 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Coarse-Graining of Molecular Conformations
Jan 28, 2022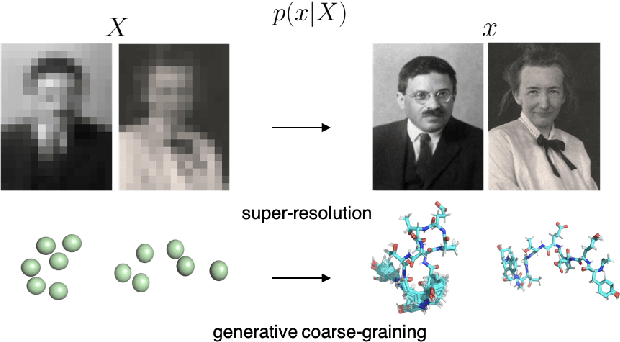

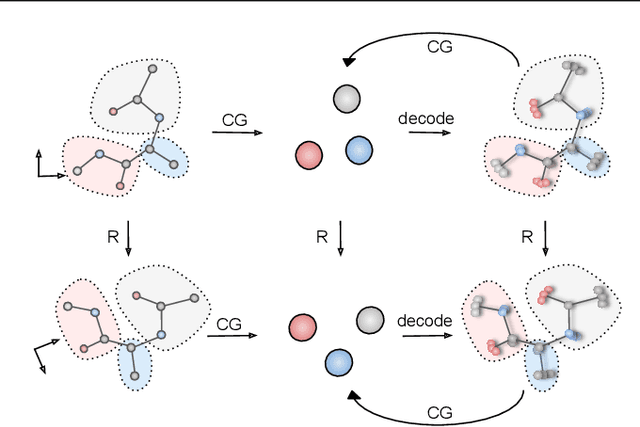
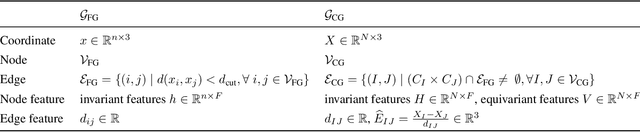
Coarse-graining (CG) of molecular simulations simplifies the particle representation by grouping selected atoms into pseudo-beads and therefore drastically accelerates simulation. However, such CG procedure induces information losses, which makes accurate backmapping, i.e., restoring fine-grained (FG) coordinates from CG coordinates, a long-standing challenge. Inspired by the recent progress in generative models and equivariant networks, we propose a novel model that rigorously embeds the vital probabilistic nature and geometric consistency requirements of the backmapping transformation. Our model encodes the FG uncertainties into an invariant latent space and decodes them back to FG geometries via equivariant convolutions. To standardize the evaluation of this domain, we further provide three comprehensive benchmarks based on molecular dynamics trajectories. Extensive experiments show that our approach always recovers more realistic structures and outperforms existing data-driven methods with a significant margin.
Convergence of Invariant Graph Networks
Jan 25, 2022


Although theoretical properties such as expressive power and over-smoothing of graph neural networks (GNN) have been extensively studied recently, its convergence property is a relatively new direction. In this paper, we investigate the convergence of one powerful GNN, Invariant Graph Network (IGN) over graphs sampled from graphons. We first prove the stability of linear layers for general $k$-IGN (of order $k$) based on a novel interpretation of linear equivariant layers. Building upon this result, we prove the convergence of $k$-IGN under the model of \citet{ruiz2020graphon}, where we access the edge weight but the convergence error is measured for graphon inputs. Under the more natural (and more challenging) setting of \citet{keriven2020convergence} where one can only access 0-1 adjacency matrix sampled according to edge probability, we first show a negative result that the convergence of any IGN is not possible. We then obtain the convergence of a subset of IGNs, denoted as IGN-small, after the edge probability estimation. We show that IGN-small still contains function class rich enough that can approximate spectral GNNs arbitrarily well. Lastly, we perform experiments on various graphon models to verify our statements.
