 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Restricted Streaming Recurrent Neural Network Transducer
Nov 05, 2020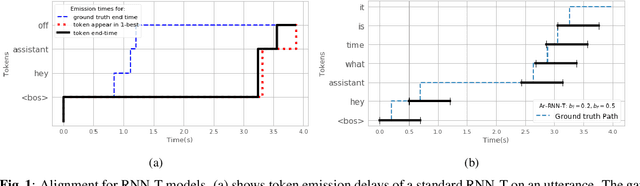
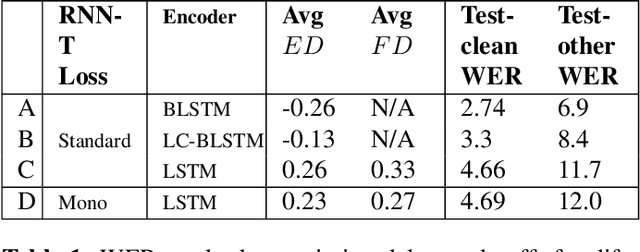
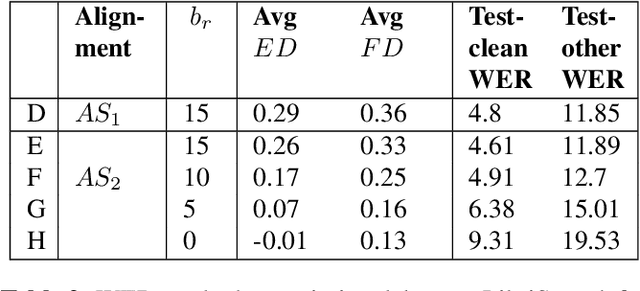
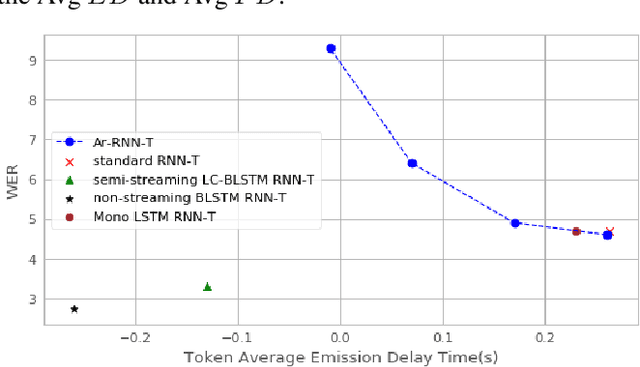
There is a growing interest in the speech community in developing Recurrent Neural Network Transducer (RNN-T) models for automatic speech recognition (ASR) applications. RNN-T is trained with a loss function that does not enforce temporal alignment of the training transcripts and audio. As a result, RNN-T models built with uni-directional long short term memory (LSTM) encoders tend to wait for longer spans of input audio, before streaming already decoded ASR tokens. In this work, we propose a modification to the RNN-T loss function and develop Alignment Restricted RNN-T (Ar-RNN-T) models, which utilize audio-text alignment information to guide the loss computation. We compare the proposed method with existing works, such as monotonic RNN-T, on LibriSpeech and in-house datasets. We show that the Ar-RNN-T loss provides a refined control to navigate the trade-offs between the token emission delays and the Word Error Rate (WER). The Ar-RNN-T models also improve downstream applications such as the ASR End-pointing by guaranteeing token emissions within any given range of latency. Moreover, the Ar-RNN-T loss allows for bigger batch sizes and 4 times higher throughput for our LSTM model architecture, enabling faster training and convergence on GPUs.
