 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Learning of Stackelberg Equilibria in General-Sum Games
Feb 23, 2021



Real world applications such as economics and policy making often involve solving multi-agent games with two unique features: (1) The agents are inherently asymmetric and partitioned into leaders and followers; (2) The agents have different reward functions, thus the game is general-sum. The majority of existing results in this field focuses on either symmetric solution concepts (e.g. Nash equilibrium) or zero-sum games. It remains vastly open how to learn the Stackelberg equilibrium -- an asymmetric analog of the Nash equilibrium -- in general-sum games efficiently from samples. This paper initiates the theoretical study of sample-efficient learning of the Stackelberg equilibrium in two-player turn-based general-sum games. We identify a fundamental gap between the exact value of the Stackelberg equilibrium and its estimated version using finite samples, which can not be closed information-theoretically regardless of the algorithm. We then establish a positive result on sample-efficient learning of Stackelberg equilibrium with value optimal up to the gap identified above. We show that our sample complexity is tight with matching upper and lower bounds. Finally, we extend our learning results to the setting where the follower plays in a Markov Decision Process (MDP), and the setting where the leader and the follower act simultaneously.
Near-optimal Representation Learning for Linear Bandits and Linear RL
Feb 08, 2021This paper studies representation learning for multi-task linear bandits and multi-task episodic RL with linear value function approximation. We first consider the setting where we play $M$ linear bandits with dimension $d$ concurrently, and these bandits share a common $k$-dimensional linear representation so that $k\ll d$ and $k \ll M$. We propose a sample-efficient algorithm, MTLR-OFUL, which leverages the shared representation to achieve $\tilde{O}(M\sqrt{dkT} + d\sqrt{kMT} )$ regret, with $T$ being the number of total steps. Our regret significantly improves upon the baseline $\tilde{O}(Md\sqrt{T})$ achieved by solving each task independently. We further develop a lower bound that shows our regret is near-optimal when $d > M$. Furthermore, we extend the algorithm and analysis to multi-task episodic RL with linear value function approximation under low inherent Bellman error \citep{zanette2020learning}. To the best of our knowledge, this is the first theoretical result that characterizes the benefits of multi-task representation learning for exploration in RL with function approximation.
Bellman Eluder Dimension: New Rich Classes of RL Problems, and Sample-Efficient Algorithms
Feb 05, 2021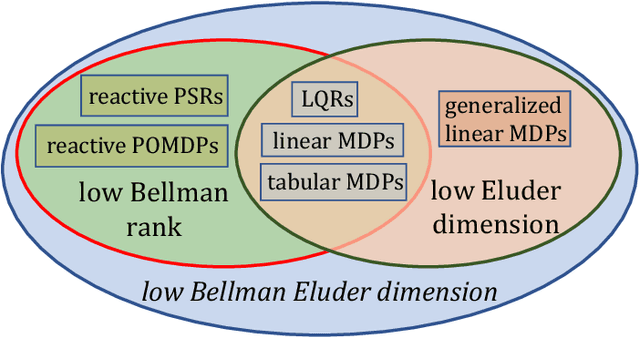
Finding the minimal structural assumptions that empower sample-efficient learning is one of the most important research directions in Reinforcement Learning (RL). This paper advances our understanding of this fundamental question by introducing a new complexity measure -- Bellman Eluder (BE) dimension. We show that the family of RL problems of low BE dimension is remarkably rich, which subsumes a vast majority of existing tractable RL problems including but not limited to tabular MDPs, linear MDPs, reactive POMDPs, low Bellman rank problems as well as low Eluder dimension problems. This paper further designs a new optimization-based algorithm -- GOLF, and reanalyzes a hypothesis elimination-based algorithm -- OLIVE (proposed in Jiang et al. (2017)). We prove that both algorithms learn the near-optimal policies of low BE dimension problems in a number of samples that is polynomial in all relevant parameters, but independent of the size of state-action space. Our regret and sample complexity results match or improve the best existing results for several well-known subclasses of low BE dimension problems.