Traffic4cast -- Large-scale Traffic Prediction using 3DResNet and Sparse-UNet
Nov 10, 2021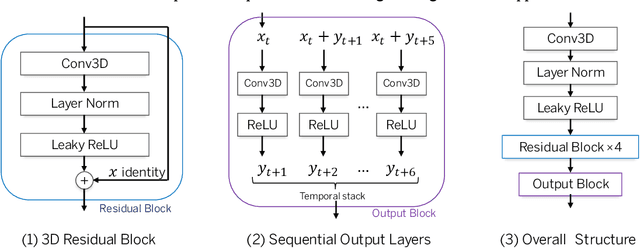
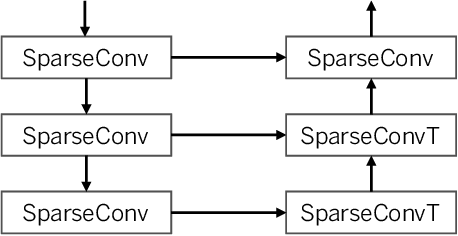
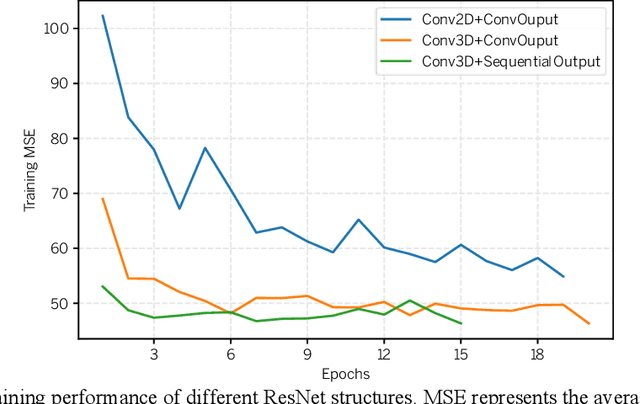

The IARAI competition Traffic4cast 2021 aims to predict short-term city-wide high-resolution traffic states given the static and dynamic traffic information obtained previously. The aim is to build a machine learning model for predicting the normalized average traffic speed and flow of the subregions of multiple large-scale cities using historical data points. The model is supposed to be generic, in a way that it can be applied to new cities. By considering spatiotemporal feature learning and modeling efficiency, we explore 3DResNet and Sparse-UNet approaches for the tasks in this competition. The 3DResNet based models use 3D convolution to learn the spatiotemporal features and apply sequential convolutional layers to enhance the temporal relationship of the outputs. The Sparse-UNet model uses sparse convolutions as the backbone for spatiotemporal feature learning. Since the latter algorithm mainly focuses on non-zero data points of the inputs, it dramatically reduces the computation time, while maintaining a competitive accuracy. Our results show that both of the proposed models achieve much better performance than the baseline algorithms. The codes and pretrained models are available at https://github.com/resuly/Traffic4Cast-2021.
