 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Explanations: Leveraging Human Input to Align Explainable AI
Jan 23, 2023



While a vast collection of explainable AI (XAI) algorithms have been developed in recent years, they are often criticized for significant gaps with how humans produce and consume explanations. As a result, current XAI techniques are often found to be hard to use and lack effectiveness. In this work, we attempt to close these gaps by making AI explanations selective -- a fundamental property of human explanations -- by selectively presenting a subset from a large set of model reasons based on what aligns with the recipient's preferences. We propose a general framework for generating selective explanations by leveraging human input on a small sample. This framework opens up a rich design space that accounts for different selectivity goals, types of input, and more. As a showcase, we use a decision-support task to explore selective explanations based on what the decision-maker would consider relevant to the decision task. We conducted two experimental studies to examine three out of a broader possible set of paradigms based on our proposed framework: in Study 1, we ask the participants to provide their own input to generate selective explanations, with either open-ended or critique-based input. In Study 2, we show participants selective explanations based on input from a panel of similar users (annotators). Our experiments demonstrate the promise of selective explanations in reducing over-reliance on AI and improving decision outcomes and subjective perceptions of the AI, but also paint a nuanced picture that attributes some of these positive effects to the opportunity to provide one's own input to augment AI explanations. Overall, our work proposes a novel XAI framework inspired by human communication behaviors and demonstrates its potentials to encourage future work to better align AI explanations with human production and consumption of explanations.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022



The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
Active Example Selection for In-Context Learning
Nov 08, 2022With a handful of demonstration examples, large-scale language models show strong capability to perform various tasks by in-context learning from these examples, without any fine-tuning. We demonstrate that in-context learning performance can be highly unstable across samples of examples, indicating the idiosyncrasies of how language models acquire information. We formulate example selection for in-context learning as a sequential decision problem, and propose a reinforcement learning algorithm for identifying generalizable policies to select demonstration examples. For GPT-2, our learned policies demonstrate strong abilities of generalizing to unseen tasks in training, with a $5.8\%$ improvement on average. Examples selected from our learned policies can even achieve a small improvement on GPT-3 Ada. However, the improvement diminishes on larger GPT-3 models, suggesting emerging capabilities of large language models.
