 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Self-Play Algorithms for Competitive Reinforcement Learning
Feb 23, 2020
Self-play, where the algorithm learns by playing against itself without requiring any direct supervision, has become the new weapon in modern Reinforcement Learning (RL) for achieving superhuman performance in practice. However, the majority of exisiting theory in reinforcement learning only applies to the setting where the agent plays against a fixed environment. It remains largely open whether self-play algorithms can be provably effective, especially when it is necessary to manage the exploration/exploitation tradeoff. We study self-play in competitive reinforcement learning under the setting of Markov games, a generalization of Markov decision processes to the two-player case. We introduce a self-play algorithm---Value Iteration with Upper/Lower Confidence Bound (VI-ULCB), and show that it achieves regret $\mathcal{\tilde{O}}(\sqrt{T})$ after playing $T$ steps of the game. The regret is measured by the agent's performance against a \emph{fully adversarial} opponent who can exploit the agent's strategy at \emph{any} step. We also introduce an explore-then-exploit style algorithm, which achieves a slightly worse regret of $\mathcal{\tilde{O}}(T^{2/3})$, but is guaranteed to run in polynomial time even in the worst case. To the best of our knowledge, our work presents the first line of provably sample-efficient self-play algorithms for competitive reinforcement learning.
Reward-Free Exploration for Reinforcement Learning
Feb 07, 2020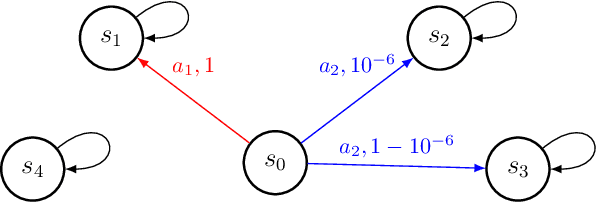
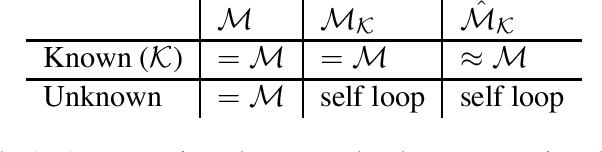
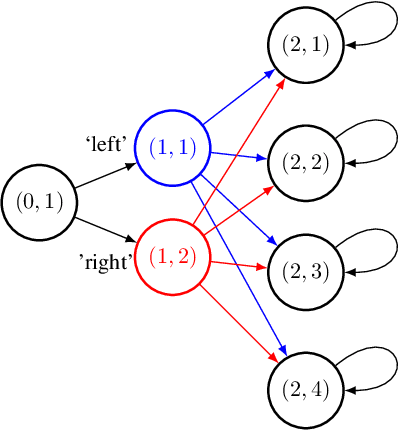
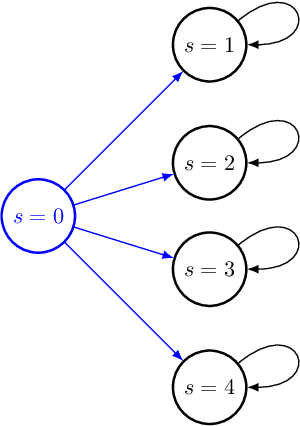
Exploration is widely regarded as one of the most challenging aspects of reinforcement learning (RL), with many naive approaches succumbing to exponential sample complexity. To isolate the challenges of exploration, we propose a new "reward-free RL" framework. In the exploration phase, the agent first collects trajectories from an MDP $\mathcal{M}$ without a pre-specified reward function. After exploration, it is tasked with computing near-optimal policies under for $\mathcal{M}$ for a collection of given reward functions. This framework is particularly suitable when there are many reward functions of interest, or when the reward function is shaped by an external agent to elicit desired behavior. We give an efficient algorithm that conducts $\tilde{\mathcal{O}}(S^2A\mathrm{poly}(H)/\epsilon^2)$ episodes of exploration and returns $\epsilon$-suboptimal policies for an arbitrary number of reward functions. We achieve this by finding exploratory policies that visit each "significant" state with probability proportional to its maximum visitation probability under any possible policy. Moreover, our planning procedure can be instantiated by any black-box approximate planner, such as value iteration or natural policy gradient. We also give a nearly-matching $\Omega(S^2AH^2/\epsilon^2)$ lower bound, demonstrating the near-optimality of our algorithm in this setting.
