 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Augmented Semantic Steering of Text Embedding Projection Spaces
May 03, 2026Low-dimensional projections of text embeddings support visual analysis of document collections, but their spatial organization may not reflect the relationships an analyst intends to examine. Existing semantic interaction approaches encode semantic intent indirectly through geometric constraints or model updates, limiting interpretability and flexibility. We introduce LLM-augmented semantic steering, which enables analysts to express semantic intent by grouping a small set of example documents within the projection. A large language model externalizes this intent as natural-language representations and selectively extends it to related documents; the resulting semantic information is then incorporated into document representations via text augmentation or embedding-level blending, without retraining the underlying models. A case study illustrates how the same corpus can be reorganized from different semantic perspectives, while simulation-based evaluation shows that semantic steering improves global and local alignment with target semantic structures using only minimal interaction. Embedding-level blending further enables continuous and controllable steering of projection layouts. These results position projection spaces as intent-dependent semantic workspaces that can be reshaped through explicit, interpretable, language-mediated interaction.
Semantic Prompting: Agentic Incremental Narrative Refinement through Spatial Semantic Interaction
Apr 21, 2026Interactive spatial layouts empower users to synthesize information and organize findings for sensemaking. While Large Language Models (LLMs) can automate narrative generation from spatial layouts, current collage-based and re-generation methods struggle to support the incremental spatial refinements inherent to the sensemaking process. We identify three critical gaps in existing spatial-textual generation: interaction-revision misalignment, human-LLM intent misalignment, and lack of granular customization. To address these, we introduce Semantic Prompting, a framework for spatial refinement that perceives semantic interactions, reasons about refinement intent, and performs targeted positional revisions. We implemented S-PRISM to realize this framework. The empirical evaluation demonstrated that S-PRISM effectively enhanced the precision of interaction-revision refinement. A user study ($N=14$) highlighted how participants leveraged S-PRISM for incremental formalization through interactive steering. Results showed that users valued its efficient, adaptable, and trustworthy support, which effectively strengthens human-LLM intent alignment.
Semantic Interaction for Narrative Map Sensemaking: An Insight-based Evaluation
Mar 31, 2026Semantic interaction (SI) enables analysts to incorporate their cognitive processes into AI models through direct manipulation of visualizations. While SI frameworks for narrative extraction have been proposed, empirical evaluations of their effectiveness remain limited. This paper presents a user study that evaluates SI for narrative map sensemaking, involving 33 participants under three conditions: a timeline baseline, a basic narrative map, and an interactive narrative map with SI capabilities. The results show that the map-based prototypes yielded more insights than the timeline baseline, with the SI-enabled condition reaching statistical significance and the basic map condition trending in the same direction. The SI-enabled condition showed the highest mean performance; differences between the map conditions were not statistically significant but showed large effect sizes (d > 0.8), suggesting that the study was underpowered to detect them. Qualitative analysis identified two distinct SI approaches-corrective and additive-that enable analysts to impose quality judgments and organizational structure on extracted narratives. We also find that SI users achieved comparable exploration breadth with less parameter manipulation, suggesting that SI serves as an alternative pathway for model refinement. This work provides empirical evidence that map-based representations outperform timelines for narrative sensemaking, along with qualitative insights into how analysts use SI for narrative refinement.
Explainable AI Components for Narrative Map Extraction
Mar 19, 2025As narrative extraction systems grow in complexity, establishing user trust through interpretable and explainable outputs becomes increasingly critical. This paper presents an evaluation of an Explainable Artificial Intelligence (XAI) system for narrative map extraction that provides meaningful explanations across multiple levels of abstraction. Our system integrates explanations based on topical clusters for low-level document relationships, connection explanations for event relationships, and high-level structure explanations for overall narrative patterns. In particular, we evaluate the XAI system through a user study involving 10 participants that examined narratives from the 2021 Cuban protests. The analysis of results demonstrates that participants using the explanations made the users trust in the system's decisions, with connection explanations and important event detection proving particularly effective at building user confidence. Survey responses indicate that the multi-level explanation approach helped users develop appropriate trust in the system's narrative extraction capabilities. This work advances the state-of-the-art in explainable narrative extraction while providing practical insights for developing reliable narrative extraction systems that support effective human-AI collaboration.
Narrative Trails: A Method for Coherent Storyline Extraction via Maximum Capacity Path Optimization
Mar 19, 2025



Traditional information retrieval is primarily concerned with finding relevant information from large datasets without imposing a structure within the retrieved pieces of data. However, structuring information in the form of narratives--ordered sets of documents that form coherent storylines--allows us to identify, interpret, and share insights about the connections and relationships between the ideas presented in the data. Despite their significance, current approaches for algorithmically extracting storylines from data are scarce, with existing methods primarily relying on intricate word-based heuristics and auxiliary document structures. Moreover, many of these methods are difficult to scale to large datasets and general contexts, as they are designed to extract storylines for narrow tasks. In this paper, we propose Narrative Trails, an efficient, general-purpose method for extracting coherent storylines in large text corpora. Specifically, our method uses the semantic-level information embedded in the latent space of deep learning models to build a sparse coherence graph and extract narratives that maximize the minimum coherence of the storylines. By quantitatively evaluating our proposed methods on two distinct narrative extraction tasks, we show the generalizability and scalability of Narrative Trails in multiple contexts while also simplifying the extraction pipeline.
Visualizing Temporal Topic Embeddings with a Compass
Sep 18, 2024