Streaming Attention-Based Models with Augmented Memory for End-to-End Speech Recognition
Nov 03, 2020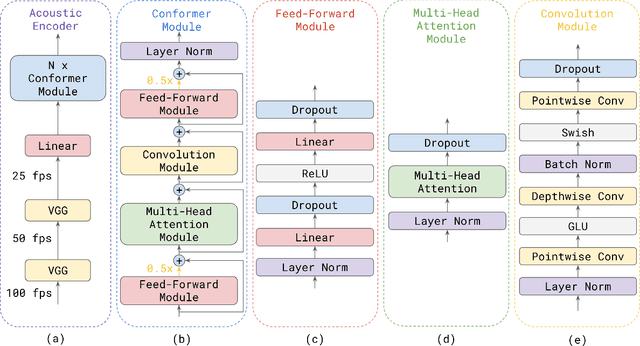
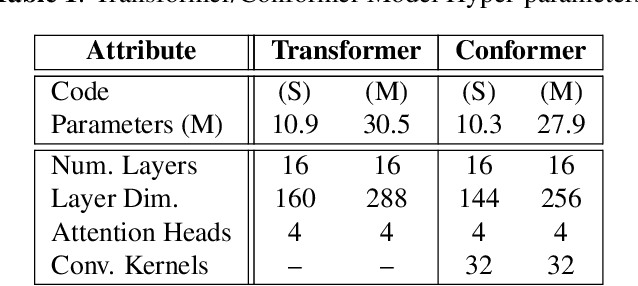
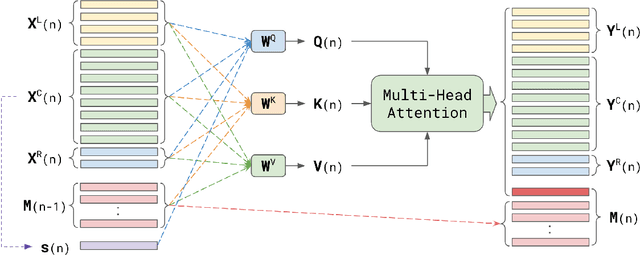
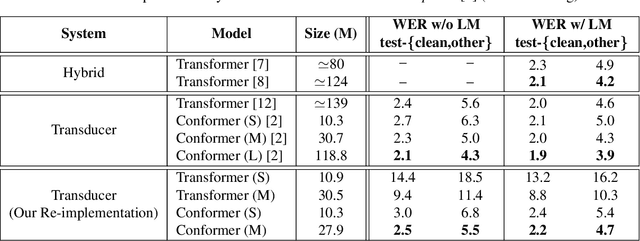
Attention-based models have been gaining popularity recently for their strong performance demonstrated in fields such as machine translation and automatic speech recognition. One major challenge of attention-based models is the need of access to the full sequence and the quadratically growing computational cost concerning the sequence length. These characteristics pose challenges, especially for low-latency scenarios, where the system is often required to be streaming. In this paper, we build a compact and streaming speech recognition system on top of the end-to-end neural transducer architecture with attention-based modules augmented with convolution. The proposed system equips the end-to-end models with the streaming capability and reduces the large footprint from the streaming attention-based model using augmented memory. On the LibriSpeech dataset, our proposed system achieves word error rates 2.7% on test-clean and 5.8% on test-other, to our best knowledge the lowest among streaming approaches reported so far.
Transformer in action: a comparative study of transformer-based acoustic models for large scale speech recognition applications
Oct 29, 2020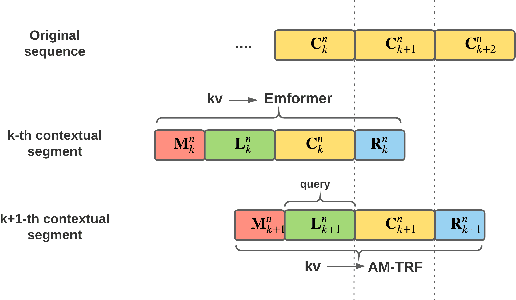
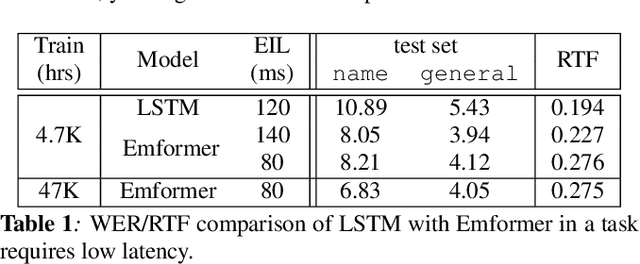
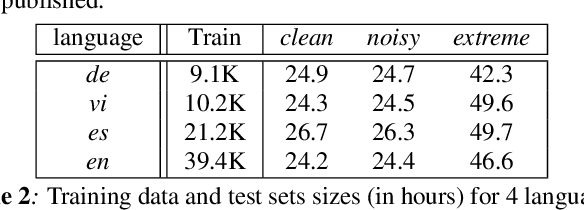
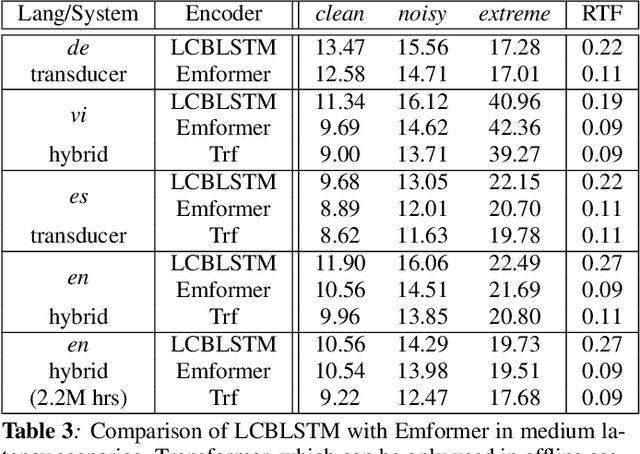
In this paper, we summarize the application of transformer and its streamable variant, Emformer based acoustic model for large scale speech recognition applications. We compare the transformer based acoustic models with their LSTM counterparts on industrial scale tasks. Specifically, we