Probing Classifiers are Unreliable for Concept Removal and Detection
Jul 08, 2022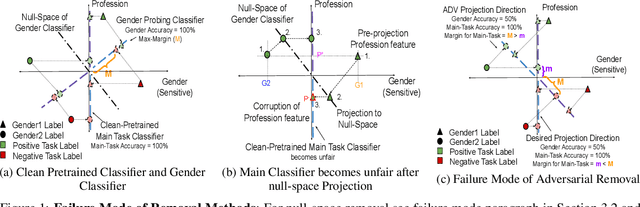
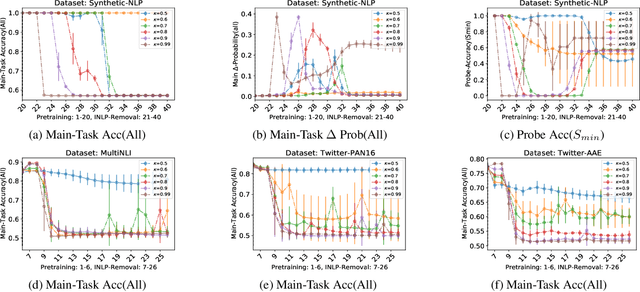
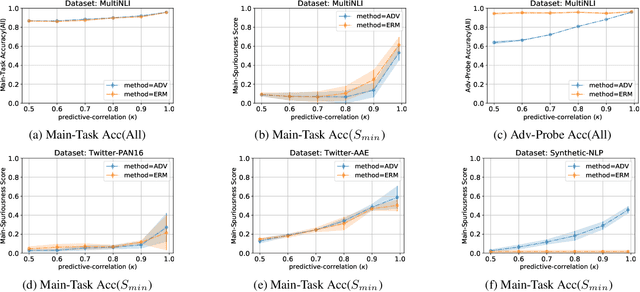
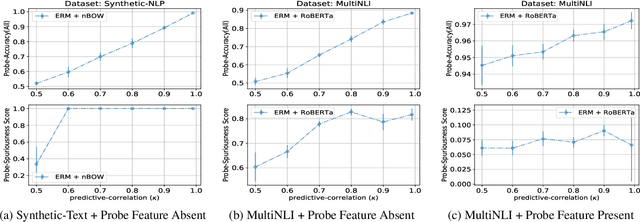
Neural network models trained on text data have been found to encode undesired linguistic or sensitive attributes in their representation. Removing such attributes is non-trivial because of a complex relationship between the attribute, text input, and the learnt representation. Recent work has proposed post-hoc and adversarial methods to remove such unwanted attributes from a model's representation. Through an extensive theoretical and empirical analysis, we show that these methods can be counter-productive: they are unable to remove the attributes entirely, and in the worst case may end up destroying all task-relevant features. The reason is the methods' reliance on a probing classifier as a proxy for the attribute. Even under the most favorable conditions when an attribute's features in representation space can alone provide 100% accuracy for learning the probing classifier, we prove that post-hoc or adversarial methods will fail to remove the attribute correctly. These theoretical implications are confirmed by empirical experiments on models trained on synthetic, Multi-NLI, and Twitter datasets. For sensitive applications of attribute removal such as fairness, we recommend caution against using these methods and propose a spuriousness metric to gauge the quality of the final classifier.
Learning to Ignore Adversarial Attacks
May 23, 2022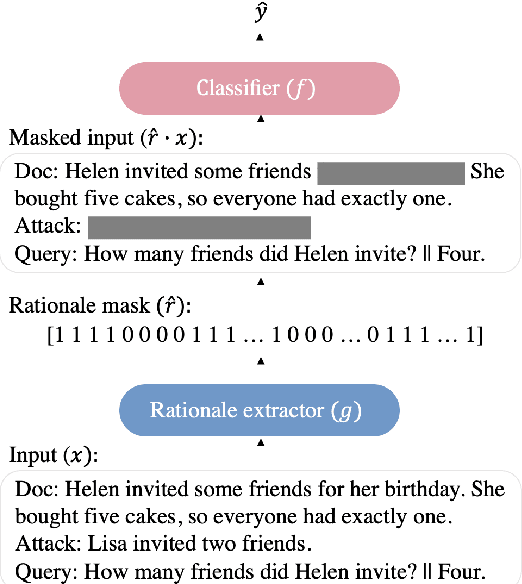
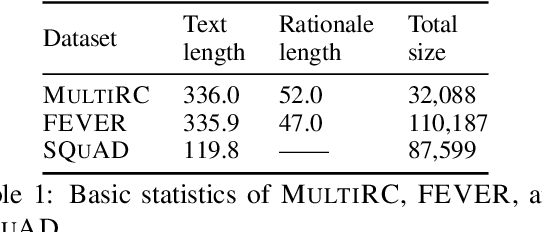

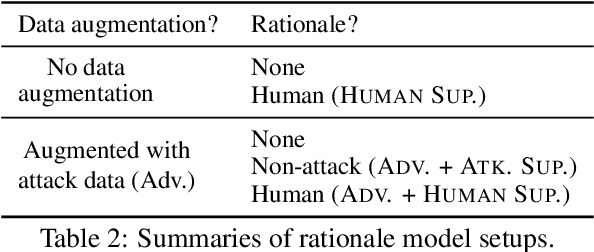
Despite the strong performance of current NLP models, they can be brittle against adversarial attacks. To enable effective learning against adversarial inputs, we introduce the use of rationale models that can explicitly learn to ignore attack tokens. We find that the rationale models can successfully ignore over 90\% of attack tokens. This approach leads to consistent sizable improvements ($\sim$10\%) over baseline models in robustness on three datasets for both BERT and RoBERTa, and also reliably outperforms data augmentation with adversarial examples alone. In many cases, we find that our method is able to close the gap between model performance on a clean test set and an attacked test set and hence reduce the effect of adversarial attacks.