Equivariant Subgraph Aggregation Networks
Oct 06, 2021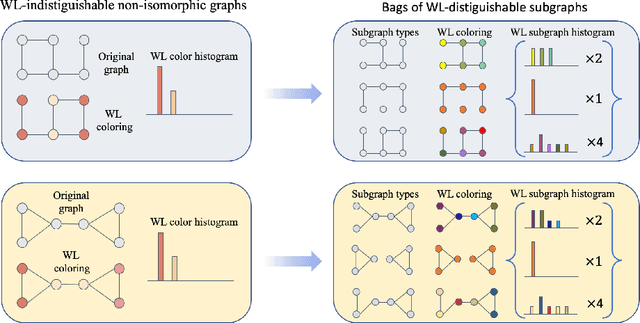
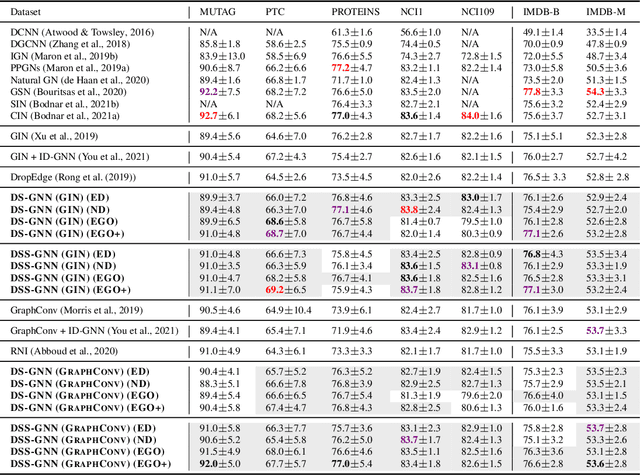
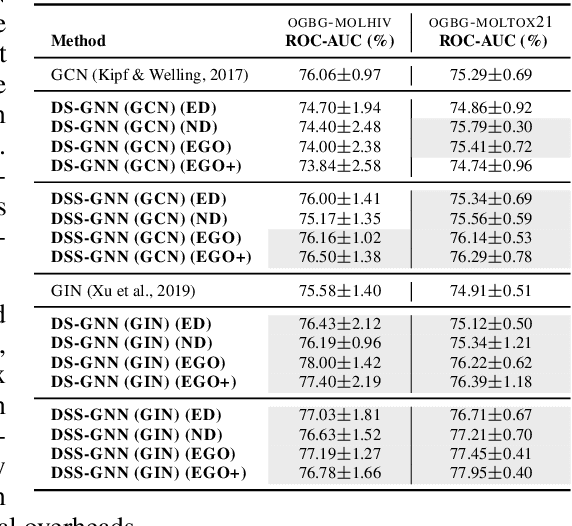
Message-passing neural networks (MPNNs) are the leading architecture for deep learning on graph-structured data, in large part due to their simplicity and scalability. Unfortunately, it was shown that these architectures are limited in their expressive power. This paper proposes a novel framework called Equivariant Subgraph Aggregation Networks (ESAN) to address this issue. Our main observation is that while two graphs may not be distinguishable by an MPNN, they often contain distinguishable subgraphs. Thus, we propose to represent each graph as a set of subgraphs derived by some predefined policy, and to process it using a suitable equivariant architecture. We develop novel variants of the 1-dimensional Weisfeiler-Leman (1-WL) test for graph isomorphism, and prove lower bounds on the expressiveness of ESAN in terms of these new WL variants. We further prove that our approach increases the expressive power of both MPNNs and more expressive architectures. Moreover, we provide theoretical results that describe how design choices such as the subgraph selection policy and equivariant neural architecture affect our architecture's expressive power. To deal with the increased computational cost, we propose a subgraph sampling scheme, which can be viewed as a stochastic version of our framework. A comprehensive set of experiments on real and synthetic datasets demonstrates that our framework improves the expressive power and overall performance of popular GNN architectures.