compare Emformer with latency-controlled BLSTM (LCBLSTM) on medium latency tasks and LSTM on low latency tasks. On a low latency voice assistant task, Emformer gets 24% to 26% relative word error rate reductions (WERRs). For medium latency scenarios, comparing with LCBLSTM with similar model size and latency, Emformer gets significant WERR across four languages in video captioning datasets with 2-3 times inference real-time factors reduction.
Emformer: Efficient Memory Transformer Based Acoustic Model For Low Latency Streaming Speech Recognition
Oct 29, 2020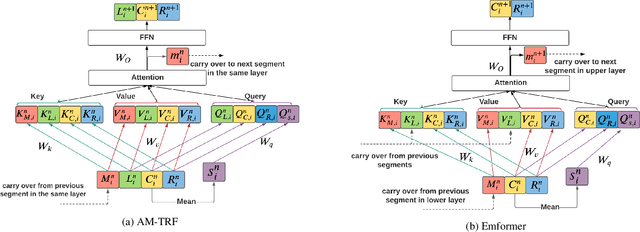
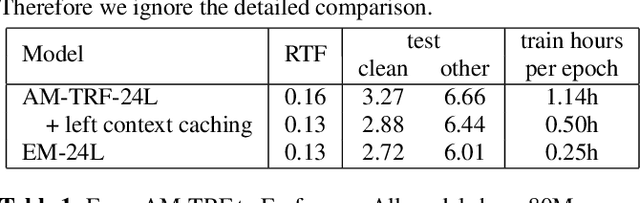
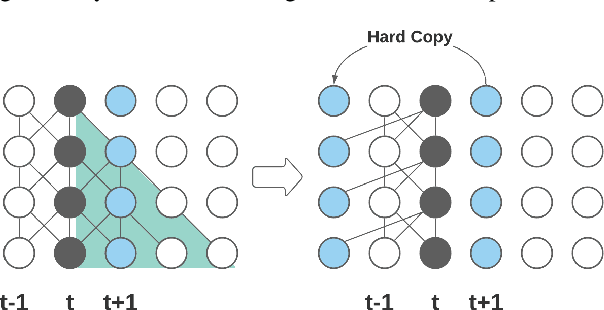
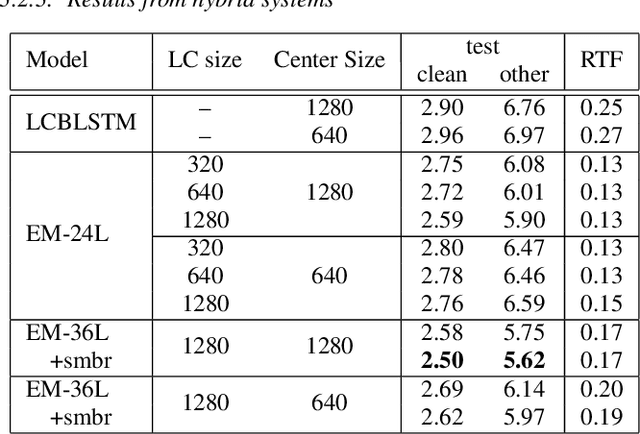
This paper proposes an efficient memory transformer Emformer for low latency streaming speech recognition. In Emformer, the long-range history context is distilled into an augmented memory bank to reduce self-attention's computation complexity. A cache mechanism saves the computation for the key and value in self-attention for the left context. Emformer applies a parallelized block processing in training to support low latency models. We carry out experiments on benchmark LibriSpeech data. Under average latency of 960 ms, Emformer gets WER $2.50\%$ on test-clean and $5.62\%$ on test-other. Comparing with a strong baseline augmented memory transformer (AM-TRF), Emformer gets $4.6$ folds training speedup and $18\%$ relative real-time factor (RTF) reduction in decoding with relative WER reduction $17\%$ on test-clean and $9\%$ on test-other. For a low latency scenario with an average latency of 80 ms, Emformer achieves WER $3.01\%$ on test-clean and $7.09\%$ on test-other. Comparing with the LSTM baseline with the same latency and model size, Emformer gets relative WER reduction $9\%$ and $16\%$ on test-clean and test-other, respectively.
