 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStratified Expert Cloning with Adaptive Selection for User Retention in Large-Scale Recommender Systems
Apr 08, 2025



User retention has emerged as a critical challenge in large-scale recommender systems, significantly impacting the long-term success of online platforms. Existing methods often focus on short-term engagement metrics, failing to capture the complex dynamics of user preferences and behaviors over extended periods. While reinforcement learning (RL) approaches have shown promise in optimizing long-term rewards, they face difficulties in credit assignment, sample efficiency, and exploration when applied to the user retention problem. In this work, we propose Stratified Expert Cloning (SEC), a novel imitation learning framework that effectively leverages abundant logged data from high-retention users to learn robust recommendation policies. SEC introduces three key innovations: 1) a multi-level expert stratification strategy that captures the nuances in expert user behaviors at different retention levels; 2) an adaptive expert selection mechanism that dynamically assigns users to the most suitable policy based on their current state and historical retention level; and 3) an action entropy regularization technique that promotes recommendation diversity and mitigates the risk of policy collapse. Through extensive offline experiments and online A/B tests on two major video platforms, Kuaishou and Kuaishou Lite, with hundreds of millions of daily active users, we demonstrate SEC's significant improvements over state-of-the-art methods in user retention. The results demonstrate significant improvements in user retention, with cumulative lifts of 0.098\% and 0.122\% in active days on Kuaishou and Kuaishou Lite respectively, additionally bringing tens of thousands of daily active users to each platform.
AlignPxtr: Aligning Predicted Behavior Distributions for Bias-Free Video Recommendations
Mar 11, 2025In video recommendation systems, user behaviors such as watch time, likes, and follows are commonly used to infer user interest. However, these behaviors are influenced by various biases, including duration bias, demographic biases, and content category biases, which obscure true user preferences. In this paper, we hypothesize that biases and user interest are independent of each other. Based on this assumption, we propose a novel method that aligns predicted behavior distributions across different bias conditions using quantile mapping, theoretically guaranteeing zero mutual information between bias variables and the true user interest. By explicitly modeling the conditional distributions of user behaviors under different biases and mapping these behaviors to quantiles, we effectively decouple user interest from the confounding effects of various biases. Our approach uniquely handles both continuous signals (e.g., watch time) and discrete signals (e.g., likes, comments), while simultaneously addressing multiple bias dimensions. Additionally, we introduce a computationally efficient mean alignment alternative technique for practical real-time inference in large-scale systems. We validate our method through online A/B testing on two major video platforms: Kuaishou Lite and Kuaishou. The results demonstrate significant improvements in user engagement and retention, with \textbf{cumulative lifts of 0.267\% and 0.115\% in active days, and 1.102\% and 0.131\% in average app usage time}, respectively. The results demonstrate that our approach consistently achieves significant improvements in long-term user retention and substantial gains in average app usage time across different platforms. Our core code will be publised at https://github.com/justopit/CQE.
Harnessing Large Vision and Language Models in Agriculture: A Review
Jul 29, 2024Large models can play important roles in many domains. Agriculture is another key factor affecting the lives of people around the world. It provides food, fabric, and coal for humanity. However, facing many challenges such as pests and diseases, soil degradation, global warming, and food security, how to steadily increase the yield in the agricultural sector is a problem that humans still need to solve. Large models can help farmers improve production efficiency and harvest by detecting a series of agricultural production tasks such as pests and diseases, soil quality, and seed quality. It can also help farmers make wise decisions through a variety of information, such as images, text, etc. Herein, we delve into the potential applications of large models in agriculture, from large language model (LLM) and large vision model (LVM) to large vision-language models (LVLM). After gaining a deeper understanding of multimodal large language models (MLLM), it can be recognized that problems such as agricultural image processing, agricultural question answering systems, and agricultural machine automation can all be solved by large models. Large models have great potential in the field of agriculture. We outline the current applications of agricultural large models, and aims to emphasize the importance of large models in the domain of agriculture. In the end, we envisage a future in which famers use MLLM to accomplish many tasks in agriculture, which can greatly improve agricultural production efficiency and yield.
Conditional Quantile Estimation for Uncertain Watch Time in Short-Video Recommendation
Jul 17, 2024



Within the domain of short video recommendation, predicting users' watch time is a critical but challenging task. Prevailing deterministic solutions obtain accurate debiased statistical models, yet they neglect the intrinsic uncertainty inherent in user environments. In our observation, we found that this uncertainty could potentially limit these methods' accuracy in watch-time prediction on our online platform, despite that we have employed numerous features and complex network architectures. Consequently, we believe that a better solution is to model the conditional distribution of this uncertain watch time. In this paper, we introduce a novel estimation technique -- Conditional Quantile Estimation (CQE), which utilizes quantile regression to capture the nuanced distribution of watch time. The learned distribution accounts for the stochastic nature of users, thereby it provides a more accurate and robust estimation. In addition, we also design several strategies to enhance the quantile prediction including conditional expectation, conservative estimation, and dynamic quantile combination. We verify the effectiveness of our method through extensive offline evaluations using public datasets as well as deployment in a real-world video application with over 300 million daily active users.