Equivariant geometric learning for digital rock physics: estimating formation factor and effective permeability tensors from Morse graph
Apr 12, 2021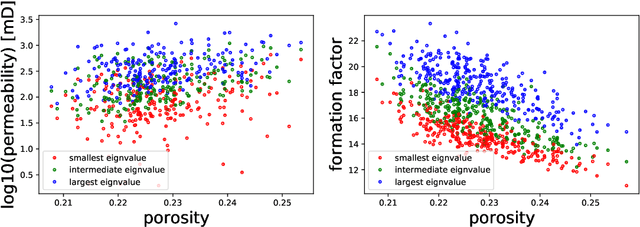
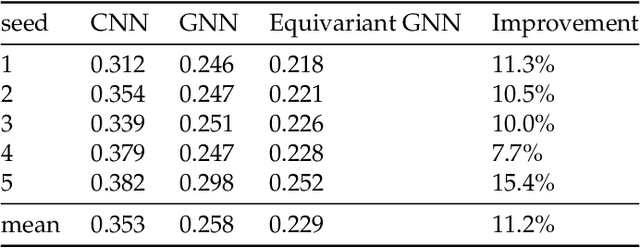
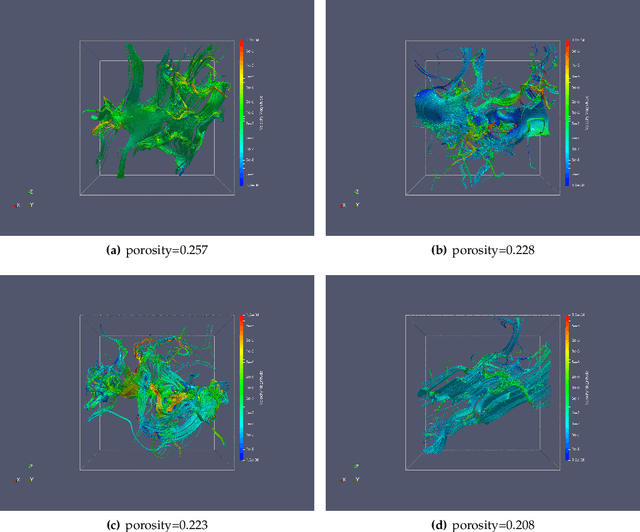
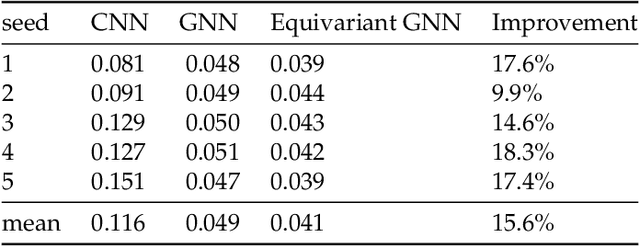
We present a SE(3)-equivariant graph neural network (GNN) approach that directly predicting the formation factor and effective permeability from micro-CT images. FFT solvers are established to compute both the formation factor and effective permeability, while the topology and geometry of the pore space are represented by a persistence-based Morse graph. Together, they constitute the database for training, validating, and testing the neural networks. While the graph and Euclidean convolutional approaches both employ neural networks to generate low-dimensional latent space to represent the features of the micro-structures for forward predictions, the SE(3) equivariant neural network is found to generate more accurate predictions, especially when the training data is limited. Numerical experiments have also shown that the new SE(3) approach leads to predictions that fulfill the material frame indifference whereas the predictions from classical convolutional neural networks (CNN) may suffer from spurious dependence on the coordinate system of the training data. Comparisons among predictions inferred from training the CNN and those from graph convolutional neural networks (GNN) with and without the equivariant constraint indicate that the equivariant graph neural network seems to perform better than the CNN and GNN without enforcing equivariant constraints.
Graph Coarsening with Neural Networks
Feb 02, 2021
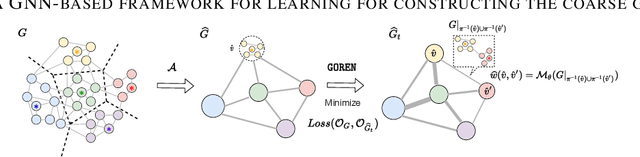
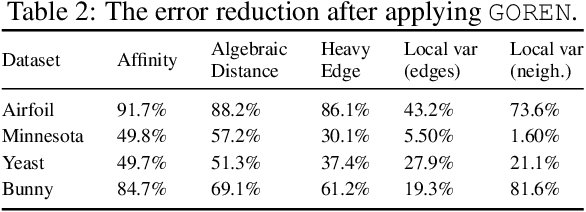
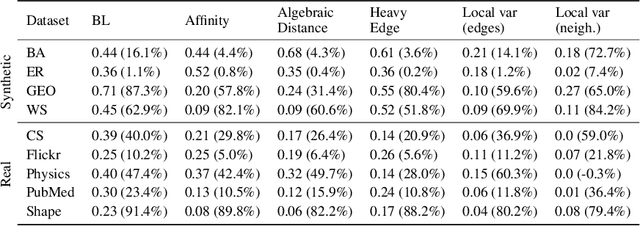
As large-scale graphs become increasingly more prevalent, it poses significant computational challenges to process, extract and analyze large graph data. Graph coarsening is one popular technique to reduce the size of a graph while maintaining essential properties. Despite rich graph coarsening literature, there is only limited exploration of data-driven methods in the field. In this work, we leverage the recent progress of deep learning on graphs for graph coarsening. We first propose a framework for measuring the quality of coarsening algorithm and show that depending on the goal, we need to carefully choose the Laplace operator on the coarse graph and associated projection/lift operators. Motivated by the observation that the current choice of edge weight for the coarse graph may be sub-optimal, we parametrize the weight assignment map with graph neural networks and train it to improve the coarsening quality in an unsupervised way. Through extensive experiments on both synthetic and real networks, we demonstrate that our method significantly improves common graph coarsening methods under various metrics, reduction ratios, graph sizes, and graph types. It generalizes to graphs of larger size ($25\times$ of training graphs), is adaptive to different losses (differentiable and non-differentiable), and scales to much larger graphs than previous work.