Near-Optimal Algorithms for Minimax Optimization
Feb 05, 2020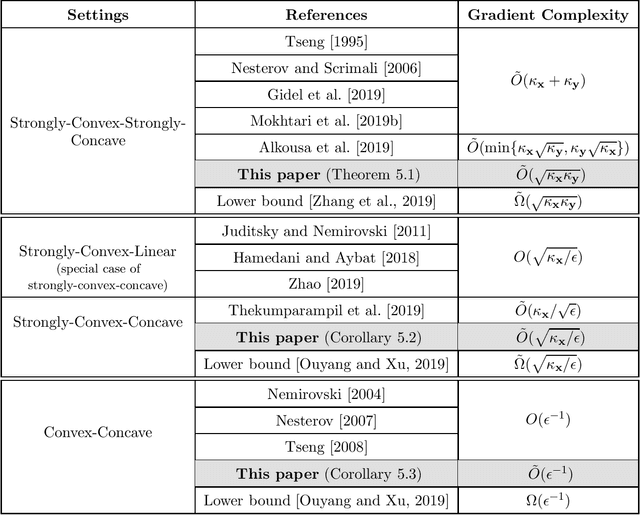
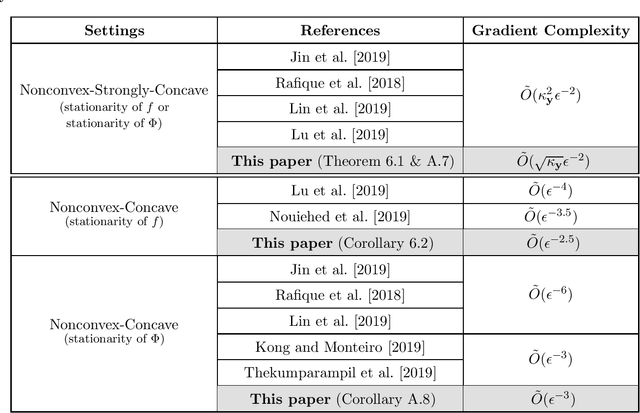
This paper resolves a longstanding open question pertaining to the design of near-optimal first-order algorithms for smooth and strongly-convex-strongly-concave minimax problems. Current state-of-the-art first-order algorithms find an approximate Nash equilibrium using $\tilde{O}(\kappa_{\mathbf x}+\kappa_{\mathbf y})$ or $\tilde{O}(\min\{\kappa_{\mathbf x}\sqrt{\kappa_{\mathbf y}}, \sqrt{\kappa_{\mathbf x}}\kappa_{\mathbf y}\})$ gradient evaluations, where $\kappa_{\mathbf x}$ and $\kappa_{\mathbf y}$ are the condition numbers for the strong-convexity and strong-concavity assumptions. A gap remains between these results and the best existing lower bound $\tilde{\Omega}(\sqrt{\kappa_{\mathbf x}\kappa_{\mathbf y}})$. This paper presents the first algorithm with $\tilde{O}(\sqrt{\kappa_{\mathbf x}\kappa_{\mathbf y}})$ gradient complexity, matching the lower bound up to logarithmic factors. Our new algorithm is designed based on an accelerated proximal point method and an accelerated solver for minimax proximal steps. It can be easily extended to the settings of strongly-convex-concave, convex-concave, nonconvex-strongly-concave, and nonconvex-concave functions. This paper also presents algorithms that match or outperform all existing methods in these settings in terms of gradient complexity, up to logarithmic factors.
Learning Adversarial MDPs with Bandit Feedback and Unknown Transition
Jan 07, 2020We consider the problem of learning in episodic finite-horizon Markov decision processes with an unknown transition function, bandit feedback, and adversarial losses. We propose an efficient algorithm that achieves $\mathcal{\tilde{O}}(L|X|\sqrt{|A|T})$ regret with high probability, where $L$ is the horizon, $|X|$ is the number of states, $|A|$ is the number of actions, and $T$ is the number of episodes. To the best of our knowledge, our algorithm is the first to ensure $\mathcal{\tilde{O}}(\sqrt{T})$ regret in this challenging setting; in fact it achieves the same regret bound as (Rosenberg & Mansour, 2019a) that considers an easier setting with full-information feedback. Our key technical contributions are two-fold: a tighter confidence set for the transition function, and an optimistic loss estimator that is inversely weighted by an $\textit{upper occupancy bound}$.