Human-AI Collaboration via Conditional Delegation: A Case Study of Content Moderation
Apr 25, 2022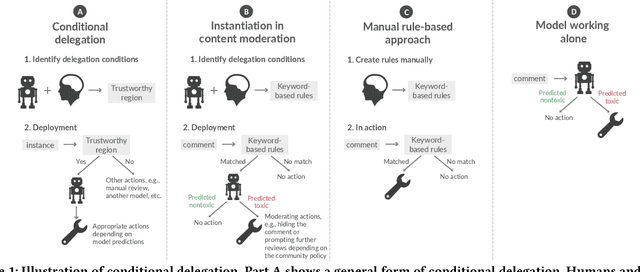

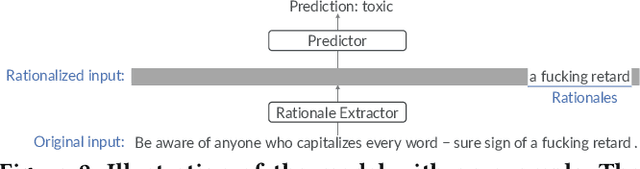
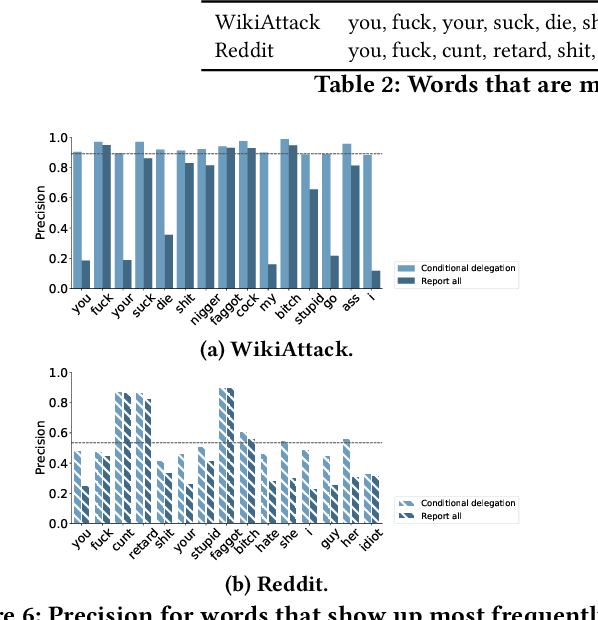
Despite impressive performance in many benchmark datasets, AI models can still make mistakes, especially among out-of-distribution examples. It remains an open question how such imperfect models can be used effectively in collaboration with humans. Prior work has focused on AI assistance that helps people make individual high-stakes decisions, which is not scalable for a large amount of relatively low-stakes decisions, e.g., moderating social media comments. Instead, we propose conditional delegation as an alternative paradigm for human-AI collaboration where humans create rules to indicate trustworthy regions of a model. Using content moderation as a testbed, we develop novel interfaces to assist humans in creating conditional delegation rules and conduct a randomized experiment with two datasets to simulate in-distribution and out-of-distribution scenarios. Our study demonstrates the promise of conditional delegation in improving model performance and provides insights into design for this novel paradigm, including the effect of AI explanations.
Machine Explanations and Human Understanding
Feb 08, 2022



Explanations are hypothesized to improve human understanding of machine learning models and achieve a variety of desirable outcomes, ranging from model debugging to enhancing human decision making. However, empirical studies have found mixed and even negative results. An open question, therefore, is under what conditions explanations can improve human understanding and in what way. Using adapted causal diagrams, we provide a formal characterization of the interplay between machine explanations and human understanding, and show how human intuitions play a central role in enabling human understanding. Specifically, we identify three core concepts of interest that cover all existing quantitative measures of understanding in the context of human-AI decision making: task decision boundary, model decision boundary, and model error. Our key result is that without assumptions about task-specific intuitions, explanations may potentially improve human understanding of model decision boundary, but they cannot improve human understanding of task decision boundary or model error. To achieve complementary human-AI performance, we articulate possible ways on how explanations need to work with human intuitions. For instance, human intuitions about the relevance of features (e.g., education is more important than age in predicting a person's income) can be critical in detecting model error. We validate the importance of human intuitions in shaping the outcome of machine explanations with empirical human-subject studies. Overall, our work provides a general framework along with actionable implications for future algorithmic development and empirical experiments of machine explanations.