SoccerNet 2022 Challenges Results
Oct 05, 2022
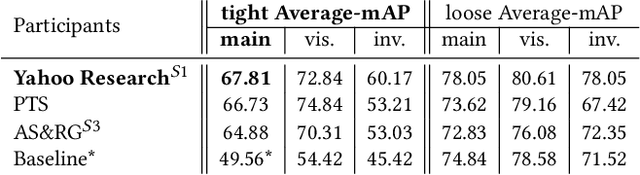
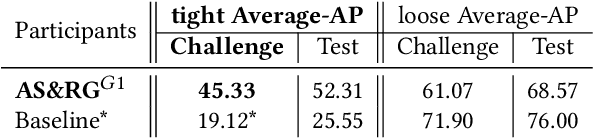
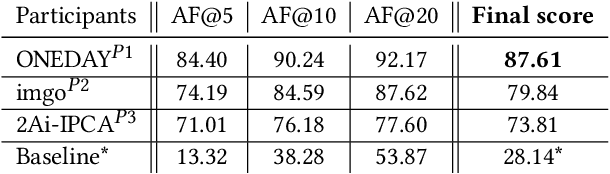
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Text-Adaptive Multiple Visual Prototype Matching for Video-Text Retrieval
Sep 27, 2022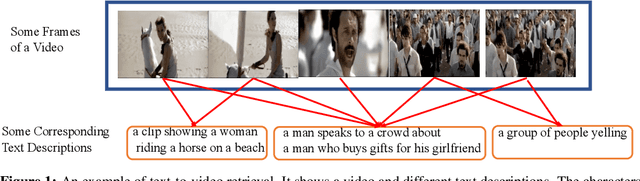
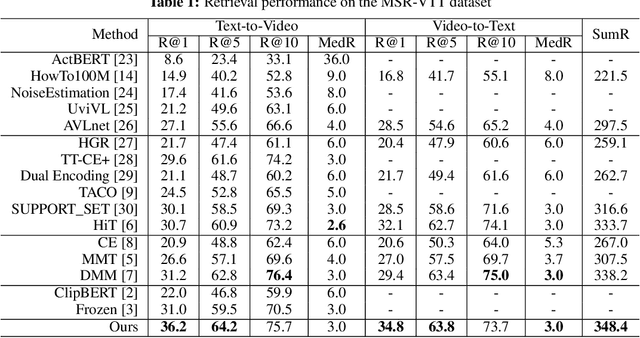
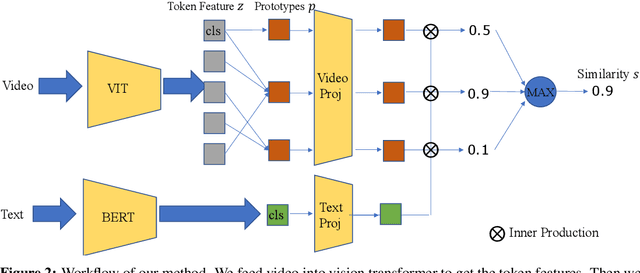
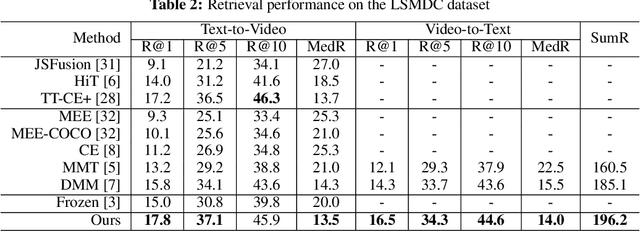
Cross-modal retrieval between videos and texts has gained increasing research interest due to the rapid emergence of videos on the web. Generally, a video contains rich instance and event information and the query text only describes a part of the information. Thus, a video can correspond to multiple different text descriptions and queries. We call this phenomenon the ``Video-Text Correspondence Ambiguity'' problem. Current techniques mostly concentrate on mining local or multi-level alignment between contents of a video and text (\textit{e.g.}, object to entity and action to verb). It is difficult for these methods to alleviate the video-text correspondence ambiguity by describing a video using only one single feature, which is required to be matched with multiple different text features at the same time. To address this problem, we propose a Text-Adaptive Multiple Visual Prototype Matching model, which automatically captures multiple prototypes to describe a video by adaptive aggregation of video token features. Given a query text, the similarity is determined by the most similar prototype to find correspondence in the video, which is termed text-adaptive matching. To learn diverse prototypes for representing the rich information in videos, we propose a variance loss to encourage different prototypes to attend to different contents of the video. Our method outperforms state-of-the-art methods on four public video retrieval datasets.
* NIPS2022