Energy consumption forecasting using a stacked nonparametric Bayesian approach
Nov 11, 2020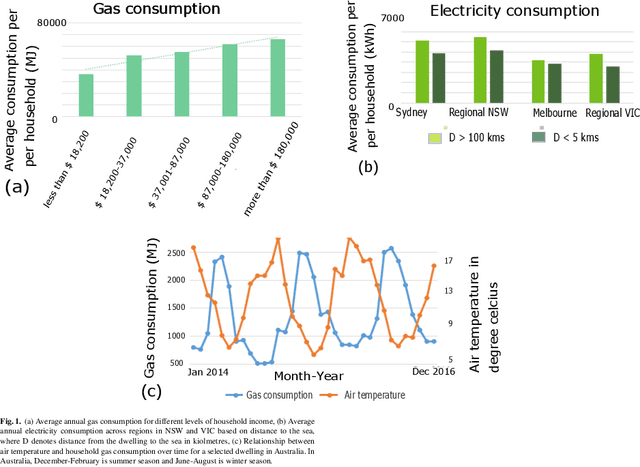
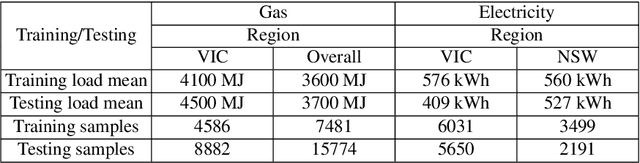
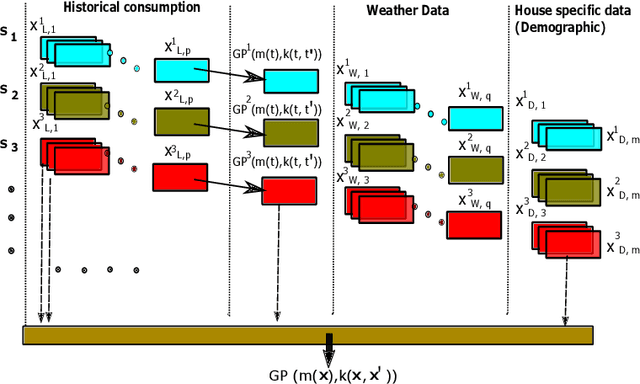
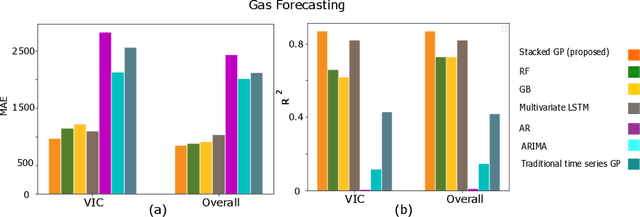
In this paper, the process of forecasting household energy consumption is studied within the framework of the nonparametric Gaussian Process (GP), using multiple short time series data. As we begin to use smart meter data to paint a clearer picture of residential electricity use, it becomes increasingly apparent that we must also construct a detailed picture and understanding of consumer's complex relationship with gas consumption. Both electricity and gas consumption patterns are highly dependent on various factors, and the intricate interplay of these factors is sophisticated. Moreover, since typical gas consumption data is low granularity with very few time points, naive application of conventional time-series forecasting techniques can lead to severe over-fitting. Given these considerations, we construct a stacked GP method where the predictive posteriors of each GP applied to each task are used in the prior and likelihood of the next level GP. We apply our model to a real-world dataset to forecast energy consumption in Australian households across several states. We compare intuitively appealing results against other commonly used machine learning techniques. Overall, the results indicate that the proposed stacked GP model outperforms other forecasting techniques that we tested, especially when we have a multiple short time-series instances.
