 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyber Deception for Mission Surveillance via Hypergame-Theoretic Deep Reinforcement Learning
Mar 21, 2026Unmanned Aerial Vehicles (UAVs) are valuable for mission-critical systems like surveillance, rescue, or delivery. Not surprisingly, such systems attract cyberattacks, including Denial-of-Service (DoS) attacks to overwhelm the resources of mission drones (MDs). How can we defend UAV mission systems against DoS attacks? We adopt cyber deception as a defense strategy, in which honey drones (HDs) are proposed to bait and divert attacks. The attack and deceptive defense hinge upon radio signal strength: The attacker selects victim MDs based on their signals, and HDs attract the attacker from afar by emitting stronger signals, despite this reducing battery life. We formulate an optimization problem for the attacker and defender to identify their respective strategies for maximizing mission performance while minimizing energy consumption. To address this problem, we propose a novel approach, called HT-DRL. HT-DRL identifies optimal solutions without a long learning convergence time by taking the solutions of hypergame theory into the neural network of deep reinforcement learning. This achieves a systematic way to intelligently deceive attackers. We analyze the performance of diverse defense mechanisms under different attack strategies. Further, the HT-DRL-based HD approach outperforms existing non-HD counterparts up to two times better in mission performance while incurring low energy consumption.
Decision Theory-Guided Deep Reinforcement Learning for Fast Learning
Feb 08, 2024



This paper introduces a novel approach, Decision Theory-guided Deep Reinforcement Learning (DT-guided DRL), to address the inherent cold start problem in DRL. By integrating decision theory principles, DT-guided DRL enhances agents' initial performance and robustness in complex environments, enabling more efficient and reliable convergence during learning. Our investigation encompasses two primary problem contexts: the cart pole and maze navigation challenges. Experimental results demonstrate that the integration of decision theory not only facilitates effective initial guidance for DRL agents but also promotes a more structured and informed exploration strategy, particularly in environments characterized by large and intricate state spaces. The results of experiment demonstrate that DT-guided DRL can provide significantly higher rewards compared to regular DRL. Specifically, during the initial phase of training, the DT-guided DRL yields up to an 184% increase in accumulated reward. Moreover, even after reaching convergence, it maintains a superior performance, ending with up to 53% more reward than standard DRL in large maze problems. DT-guided DRL represents an advancement in mitigating a fundamental challenge of DRL by leveraging functions informed by human (designer) knowledge, setting a foundation for further research in this promising interdisciplinary domain.
Game-Theoretic and Machine Learning-based Approaches for Defensive Deception: A Survey
Jan 21, 2021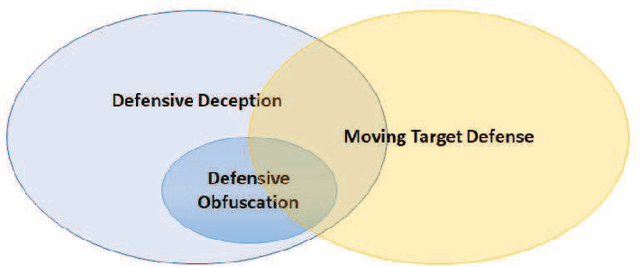
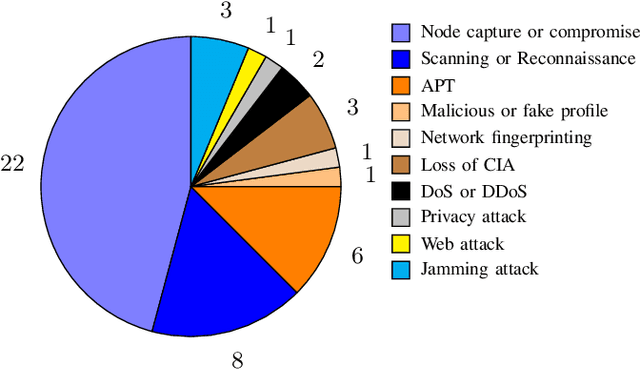
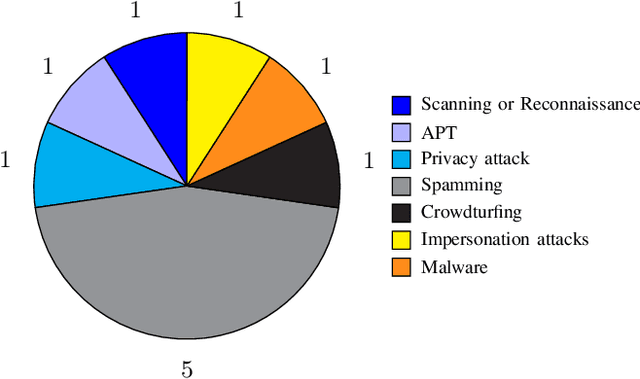
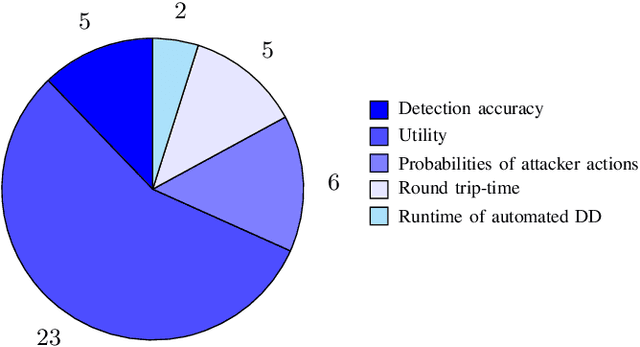
Defensive deception is a promising approach for cyberdefense. Although defensive deception is increasingly popular in the research community, there has not been a systematic investigation of its key components, the underlying principles, and its tradeoffs in various problem settings. This survey paper focuses on defensive deception research centered on game theory and machine learning, since these are prominent families of artificial intelligence approaches that are widely employed in defensive deception. This paper brings forth insights, lessons, and limitations from prior work. It closes with an outline of some research directions to tackle major gaps in current defensive deception research.