 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Preference Optimization: Aligning Language Models to Expert Distributions
Apr 30, 2024
We propose Soft Preference Optimization (SPO), a method for aligning generative models, such as Large Language Models (LLMs), with human preferences, without the need for a reward model. SPO optimizes model outputs directly over a preference dataset through a natural loss function that integrates preference loss with a regularization term across the model's entire output distribution rather than limiting it to the preference dataset. Although SPO does not require the assumption of an existing underlying reward model, we demonstrate that, under the Bradley-Terry (BT) model assumption, it converges to a softmax of scaled rewards, with the distribution's "softness" adjustable via the softmax exponent, an algorithm parameter. We showcase SPO's methodology, its theoretical foundation, and its comparative advantages in simplicity, computational efficiency, and alignment precision.
Automatic Music Playlist Generation via Simulation-based Reinforcement Learning
Oct 13, 2023



Personalization of playlists is a common feature in music streaming services, but conventional techniques, such as collaborative filtering, rely on explicit assumptions regarding content quality to learn how to make recommendations. Such assumptions often result in misalignment between offline model objectives and online user satisfaction metrics. In this paper, we present a reinforcement learning framework that solves for such limitations by directly optimizing for user satisfaction metrics via the use of a simulated playlist-generation environment. Using this simulator we develop and train a modified Deep Q-Network, the action head DQN (AH-DQN), in a manner that addresses the challenges imposed by the large state and action space of our RL formulation. The resulting policy is capable of making recommendations from large and dynamic sets of candidate items with the expectation of maximizing consumption metrics. We analyze and evaluate agents offline via simulations that use environment models trained on both public and proprietary streaming datasets. We show how these agents lead to better user-satisfaction metrics compared to baseline methods during online A/B tests. Finally, we demonstrate that performance assessments produced from our simulator are strongly correlated with observed online metric results.
What to Learn, and How: Toward Effective Learning from Rationales
Nov 30, 2021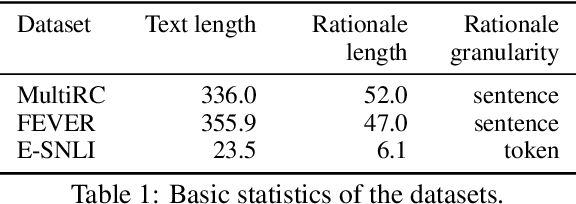
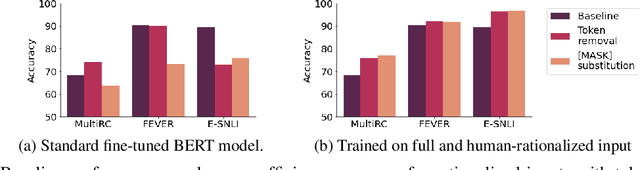
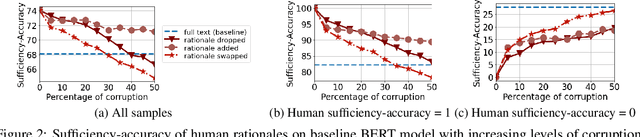
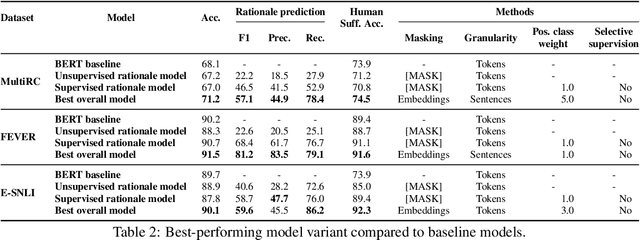
Learning from rationales seeks to augment model training with human-provided rationales (i.e., a subset of input tokens) that justify those labels. While intuitive, this idea has proven elusive in practice. We make two observations about human rationales via empirical analyses: 1) maximizing predicted rationale accuracy is not necessarily the optimal objective for improving model performance; 2) human rationales vary in whether they provide sufficient information for the model to exploit for prediction, and we can use this variance to assess a dataset's potential improvement from learning from rationales. Building on these insights, we propose loss functions and learning strategies, and evaluate their effectiveness on three datasets with human rationales. Our results demonstrate consistent improvements over baselines in both label performance and rationale performance, including a 3% accuracy improvement on MultiRC. Our work highlights the importance of understanding properties of human explanations and exploiting them accordingly in model training.