Weak-Attention Suppression For Transformer Based Speech Recognition
May 18, 2020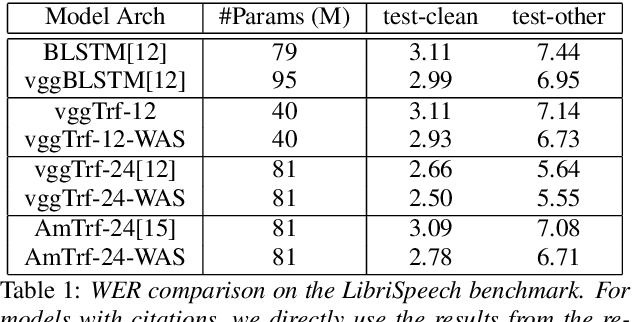
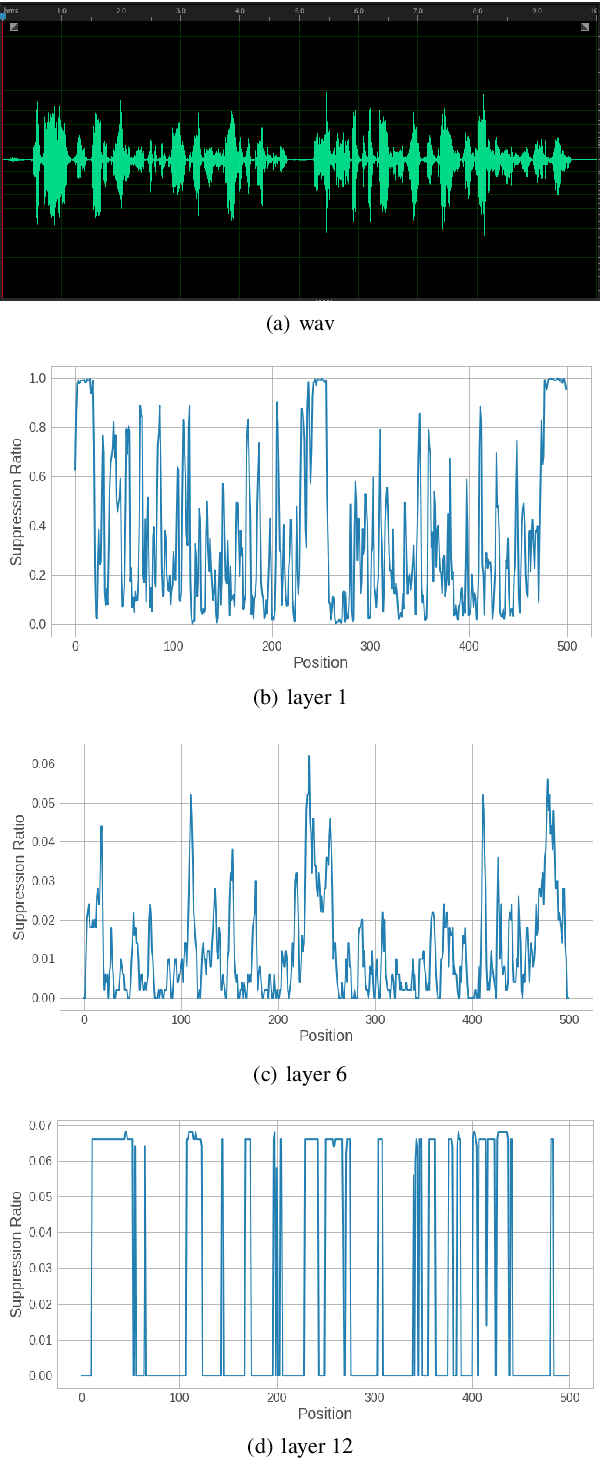
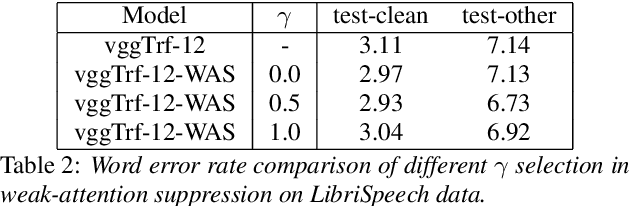
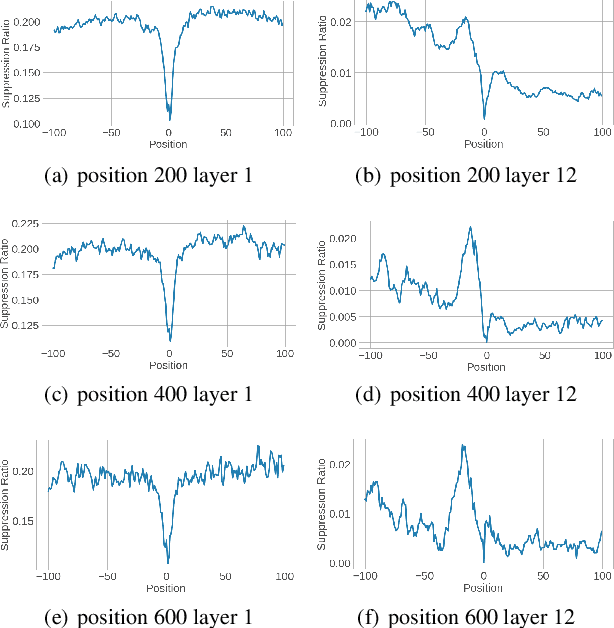
Transformers, originally proposed for natural language processing (NLP) tasks, have recently achieved great success in automatic speech recognition (ASR). However, adjacent acoustic units (i.e., frames) are highly correlated, and long-distance dependencies between them are weak, unlike text units. It suggests that ASR will likely benefit from sparse and localized attention. In this paper, we propose Weak-Attention Suppression (WAS), a method that dynamically induces sparsity in attention probabilities. We demonstrate that WAS leads to consistent Word Error Rate (WER) improvement over strong transformer baselines. On the widely used LibriSpeech benchmark, our proposed method reduced WER by 10%$ on test-clean and 5% on test-other for streamable transformers, resulting in a new state-of-the-art among streaming models. Further analysis shows that WAS learns to suppress attention of non-critical and redundant continuous acoustic frames, and is more likely to suppress past frames rather than future ones. It indicates the importance of lookahead in attention-based ASR models.
