 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective KV-Cache Sharing to Mitigate Timing Side-Channels in LLM Inference
Aug 11, 2025Global KV-cache sharing has emerged as a key optimization for accelerating large language model (LLM) inference. However, it exposes a new class of timing side-channel attacks, enabling adversaries to infer sensitive user inputs via shared cache entries. Existing defenses, such as per-user isolation, eliminate leakage but degrade performance by up to 38.9% in time-to-first-token (TTFT), making them impractical for high-throughput deployment. To address this gap, we introduce SafeKV (Secure and Flexible KV Cache Sharing), a privacy-aware KV-cache management framework that selectively shares non-sensitive entries while confining sensitive content to private caches. SafeKV comprises three components: (i) a hybrid, multi-tier detection pipeline that integrates rule-based pattern matching, a general-purpose privacy detector, and context-aware validation; (ii) a unified radix-tree index that manages public and private entries across heterogeneous memory tiers (HBM, DRAM, SSD); and (iii) entropy-based access monitoring to detect and mitigate residual information leakage. Our evaluation shows that SafeKV mitigates 94% - 97% of timing-based side-channel attacks. Compared to per-user isolation method, SafeKV improves TTFT by up to 40.58% and throughput by up to 2.66X across diverse LLMs and workloads. SafeKV reduces cache-induced TTFT overhead from 50.41% to 11.74% on Qwen3-235B. By combining fine-grained privacy control with high cache reuse efficiency, SafeKV reclaims the performance advantages of global sharing while providing robust runtime privacy guarantees for LLM inference.
LSTM-QGAN: Scalable NISQ Generative Adversarial Network
Sep 03, 2024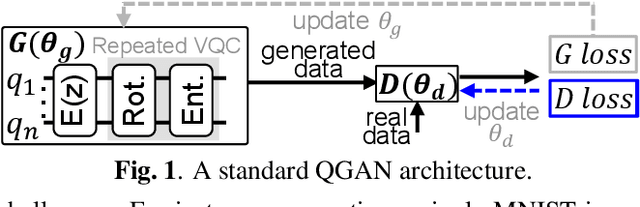
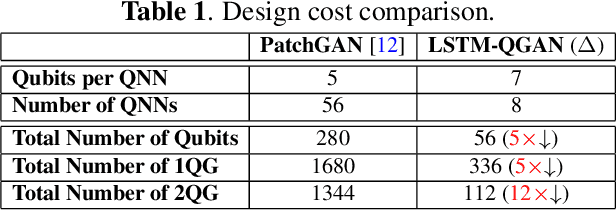
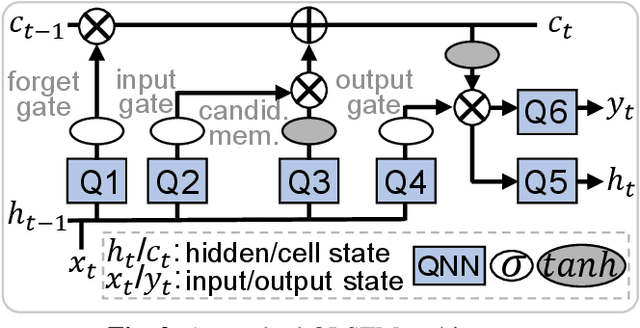

Current quantum generative adversarial networks (QGANs) still struggle with practical-sized data. First, many QGANs use principal component analysis (PCA) for dimension reduction, which, as our studies reveal, can diminish the QGAN's effectiveness. Second, methods that segment inputs into smaller patches processed by multiple generators face scalability issues. In this work, we propose LSTM-QGAN, a QGAN architecture that eliminates PCA preprocessing and integrates quantum long short-term memory (QLSTM) to ensure scalable performance. Our experiments show that LSTM-QGAN significantly enhances both performance and scalability over state-of-the-art QGAN models, with visual data improvements, reduced Frechet Inception Distance scores, and reductions of 5x in qubit counts, 5x in single-qubit gates, and 12x in two-qubit gates.
QuantumLeak: Stealing Quantum Neural Networks from Cloud-based NISQ Machines
Mar 16, 2024



Variational quantum circuits (VQCs) have become a powerful tool for implementing Quantum Neural Networks (QNNs), addressing a wide range of complex problems. Well-trained VQCs serve as valuable intellectual assets hosted on cloud-based Noisy Intermediate Scale Quantum (NISQ) computers, making them susceptible to malicious VQC stealing attacks. However, traditional model extraction techniques designed for classical machine learning models encounter challenges when applied to NISQ computers due to significant noise in current devices. In this paper, we introduce QuantumLeak, an effective and accurate QNN model extraction technique from cloud-based NISQ machines. Compared to existing classical model stealing techniques, QuantumLeak improves local VQC accuracy by 4.99\%$\sim$7.35\% across diverse datasets and VQC architectures.
QTrojan: A Circuit Backdoor Against Quantum Neural Networks
Feb 16, 2023We propose a circuit-level backdoor attack, \textit{QTrojan}, against Quantum Neural Networks (QNNs) in this paper. QTrojan is implemented by few quantum gates inserted into the variational quantum circuit of the victim QNN. QTrojan is much stealthier than a prior Data-Poisoning-based Backdoor Attack (DPBA), since it does not embed any trigger in the inputs of the victim QNN or require the access to original training datasets. Compared to a DPBA, QTrojan improves the clean data accuracy by 21\% and the attack success rate by 19.9\%.