Rethinking Explainability as a Dialogue: A Practitioner's Perspective
Feb 03, 2022
As practitioners increasingly deploy machine learning models in critical domains such as health care, finance, and policy, it becomes vital to ensure that domain experts function effectively alongside these models. Explainability is one way to bridge the gap between human decision-makers and machine learning models. However, most of the existing work on explainability focuses on one-off, static explanations like feature importances or rule lists. These sorts of explanations may not be sufficient for many use cases that require dynamic, continuous discovery from stakeholders. In the literature, few works ask decision-makers about the utility of existing explanations and other desiderata they would like to see in an explanation going forward. In this work, we address this gap and carry out a study where we interview doctors, healthcare professionals, and policymakers about their needs and desires for explanations. Our study indicates that decision-makers would strongly prefer interactive explanations in the form of natural language dialogues. Domain experts wish to treat machine learning models as "another colleague", i.e., one who can be held accountable by asking why they made a particular decision through expressive and accessible natural language interactions. Considering these needs, we outline a set of five principles researchers should follow when designing interactive explanations as a starting place for future work. Further, we show why natural language dialogues satisfy these principles and are a desirable way to build interactive explanations. Next, we provide a design of a dialogue system for explainability and discuss the risks, trade-offs, and research opportunities of building these systems. Overall, we hope our work serves as a starting place for researchers and engineers to design interactive explainability systems.
Towards a Science of Human-AI Decision Making: A Survey of Empirical Studies
Dec 21, 2021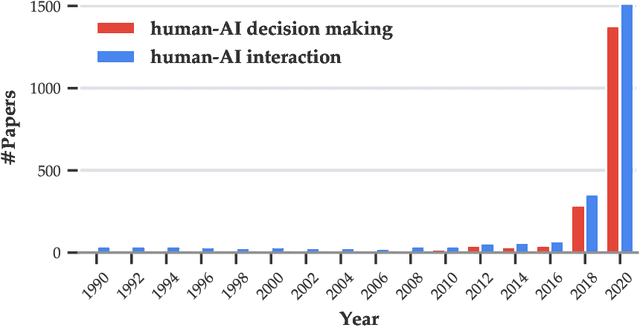
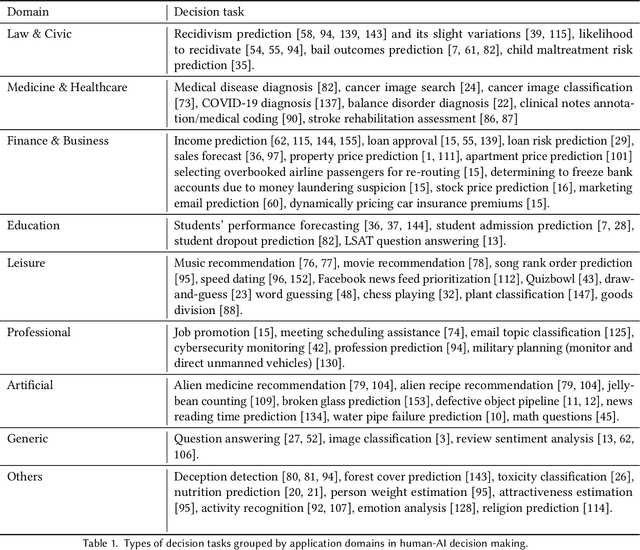
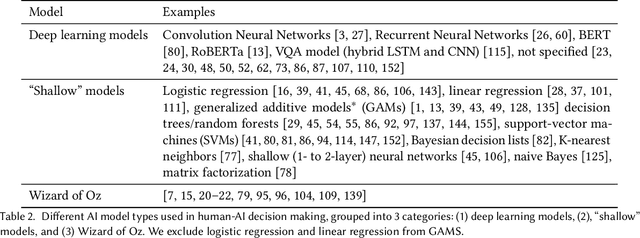
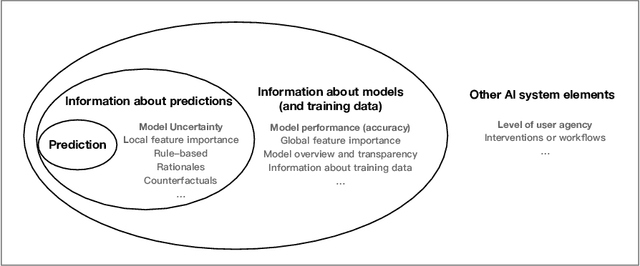
As AI systems demonstrate increasingly strong predictive performance, their adoption has grown in numerous domains. However, in high-stakes domains such as criminal justice and healthcare, full automation is often not desirable due to safety, ethical, and legal concerns, yet fully manual approaches can be inaccurate and time consuming. As a result, there is growing interest in the research community to