Streaming Transformer-based Acoustic Models Using Self-attention with Augmented Memory
May 16, 2020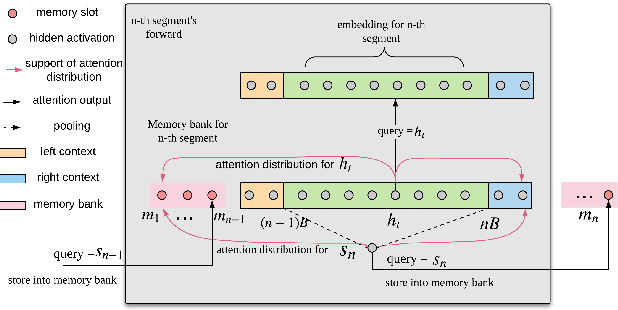
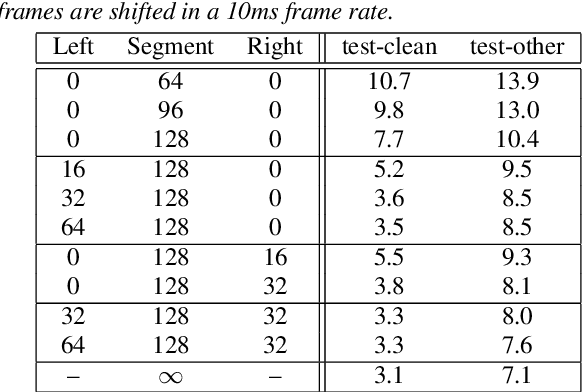
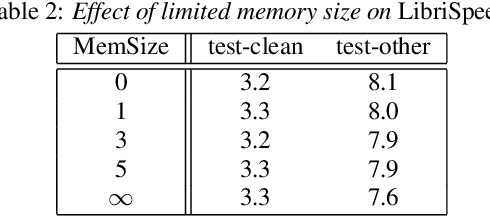
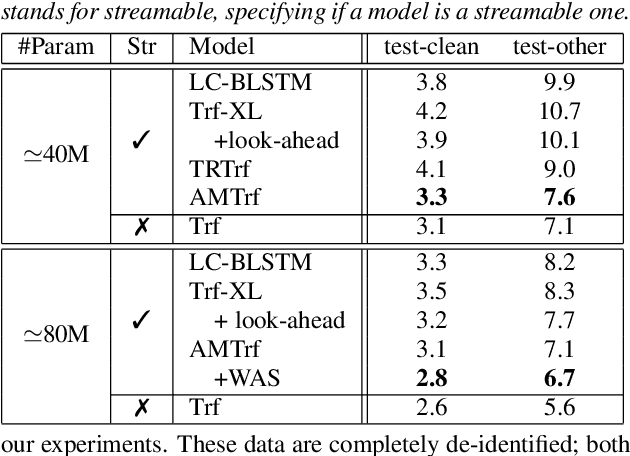
Transformer-based acoustic modeling has achieved great suc-cess for both hybrid and sequence-to-sequence speech recogni-tion. However, it requires access to the full sequence, and thecomputational cost grows quadratically with respect to the in-put sequence length. These factors limit its adoption for stream-ing applications. In this work, we proposed a novel augmentedmemory self-attention, which attends on a short segment of theinput sequence and a bank of memories. The memory bankstores the embedding information for all the processed seg-ments. On the librispeech benchmark, our proposed methodoutperforms all the existing streamable transformer methods bya large margin and achieved over 15% relative error reduction,compared with the widely used LC-BLSTM baseline. Our find-ings are also confirmed on some large internal datasets.
AIPNet: Generative Adversarial Pre-training of Accent-invariant Networks for End-to-end Speech Recognition
Nov 27, 2019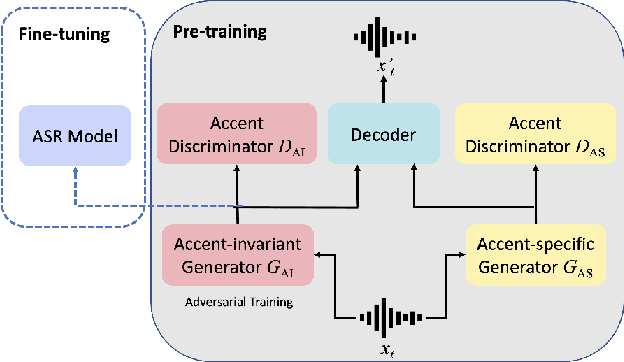
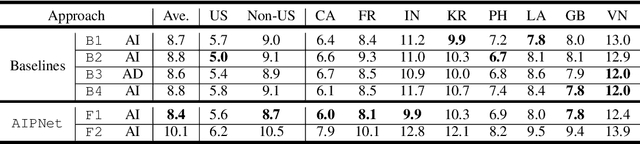
