 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMUG-Bench: Benchmarking Unified Multimodal Models on Interleaved Understanding and Generation
Jun 08, 2026In recent years, unified multimodal models (UMMs) have emerged to support both understanding and generation within a single framework. Mastering dynamic, multi-turn interleaved image-text dialogues is a crucial task for UMMs in real-world applications. However, existing benchmarks fail to evaluate this important task, as they are often limited to single-turn or static settings, and typically overlook exposure bias in multi-turn interactions. To bridge this gap, we propose IMUG-Bench, a comprehensive benchmark for multi-turn interleaved image-text dialogue of UMMs that jointly evaluates their understanding and generation capabilities. Our IMUG-Bench comprises three classes: Static Spatial, Temporal Causal, and Hybrid, covering 3,113 samples and 12,034 interaction turns. It also includes dynamic understanding questions, thereby supporting evaluation that better reflects real-world multi-turn interaction scenarios. Large-scale experiments on IMUG-Bench systematically evaluate mainstream open-source and closed-source UMMs, revealing their capability boundaries and failure modes, and uncovering pronounced exposure bias on the generation side in multi-turn interactions. We further explore several test-time scaling strategies, including Chain-of-Thought, Self-Verification, and Best-of-N Sampling, which effectively improve generation accuracy and mitigate exposure bias in generation tasks. These findings provide insights into enhancing the robustness and multi-turn interaction capability of future UMMs.
Pelican-Unified 1.0: A Unified Embodied Intelligence Model for Understanding, Reasoning, Imagination and Action
May 14, 2026We present Pelican-Unified 1.0, the first embodied foundation model trained according to the principle of unification. Pelican-Unified 1.0 uses a single VLM as a unified understanding module, mapping scenes, instructions, visual contexts, and action histories into a shared semantic space. The same VLM also serves as a unified reasoning module, autoregressively producing task-, action-, and future-oriented chains of thought in a single forward pass and projecting the final hidden state into a dense latent variable. A Unified Future Generator (UFG) then conditions on this latent variable and jointly generates future videos and future actions through two modality-specific output heads within the same denoising process. The language, video, and action losses are all backpropagated into the shared representation, enabling the model to jointly optimize understanding, reasoning, imagination, and action during training, rather than training three isolated expert systems. Experiments demonstrate that unification does not imply compromise. With a single checkpoint, Pelican-Unified 1.0 achieves strong performance across all three capabilities: 64.7 on eight VLM benchmarks, the best among comparable-scale models; 66.03 on WorldArena, ranking first; and 93.5 on RoboTwin, the second-best average among compared action methods. These results show that the unified paradigm succeeds in preserving specialist strength while bringing understanding, reasoning, imagination, and action into one model.
Imagine a City: CityGenAgent for Procedural 3D City Generation
Feb 05, 2026The automated generation of interactive 3D cities is a critical challenge with broad applications in autonomous driving, virtual reality, and embodied intelligence. While recent advances in generative models and procedural techniques have improved the realism of city generation, existing methods often struggle with high-fidelity asset creation, controllability, and manipulation. In this work, we introduce CityGenAgent, a natural language-driven framework for hierarchical procedural generation of high-quality 3D cities. Our approach decomposes city generation into two interpretable components, Block Program and Building Program. To ensure structural correctness and semantic alignment, we adopt a two-stage learning strategy: (1) Supervised Fine-Tuning (SFT). We train BlockGen and BuildingGen to generate valid programs that adhere to schema constraints, including non-self-intersecting polygons and complete fields; (2) Reinforcement Learning (RL). We design Spatial Alignment Reward to enhance spatial reasoning ability and Visual Consistency Reward to bridge the gap between textual descriptions and the visual modality. Benefiting from the programs and the models' generalization, CityGenAgent supports natural language editing and manipulation. Comprehensive evaluations demonstrate superior semantic alignment, visual quality, and controllability compared to existing methods, establishing a robust foundation for scalable 3D city generation.
Drive-KD: Multi-Teacher Distillation for VLMs in Autonomous Driving
Jan 29, 2026Autonomous driving is an important and safety-critical task, and recent advances in LLMs/VLMs have opened new possibilities for reasoning and planning in this domain. However, large models demand substantial GPU memory and exhibit high inference latency, while conventional supervised fine-tuning (SFT) often struggles to bridge the capability gaps of small models. To address these limitations, we propose Drive-KD, a framework that decomposes autonomous driving into a "perception-reasoning-planning" triad and transfers these capabilities via knowledge distillation. We identify layer-specific attention as the distillation signal to construct capability-specific single-teacher models that outperform baselines. Moreover, we unify these single-teacher settings into a multi-teacher distillation framework and introduce asymmetric gradient projection to mitigate cross-capability gradient conflicts. Extensive evaluations validate the generalization of our method across diverse model families and scales. Experiments show that our distilled InternVL3-1B model, with ~42 times less GPU memory and ~11.4 times higher throughput, achieves better overall performance than the pretrained 78B model from the same family on DriveBench, and surpasses GPT-5.1 on the planning dimension, providing insights toward efficient autonomous driving VLMs.