A Local Convergence Theory for Mildly Over-Parameterized Two-Layer Neural Network
Feb 04, 2021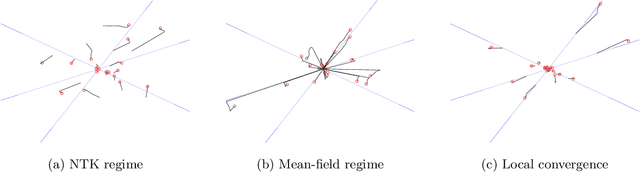
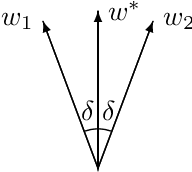
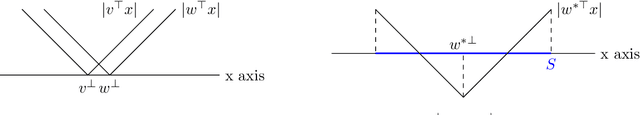
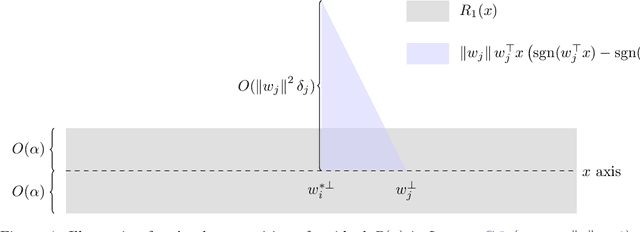
While over-parameterization is widely believed to be crucial for the success of optimization for the neural networks, most existing theories on over-parameterization do not fully explain the reason -- they either work in the Neural Tangent Kernel regime where neurons don't move much, or require an enormous number of neurons. In practice, when the data is generated using a teacher neural network, even mildly over-parameterized neural networks can achieve 0 loss and recover the directions of teacher neurons. In this paper we develop a local convergence theory for mildly over-parameterized two-layer neural net. We show that as long as the loss is already lower than a threshold (polynomial in relevant parameters), all student neurons in an over-parameterized two-layer neural network will converge to one of teacher neurons, and the loss will go to 0. Our result holds for any number of student neurons as long as it is at least as large as the number of teacher neurons, and our convergence rate is independent of the number of student neurons. A key component of our analysis is the new characterization of local optimization landscape -- we show the gradient satisfies a special case of Lojasiewicz property which is different from local strong convexity or PL conditions used in previous work.
Bridging Exploration and General Function Approximation in Reinforcement Learning: Provably Efficient Kernel and Neural Value Iterations
Nov 09, 2020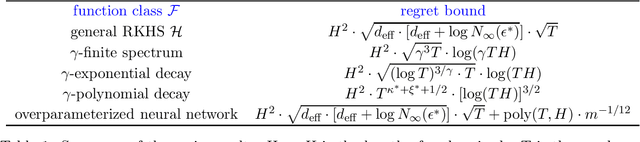
Reinforcement learning (RL) algorithms combined with modern function approximators such as kernel functions and deep neural networks have achieved significant empirical successes in large-scale application problems with a massive number of states. From a theoretical perspective, however, RL with functional approximation poses a fundamental challenge to developing algorithms with provable computational and statistical efficiency, due to the need to take into consideration both the exploration-exploitation tradeoff that is inherent in RL and the bias-variance tradeoff that is innate in statistical estimation. To address such a challenge, focusing on the episodic setting where the action-value functions are represented by a kernel function or over-parametrized neural network, we propose the first provable RL algorithm with both polynomial runtime and sample complexity, without additional assumptions on the data-generating model. In particular, for both the kernel and neural settings, we prove that an optimistic modification of the least-squares value iteration algorithm incurs an $\tilde{\mathcal{O}}(\delta_{\mathcal{F}} H^2 \sqrt{T})$ regret, where $\delta_{\mathcal{F}}$ characterizes the intrinsic complexity of the function class $\mathcal{F}$, $H$ is the length of each episode, and $T$ is the total number of episodes. Our regret bounds are independent of the number of states and therefore even allows it to diverge, which exhibits the benefit of function approximation.