A Note on Over-Smoothing for Graph Neural Networks
Jun 23, 2020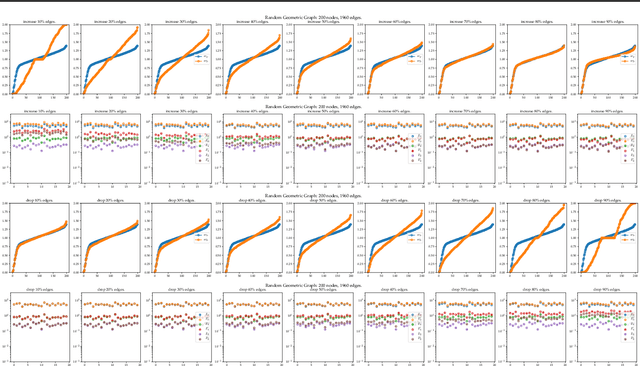
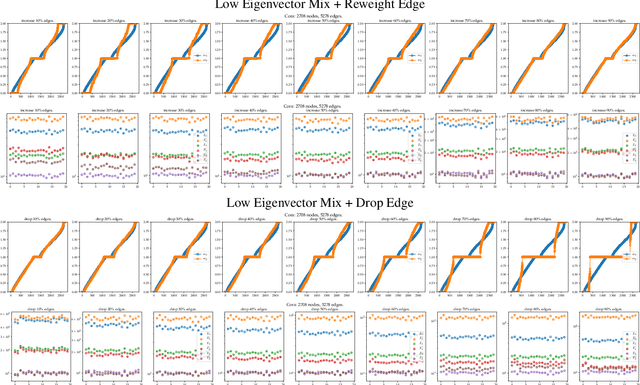
Graph Neural Networks (GNNs) have achieved a lot of success on graph-structured data. However, it is observed that the performance of graph neural networks does not improve as the number of layers increases. This effect, known as over-smoothing, has been analyzed mostly in linear cases. In this paper, we build upon previous results \cite{oono2019graph} to further analyze the over-smoothing effect in the general graph neural network architecture. We show when the weight matrix satisfies the conditions determined by the spectrum of augmented normalized Laplacian, the Dirichlet energy of embeddings will converge to zero, resulting in the loss of discriminative power. Using Dirichlet energy to measure "expressiveness" of embedding is conceptually clean; it leads to simpler proofs than \cite{oono2019graph} and can handle more non-linearities.