Provably Efficient Exploration in Policy Optimization
Dec 12, 2019While policy-based reinforcement learning (RL) achieves tremendous successes in practice, it is significantly less understood in theory, especially compared with value-based RL. In particular, it remains elusive how to design a provably efficient policy optimization algorithm that incorporates exploration. To bridge such a gap, this paper proposes an Optimistic variant of the Proximal Policy Optimization algorithm (OPPO), which follows an "optimistic version" of the policy gradient direction. This paper proves that, in the problem of episodic Markov decision process with linear function approximation, unknown transition, and adversarial reward with full-information feedback, OPPO achieves $\tilde{O}(\sqrt{d^3 H^3 T})$ regret. Here $d$ is the feature dimension, $H$ is the episode horizon, and $T$ is the total number of steps. To the best of our knowledge, OPPO is the first provably efficient policy optimization algorithm that explores.
Provably Efficient Reinforcement Learning with Linear Function Approximation
Aug 08, 2019Modern Reinforcement Learning (RL) is commonly applied to practical problems with an enormous number of states, where function approximation must be deployed to approximate either the value function or the policy. The introduction of function approximation raises a fundamental set of challenges involving computational and statistical efficiency, especially given the need to manage the exploration/exploitation tradeoff. As a result, a core RL question remains open: how can we design provably efficient RL algorithms that incorporate function approximation? This question persists even in a basic setting with linear dynamics and linear rewards, for which only linear function approximation is needed. This paper presents the first provable RL algorithm with both polynomial runtime and polynomial sample complexity in this linear setting, without requiring a "simulator" or additional assumptions. Concretely, we prove that an optimistic modification of Least-Squares Value Iteration (LSVI)---a classical algorithm frequently studied in the linear setting---achieves $\tilde{\mathcal{O}}(\sqrt{d^3H^3T})$ regret, where $d$ is the ambient dimension of feature space, $H$ is the length of each episode, and $T$ is the total number of steps. Importantly, such regret is independent of the number of states and actions.
On Gradient Descent Ascent for Nonconvex-Concave Minimax Problems
Jun 02, 2019
We consider nonconvex-concave minimax problems, $\min_{x} \max_{y\in\mathcal{Y}} f(x, y)$, where $f$ is nonconvex in $x$ but concave in $y$. The standard algorithm for solving this problem is the celebrated gradient descent ascent (GDA) algorithm, which has been widely used in machine learning, control theory and economics. However, despite the solid theory for the convex-concave setting, GDA can converge to limit cycles or even diverge in a general setting. In this paper, we present a nonasymptotic analysis of GDA for solving nonconvex-concave minimax problems, showing that GDA can find a stationary point of the function $\Phi(\cdot) :=\max_{y\in\mathcal{Y} }f(\cdot, y)$ efficiently. To the best our knowledge, this is the first theoretical guarantee for GDA in this setting, shedding light on its practical performance in many real applications.