A Sharp Analysis of Model-based Reinforcement Learning with Self-Play
Oct 04, 2020
Model-based algorithms---algorithms that decouple learning of the model and planning given the model---are widely used in reinforcement learning practice and theoretically shown to achieve optimal sample efficiency for single-agent reinforcement learning in Markov Decision Processes (MDPs). However, for multi-agent reinforcement learning in Markov games, the current best known sample complexity for model-based algorithms is rather suboptimal and compares unfavorably against recent model-free approaches. In this paper, we present a sharp analysis of model-based self-play algorithms for multi-agent Markov games. We design an algorithm \emph{Optimistic Nash Value Iteration} (Nash-VI) for two-player zero-sum Markov games that is able to output an $\epsilon$-approximate Nash policy in $\tilde{\mathcal{O}}(H^3SAB/\epsilon^2)$ episodes of game playing, where $S$ is the number of states, $A,B$ are the number of actions for the two players respectively, and $H$ is the horizon length. This is the first algorithm that matches the information-theoretic lower bound $\Omega(H^3S(A+B)/\epsilon^2)$ except for a $\min\{A,B\}$ factor, and compares favorably against the best known model-free algorithm if $\min\{A,B\}=o(H^3)$. In addition, our Nash-VI outputs a single Markov policy with optimality guarantee, while existing sample-efficient model-free algorithms output a nested mixture of Markov policies that is in general non-Markov and rather inconvenient to store and execute. We further adapt our analysis to designing a provably efficient task-agnostic algorithm for zero-sum Markov games, and designing the first line of provably sample-efficient algorithms for multi-player general-sum Markov games.
Near-Optimal Reinforcement Learning with Self-Play
Jul 14, 2020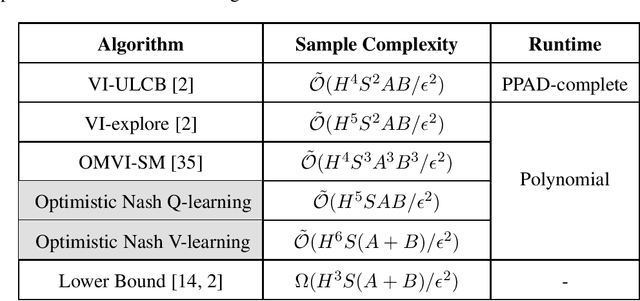
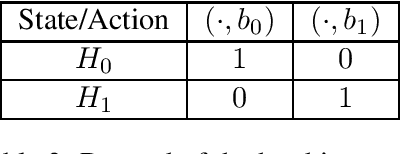
This paper considers the problem of designing optimal algorithms for reinforcement learning in two-player zero-sum games. We focus on self-play algorithms which learn the optimal policy by playing against itself without any direct supervision. In a tabular episodic Markov game with $S$ states, $A$ max-player actions and $B$ min-player actions, the best existing algorithm for finding an approximate Nash equilibrium requires $\tilde{\mathcal{O}}(S^2AB)$ steps of game playing, when only highlighting the dependency on $(S,A,B)$. In contrast, the best existing lower bound scales as $\Omega(S(A+B))$ and has a significant gap from the upper bound. This paper closes this gap for the first time: we propose an optimistic variant of the \emph{Nash Q-learning} algorithm with sample complexity $\tilde{\mathcal{O}}(SAB)$, and a new \emph{Nash V-learning} algorithm with sample complexity $\tilde{\mathcal{O}}(S(A+B))$. The latter result matches the information-theoretic lower bound in all problem-dependent parameters except for a polynomial factor of the length of each episode. In addition, we present a computational hardness result for learning the best responses against a fixed opponent in Markov games---a learning objective different from finding the Nash equilibrium.
