 on average. MAPPs solutions are on average 20% longer than FARs solutions and 7--31% longer than WHCA*s solutions.
Evaluation of a Simple, Scalable, Parallel Best-First Search Strategy
Oct 25, 2012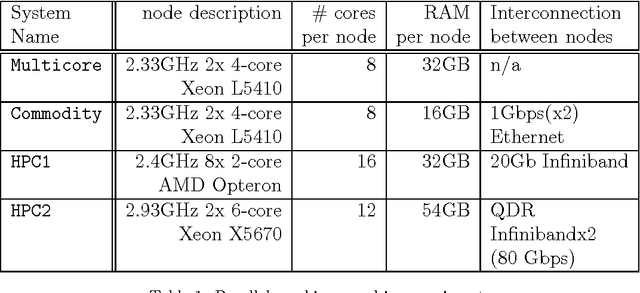
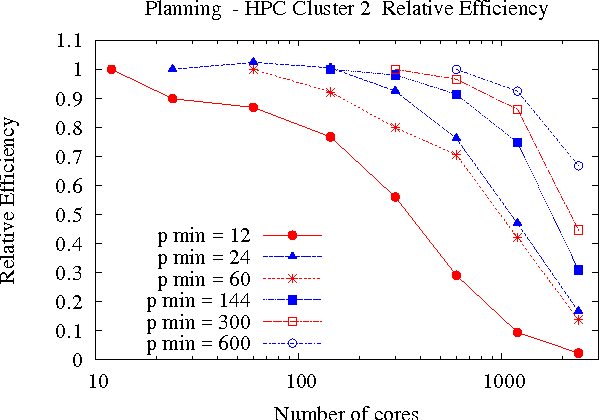
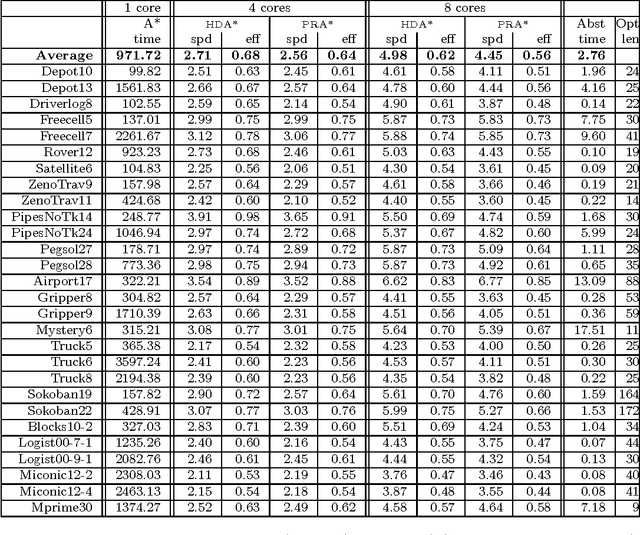
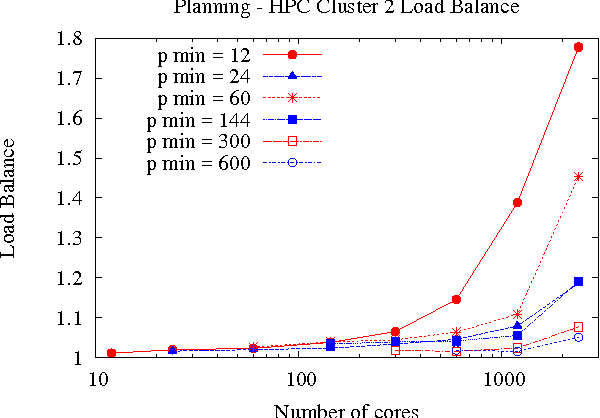
Large-scale, parallel clusters composed of commodity processors are increasingly available, enabling the use of vast processing capabilities and distributed RAM to solve hard search problems. We investigate Hash-Distributed A* (HDA*), a simple approach to parallel best-first search that asynchronously distributes and schedules work among processors based on a hash function of the search state. We use this approach to parallelize the A* algorithm in an optimal sequential version of the Fast Downward planner, as well as a 24-puzzle solver. The scaling behavior of HDA* is evaluated experimentally on a shared memory, multicore machine with 8 cores, a cluster of commodity machines using up to 64 cores, and large-scale high-performance clusters, using up to 2400 processors. We show that this approach scales well, allowing the effective utilization of large amounts of distributed memory to optimally solve problems which require terabytes of RAM. We also compare HDA* to Transposition-table Driven Scheduling (TDS), a hash-based parallelization of IDA*, and show that, in planning, HDA* significantly outperforms TDS. A simple hybrid which combines HDA* and TDS to exploit strengths of both algorithms is proposed and evaluated.
* in press, to appear in Artificial Intelligence
Symmetry-Based Search Space Reduction For Grid Maps
Jun 21, 2011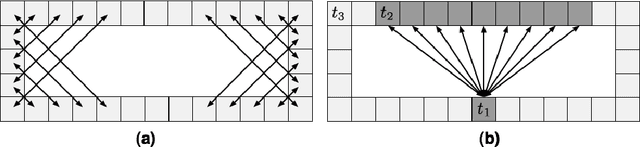

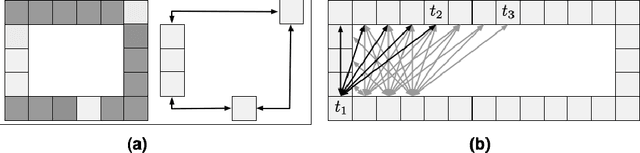
In this paper we explore a symmetry-based search space reduction technique which can speed up optimal pathfinding on undirected uniform-cost grid maps by up to 38 times. Our technique decomposes grid maps into a set of empty rectangles, removing from each rectangle all interior nodes and possibly some from along the perimeter. We then add a series of macro-edges between selected pairs of remaining perimeter nodes to facilitate provably optimal traversal through each rectangle. We also develop a novel online pruning technique to further speed up search. Our algorithm is fast, memory efficient and retains the same optimality and completeness guarantees as searching on an unmodified grid map.