Stochastic Gradient Descent Escapes Saddle Points Efficiently
Feb 13, 2019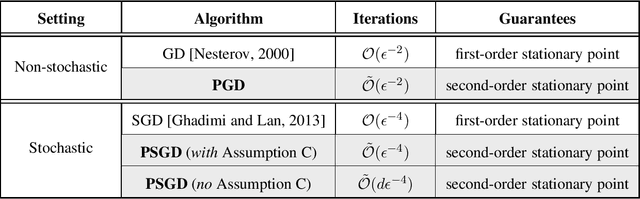
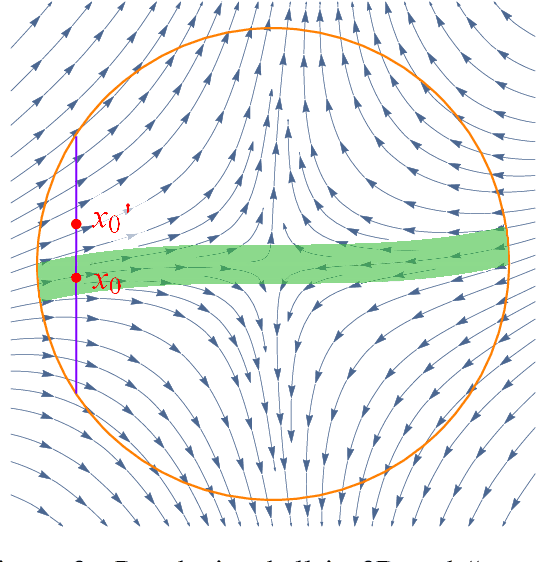
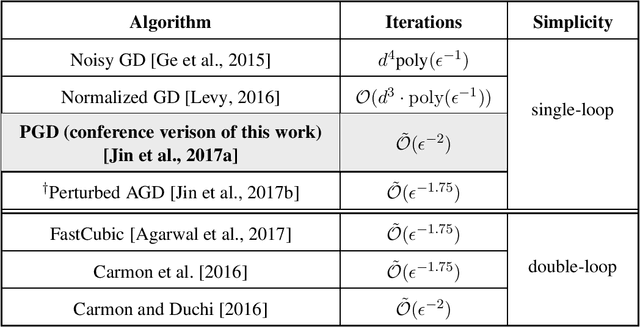
This paper considers the perturbed stochastic gradient descent algorithm and shows that it finds $\epsilon$-second order stationary points ($\left\|\nabla f(x)\right\|\leq \epsilon$ and $\nabla^2 f(x) \succeq -\sqrt{\epsilon} \mathbf{I}$) in $\tilde{O}(d/\epsilon^4)$ iterations, giving the first result that has linear dependence on dimension for this setting. For the special case, where stochastic gradients are Lipschitz, the dependence on dimension reduces to polylogarithmic. In addition to giving new results, this paper also presents a simplified proof strategy that gives a shorter and more elegant proof of previously known results (Jin et al. 2017) on perturbed gradient descent algorithm.
A Short Note on Concentration Inequalities for Random Vectors with SubGaussian Norm
Feb 11, 2019In this note, we derive concentration inequalities for random vectors with subGaussian norm (a generalization of both subGaussian random vectors and norm bounded random vectors), which are tight up to logarithmic factors.
Minmax Optimization: Stable Limit Points of Gradient Descent Ascent are Locally Optimal
Feb 02, 2019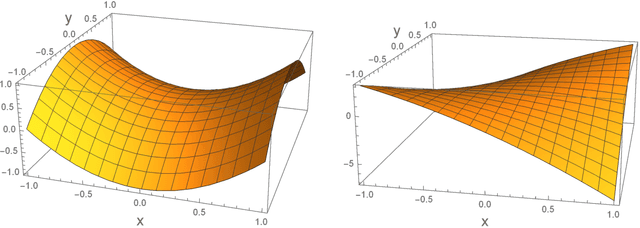
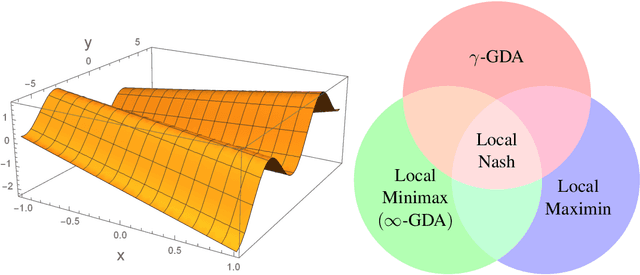
Minmax optimization, especially in its general nonconvex-nonconcave formulation, has found extensive applications in modern machine learning frameworks such as generative adversarial networks (GAN), adversarial training and multi-agent reinforcement learning. Gradient-based algorithms, in particular gradient descent ascent (GDA), are widely used in practice to solve these problems. Despite the practical popularity of GDA, however, its theoretical behavior has been considered highly undesirable. Indeed, apart from possiblity of non-convergence, recent results (Daskalakis and Panageas, 2018; Mazumdar and Ratliff, 2018; Adolphs et al., 2018) show that even when GDA converges, its stable limit points can be points that are not local Nash equilibria, thus not game-theoretically meaningful. In this paper, we initiate a discussion on the proper optimality measures for minmax optimization, and introduce a new notion of local optimality---local minmax---as a more suitable alternative to the notion of local Nash equilibrium. We establish favorable properties of local minmax points, and show, most importantly, that as the ratio of the ascent step size to the descent step size goes to infinity, stable limit points of GDA are exactly local minmax points up to degenerate points, demonstrating that all stable limit points of GDA have a game-theoretic meaning for minmax problems.