Sample-Efficient Reinforcement Learning of Undercomplete POMDPs
Jun 22, 2020Partial observability is a common challenge in many reinforcement learning applications, which requires an agent to maintain memory, infer latent states, and integrate this past information into exploration. This challenge leads to a number of computational and statistical hardness results for learning general Partially Observable Markov Decision Processes (POMDPs). This work shows that these hardness barriers do not preclude efficient reinforcement learning for rich and interesting subclasses of POMDPs. In particular, we present a sample-efficient algorithm, OOM-UCB, for episodic finite undercomplete POMDPs, where the number of observations is larger than the number of latent states and where exploration is essential for learning, thus distinguishing our results from prior works. OOM-UCB achieves an optimal sample complexity of $O(1/\epsilon^2)$ for finding an $\epsilon$-optimal policy, along with being polynomial in all other relevant quantities. As an interesting special case, we also provide a computationally and statistically efficient algorithm for POMDPs with deterministic state transitions.
On the Theory of Transfer Learning: The Importance of Task Diversity
Jun 20, 2020We provide new statistical guarantees for transfer learning via representation learning--when transfer is achieved by learning a feature representation shared across different tasks. This enables learning on new tasks using far less data than is required to learn them in isolation. Formally, we consider $t+1$ tasks parameterized by functions of the form $f_j \circ h$ in a general function class $\mathcal{F} \circ \mathcal{H}$, where each $f_j$ is a task-specific function in $\mathcal{F}$ and $h$ is the shared representation in $\mathcal{H}$. Letting $C(\cdot)$ denote the complexity measure of the function class, we show that for diverse training tasks (1) the sample complexity needed to learn the shared representation across the first $t$ training tasks scales as $C(\mathcal{H}) + t C(\mathcal{F})$, despite no explicit access to a signal from the feature representation and (2) with an accurate estimate of the representation, the sample complexity needed to learn a new task scales only with $C(\mathcal{F})$. Our results depend upon a new general notion of task diversity--applicable to models with general tasks, features, and losses--as well as a novel chain rule for Gaussian complexities. Finally, we exhibit the utility of our general framework in several models of importance in the literature.
Provable Meta-Learning of Linear Representations
Feb 26, 2020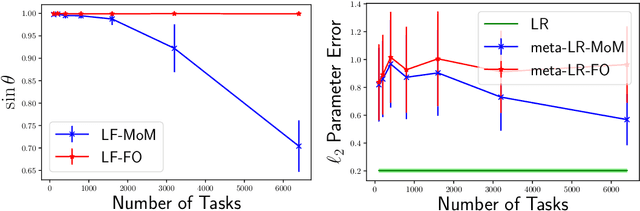
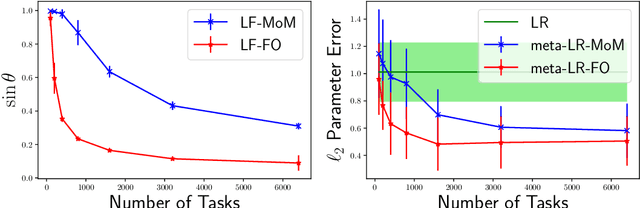
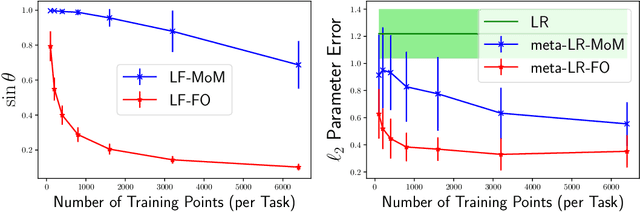
Meta-learning, or learning-to-learn, seeks to design algorithms that can utilize previous experience to rapidly learn new skills or adapt to new environments. Representation learning---a key tool for performing meta-learning---learns a data representation that can transfer knowledge across multiple tasks, which is essential in regimes where data is scarce. Despite a recent surge of interest in the practice of meta-learning, the theoretical underpinnings of meta-learning algorithms are lacking, especially in the context of learning transferable representations. In this paper, we focus on the problem of multi-task linear regression---in which multiple linear regression models share a common, low-dimensional linear representation. Here, we provide provably fast, sample-efficient algorithms to address the dual challenges of (1) learning a common set of features from multiple, related tasks, and (2) transferring this knowledge to new, unseen tasks. Both are central to the general problem of meta-learning. Finally, we complement these results by providing information-theoretic lower bounds on the sample complexity of learning these linear features, showing that our algorithms are optimal up to logarithmic factors.