Understanding the Power of Persistence Pairing via Permutation Test
Jan 16, 2020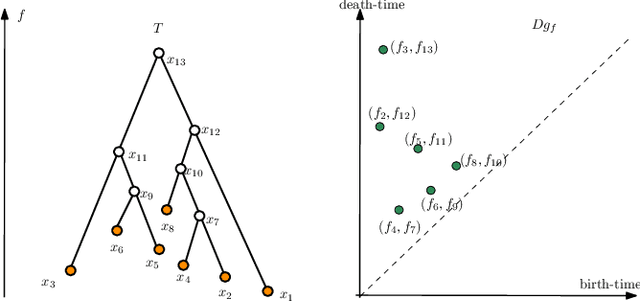
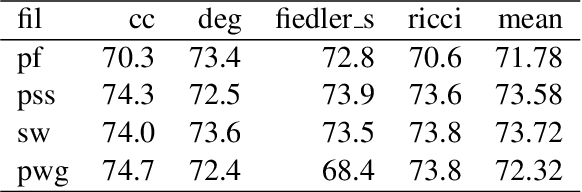
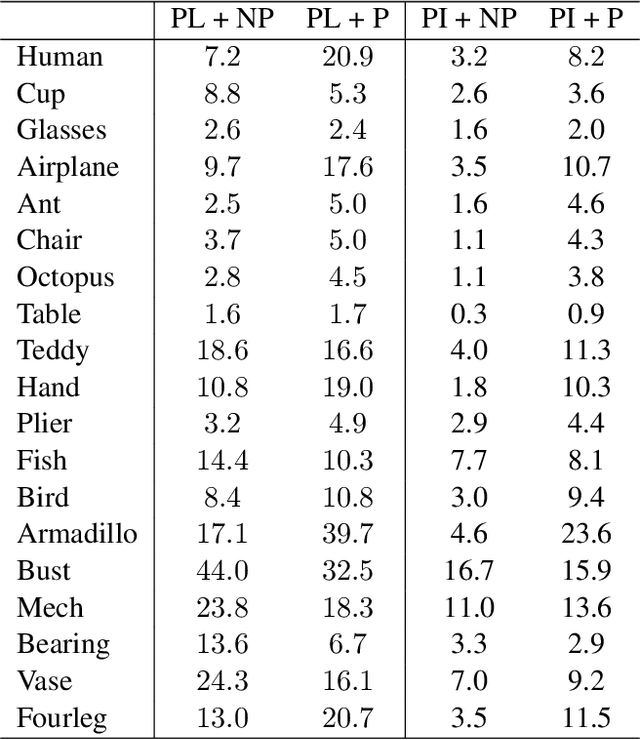
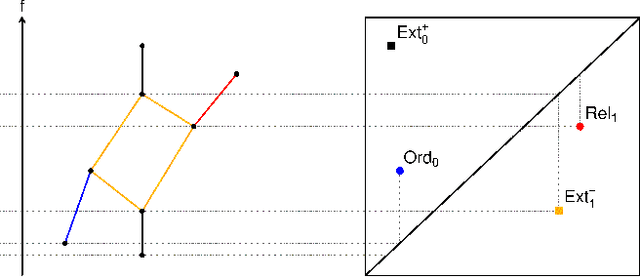
Recently many efforts have been made to incorporate persistence diagrams, one of the major tools in topological data analysis (TDA), into machine learning pipelines. To better understand the power and limitation of persistence diagrams, we carry out a range of experiments on both graph data and shape data, aiming to decouple and inspect the effects of different factors involved. To this end, we also propose the so-called \emph{permutation test} for persistence diagrams to delineate critical values and pairings of critical values. For graph classification tasks, we note that while persistence pairing yields consistent improvement over various benchmark datasets, it appears that for various filtration functions tested, most discriminative power comes from critical values. For shape segmentation and classification, however, we note that persistence pairing shows significant power on most of the benchmark datasets, and improves over both summaries based on merely critical values, and those based on permutation tests. Our results help provide insights on when persistence diagram based summaries could be more suitable.
Group Representation Theory for Knowledge Graph Embedding
Sep 11, 2019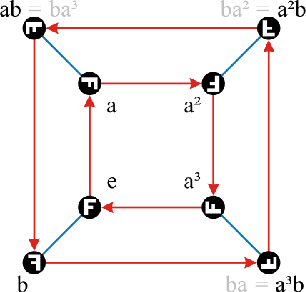

Knowledge graph embedding has recently become a popular way to model relations and infer missing links. In this paper, we present a group theoretical perspective of knowledge graph embedding, connecting previous methods with different group actions. Furthermore, by utilizing Schur's lemma from group representation theory, we show that the state of the art embedding method RotatE can model relations from any finite Abelian group.