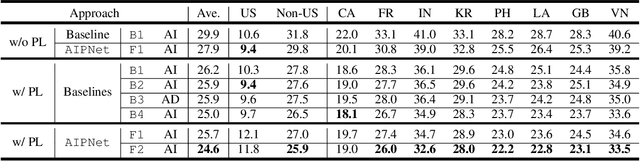
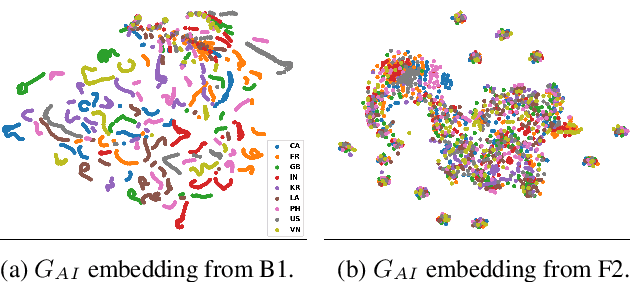
As one of the major sources in speech variability, accents have posed a grand challenge to the robustness of speech recognition systems. In this paper, our goal is to build a unified end-to-end speech recognition system that generalizes well across accents. For this purpose, we propose a novel pre-training framework AIPNet based on generative adversarial nets (GAN) for accent-invariant representation learning: Accent Invariant Pre-training Networks. We pre-train AIPNet to disentangle accent-invariant and accent-specific characteristics from acoustic features through adversarial training on accented data for which transcriptions are not necessarily available. We further fine-tune AIPNet by connecting the accent-invariant module with an attention-based encoder-decoder model for multi-accent speech recognition. In the experiments, our approach is compared against four baselines including both accent-dependent and accent-independent models. Experimental results on 9 English accents show that the proposed approach outperforms all the baselines by 2.3 \sim 4.5% relative reduction on average WER when transcriptions are available in all accents and by 1.6 \sim 6.1% relative reduction when transcriptions are only available in US accent.