augment human decision making with AI assistance. Besides developing AI technologies for this purpose, the emerging field of human-AI decision making must embrace empirical approaches to form a foundational understanding of how humans interact and work with AI to make decisions. To invite and help structure research efforts towards a science of understanding and improving human-AI decision making, we survey recent literature of empirical human-subject studies on this topic. We summarize the study design choices made in over 100 papers in three important aspects: (1) decision tasks, (2) AI models and AI assistance elements, and (3) evaluation metrics. For each aspect, we summarize current trends, discuss gaps in current practices of the field, and make a list of recommendations for future research. Our survey highlights the need to develop common frameworks to account for the design and research spaces of human-AI decision making, so that researchers can make rigorous choices in study design, and the research community can build on each other's work and produce generalizable scientific knowledge. We also hope this survey will serve as a bridge for HCI and AI communities to work together to mutually shape the empirical science and computational technologies for human-AI decision making.
What to Learn, and How: Toward Effective Learning from Rationales
Nov 30, 2021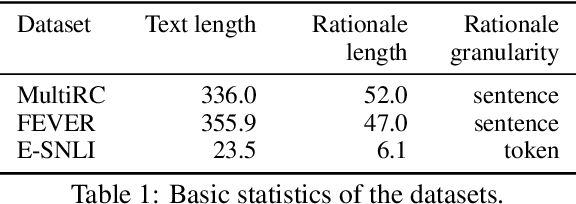
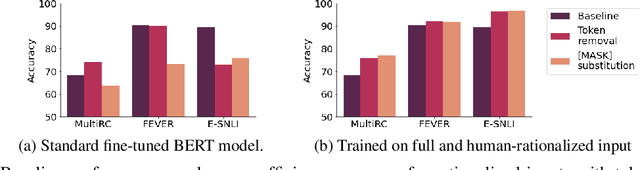
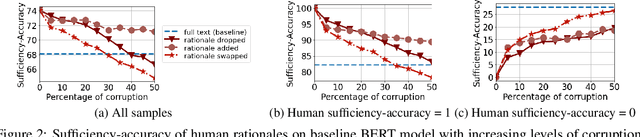
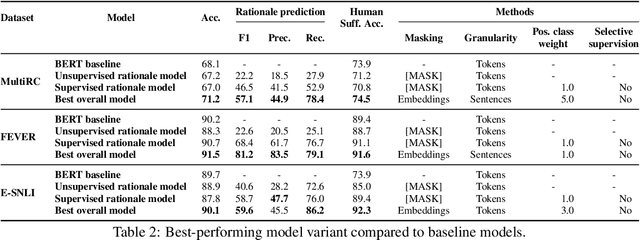
Learning from rationales seeks to augment model training with human-provided rationales (i.e., a subset of input tokens) that justify those labels. While intuitive, this idea has proven elusive in practice. We make two observations about human rationales via empirical analyses: 1) maximizing predicted rationale accuracy is not necessarily the optimal objective for improving model performance; 2) human rationales vary in whether they provide sufficient information for the model to exploit for prediction, and we can use this variance to assess a dataset's potential improvement from learning from rationales. Building on these insights, we propose loss functions and learning strategies, and evaluate their effectiveness on three datasets with human rationales. Our results demonstrate consistent improvements over baselines in both label performance and rationale performance, including a 3% accuracy improvement on MultiRC. Our work highlights the importance of understanding properties of human explanations and exploiting them accordingly in model training.