AutoDriDM: An Explainable Benchmark for Decision-Making of Vision-Language Models in Autonomous Driving
Jan 21, 2026Autonomous driving is a highly challenging domain that requires reliable perception and safe decision-making in complex scenarios. Recent vision-language models (VLMs) demonstrate reasoning and generalization abilities, opening new possibilities for autonomous driving; however, existing benchmarks and metrics overemphasize perceptual competence and fail to adequately assess decision-making processes. In this work, we present AutoDriDM, a decision-centric, progressive benchmark with 6,650 questions across three dimensions - Object, Scene, and Decision. We evaluate mainstream VLMs to delineate the perception-to-decision capability boundary in autonomous driving, and our correlation analysis reveals weak alignment between perception and decision-making performance. We further conduct explainability analyses of models' reasoning processes, identifying key failure modes such as logical reasoning errors, and introduce an analyzer model to automate large-scale annotation. AutoDriDM bridges the gap between perception-centered and decision-centered evaluation, providing guidance toward safer and more reliable VLMs for real-world autonomous driving.
CLEAR: A Clinically-Grounded Tabular Framework for Radiology Report Evaluation
May 22, 2025
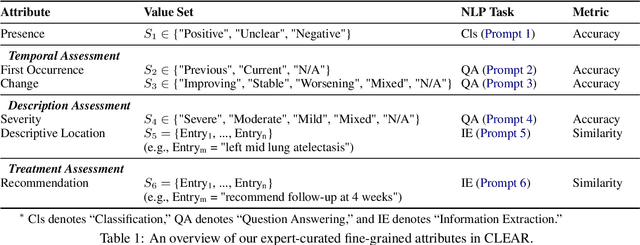
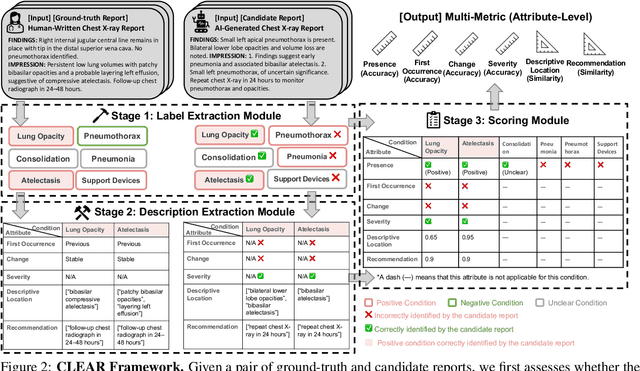
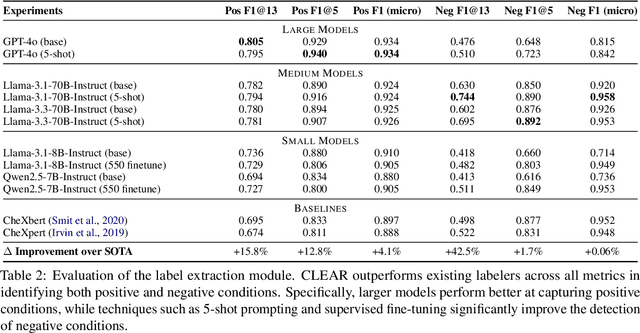
Existing metrics often lack the granularity and interpretability to capture nuanced clinical differences between candidate and ground-truth radiology reports, resulting in suboptimal evaluation. We introduce a Clinically-grounded tabular framework with Expert-curated labels and Attribute-level comparison for Radiology report evaluation (CLEAR). CLEAR not only examines whether a report can accurately identify the presence or absence of medical conditions, but also assesses whether it can precisely describe each positively identified condition across five key attributes: first occurrence, change, severity, descriptive location, and recommendation. Compared to prior works, CLEAR's multi-dimensional, attribute-level outputs enable a more comprehensive and clinically interpretable evaluation of report quality. Additionally, to measure the clinical alignment of CLEAR, we collaborate with five board-certified radiologists to develop CLEAR-Bench, a dataset of 100 chest X-ray reports from MIMIC-CXR, annotated across 6 curated attributes and 13 CheXpert conditions. Our experiments show that CLEAR achieves high accuracy in extracting clinical attributes and provides automated metrics that are strongly aligned with clinical judgment.