RNN-T For Latency Controlled ASR With Improved Beam Search
Nov 05, 2019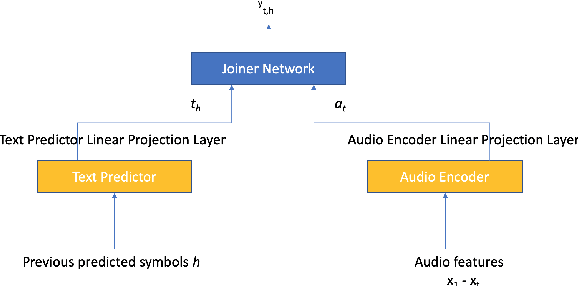

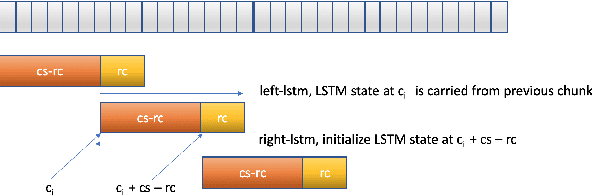
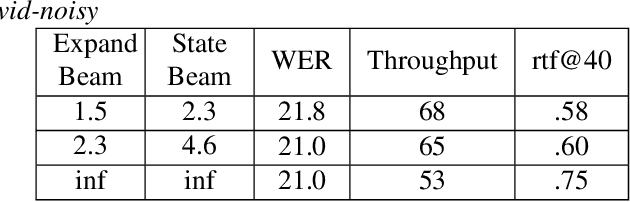
Neural transducer-based systems such as RNN Transducers (RNN-T) for automatic speech recognition (ASR) blend the individual components of a traditional hybrid ASR systems (acoustic model, language model, punctuation model, inverse text normalization) into one single model. This greatly simplifies training and inference and hence makes RNN-T a desirable choice for ASR systems. In this work, we investigate use of RNN-T in applications that require a tune-able latency budget during inference time. We also improved the decoding speed of the originally proposed RNN-T beam search algorithm. We evaluated our proposed system on English videos ASR dataset and show that neural RNN-T models can achieve comparable WER and better computational efficiency compared to a well tuned hybrid ASR baseline.
Transformer-Transducer: End-to-End Speech Recognition with Self-Attention
Oct 28, 2019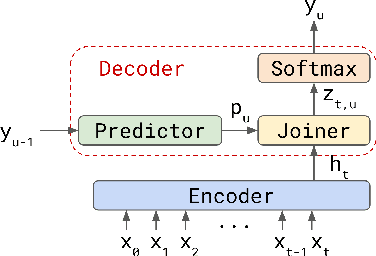
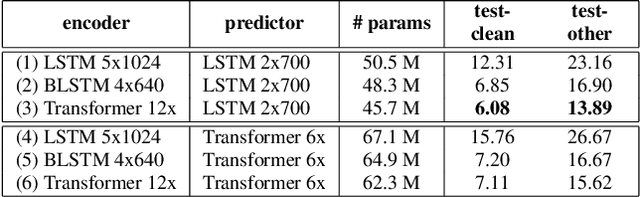
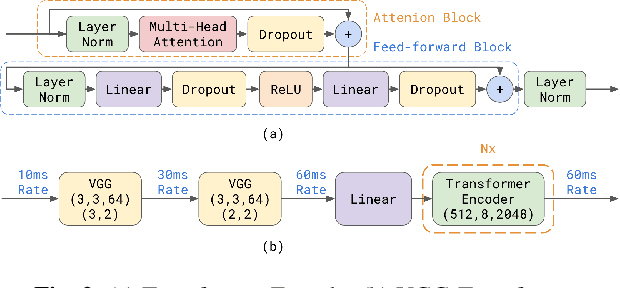
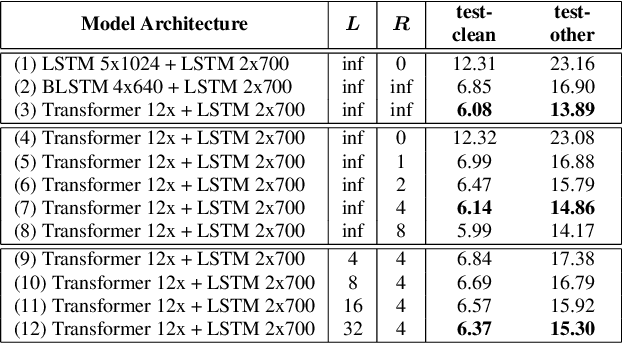
We explore options to use Transformer networks in neural transducer for end-to-end speech recognition. Transformer networks use self-attention for sequence modeling and comes with advantages in parallel computation and capturing contexts. We propose 1) using VGGNet with causal convolution to incorporate positional information and reduce frame rate