Dynamic topic modeling is useful at discovering the development and change in latent topics over time. However, present methodology relies on algorithms that separate document and word representations. This prevents the creation of a meaningful embedding space where changes in word usage and documents can be directly analyzed in a temporal context. This paper proposes an expansion of the compass-aligned temporal Word2Vec methodology into dynamic topic modeling. Such a method allows for the direct comparison of word and document embeddings across time in dynamic topics. This enables the creation of visualizations that incorporate temporal word embeddings within the context of documents into topic visualizations. In experiments against the current state-of-the-art, our proposed method demonstrates overall competitive performance in topic relevancy and diversity across temporal datasets of varying size. Simultaneously, it provides insightful visualizations focused on temporal word embeddings while maintaining the insights provided by global topic evolution, advancing our understanding of how topics evolve over time.
DeepSI: Interactive Deep Learning for Semantic Interaction
May 26, 2023In this paper, we design novel interactive deep learning methods to improve semantic interactions in visual analytics applications. The ability of semantic interaction to infer analysts' precise intents during sensemaking is dependent on the quality of the underlying data representation. We propose the $\text{DeepSI}_{\text{finetune}}$ framework that integrates deep learning into the human-in-the-loop interactive sensemaking pipeline, with two important properties. First, deep learning extracts meaningful representations from raw data, which improves semantic interaction inference. Second, semantic interactions are exploited to fine-tune the deep learning representations, which then further improves semantic interaction inference. This feedback loop between human interaction and deep learning enables efficient learning of user- and task-specific representations. To evaluate the advantage of embedding the deep learning within the semantic interaction loop, we compare $\text{DeepSI}_{\text{finetune}}$ against a state-of-the-art but more basic use of deep learning as only a feature extractor pre-processed outside of the interactive loop. Results of two complementary studies, a human-centered qualitative case study and an algorithm-centered simulation-based quantitative experiment, show that $\text{DeepSI}_{\text{finetune}}$ more accurately captures users' complex mental models with fewer interactions.
A Survey on Event-based News Narrative Extraction
Feb 16, 2023Narratives are fundamental to our understanding of the world, providing us with a natural structure for knowledge representation over time. Computational narrative extraction is a subfield of artificial intelligence that makes heavy use of information retrieval and natural language processing techniques. Despite the importance of computational narrative extraction, relatively little scholarly work exists on synthesizing previous research and strategizing future research in the area. In particular, this article focuses on extracting news narratives from an event-centric perspective. Extracting narratives from news data has multiple applications in understanding the evolving information landscape. This survey presents an extensive study of research in the area of event-based news narrative extraction. In particular, we screened over 900 articles that yielded 54 relevant articles. These articles are synthesized and organized by representation model, extraction criteria, and evaluation approaches. Based on the reviewed studies, we identify recent trends, open challenges, and potential research lines.
Mixed Multi-Model Semantic Interaction for Graph-based Narrative Visualizations
Feb 13, 2023



Narrative sensemaking is an essential part of understanding sequential data. Narrative maps are a visual representation model that can assist analysts to understand narratives. In this work, we present a semantic interaction (SI) framework for narrative maps that can support analysts through their sensemaking process. In contrast to traditional SI systems which rely on dimensionality reduction and work on a projection space, our approach has an additional abstraction layer -- the structure space -- that builds upon the projection space and encodes the narrative in a discrete structure. This extra layer introduces additional challenges that must be addressed when integrating SI with the narrative extraction pipeline. We address these challenges by presenting the general concept of Mixed Multi-Model Semantic Interaction (3MSI) -- an SI pipeline, where the highest-level model corresponds to an abstract discrete structure and the lower-level models are continuous. To evaluate the performance of our 3MSI models for narrative maps, we present a quantitative simulation-based evaluation and a qualitative evaluation with case studies and expert feedback. We find that our SI system can model the analysts' intent and support incremental formalism for narrative maps.
NetReAct: Interactive Learning for Network Summarization
Dec 22, 2020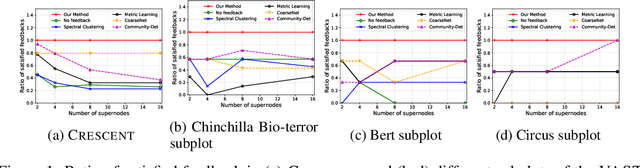
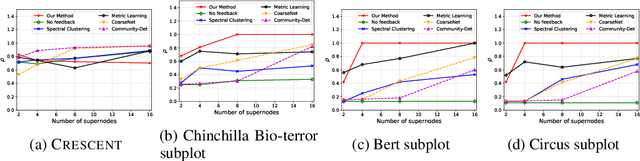
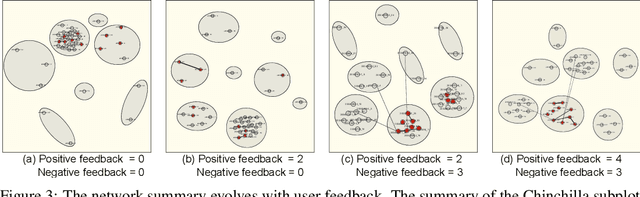
Generating useful network summaries is a challenging and important problem with several applications like sensemaking, visualization, and compression. However, most of the current work in this space do not take human feedback into account while generating summaries. Consider an intelligence analysis scenario, where the analyst is exploring a similarity network between documents. The analyst can express her agreement/disagreement with the visualization of the network summary via iterative feedback, e.g. closing or moving documents ("nodes") together. How can we use this feedback to improve the network summary quality? In this paper, we present NetReAct, a novel interactive network summarization algorithm which supports the visualization of networks induced by text corpora to perform sensemaking. NetReAct incorporates human feedback with reinforcement learning to summarize and visualize document networks. Using scenarios from two datasets, we show how NetReAct is successful in generating high-quality summaries and visualizations that reveal hidden patterns better than other non-trivial baselines.