for efficient inference 2) using truncated self-attention to enable streaming for Transformer and reduce computational complexity. All experiments are conducted on the public LibriSpeech corpus. The proposed Transformer-Transducer outperforms neural transducer with LSTM/BLSTM networks and achieved word error rates of 6.37 % on the test-clean set and 15.30 % on the test-other set, while remaining streamable, compact with 45.7M parameters for the entire system, and computationally efficient with complexity of O(T), where T is input sequence length.
Training Augmentation with Adversarial Examples for Robust Speech Recognition
Jun 17, 2018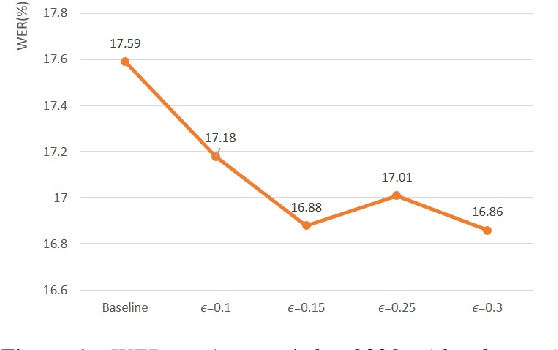
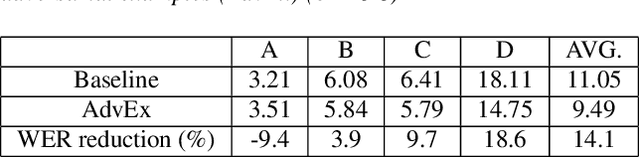
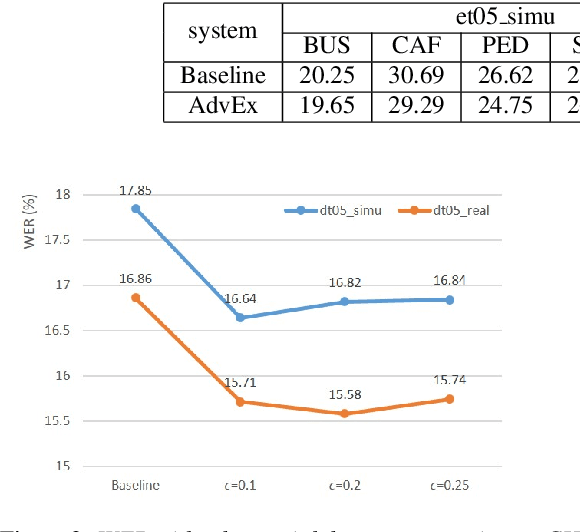
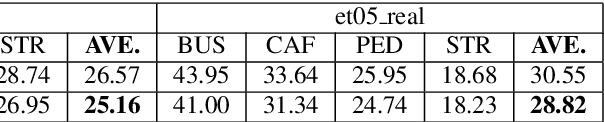
This paper explores the use of adversarial examples in training speech recognition systems to increase robustness of deep neural network acoustic models. During training, the fast gradient sign method is used to generate adversarial examples augmenting the original training data. Different from conventional data augmentation based on data transformations, the examples are dynamically generated based on current acoustic model parameters. We assess the impact of adversarial data augmentation in experiments on the Aurora-4 and CHiME-4 single-channel tasks, showing improved robustness against noise and channel variation. Further improvement is obtained when combining adversarial examples with teacher/student training, leading to a 23% relative word error rate reduction on Aurora-4.