 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage as a Principle for Discovering Transferable Behavior in Reinforcement Learning
Feb 24, 2021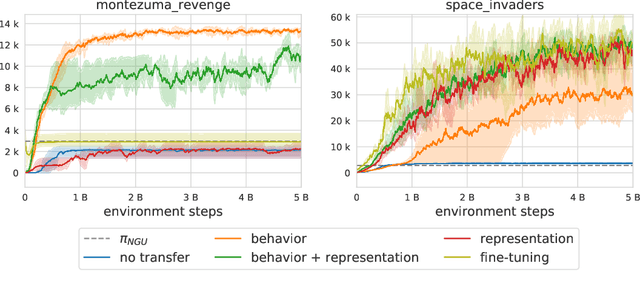
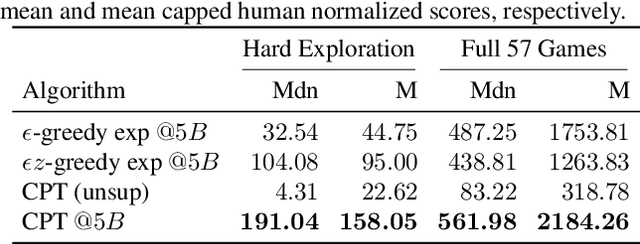
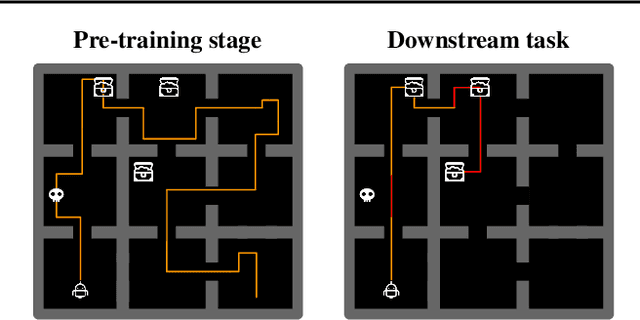
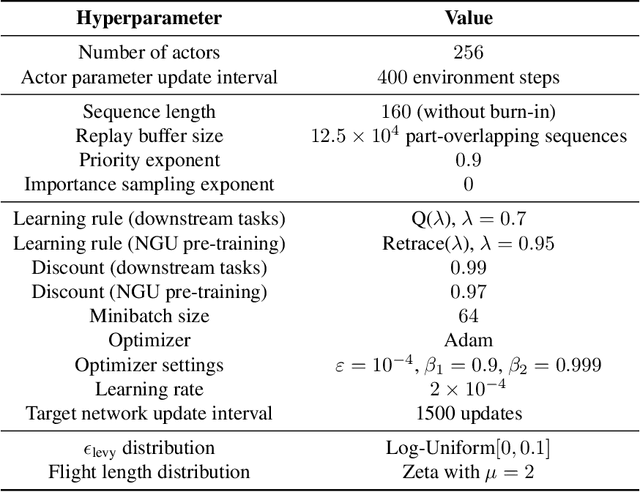
Designing agents that acquire knowledge autonomously and use it to solve new tasks efficiently is an important challenge in reinforcement learning, and unsupervised learning provides a useful paradigm for autonomous acquisition of task-agnostic knowledge. In supervised settings, representations discovered through unsupervised pre-training offer important benefits when transferred to downstream tasks. Given the nature of the reinforcement learning problem, we argue that representation alone is not enough for efficient transfer in challenging domains and explore how to transfer knowledge through behavior. The behavior of pre-trained policies may be used for solving the task at hand (exploitation), as well as for collecting useful data to solve the problem (exploration). We argue that policies pre-trained to maximize coverage will produce behavior that is useful for both strategies. When using these policies for both exploitation and exploration, our agents discover better solutions. The largest gains are generally observed in domains requiring structured exploration, including settings where the behavior of the pre-trained policies is misaligned with the downstream task.
Representation Learning via Invariant Causal Mechanisms
Oct 15, 2020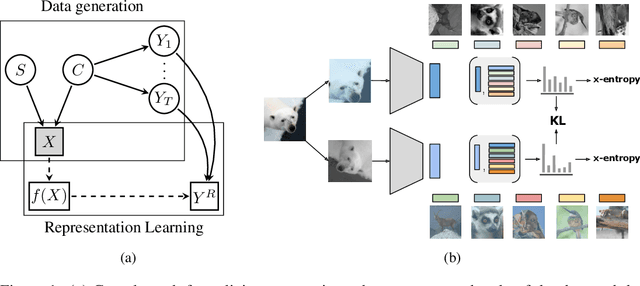
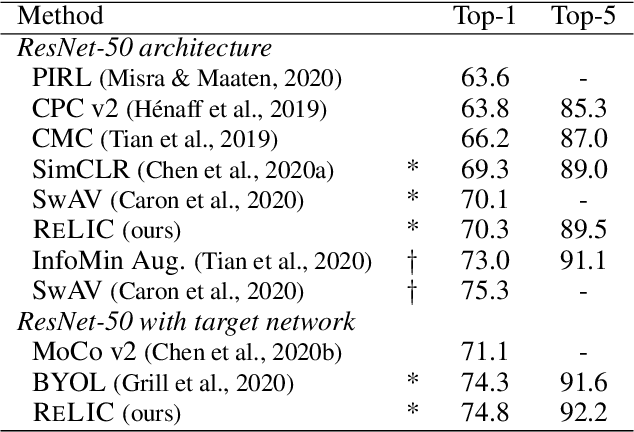
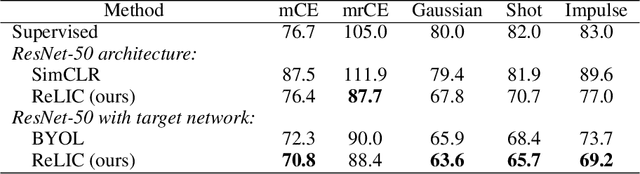
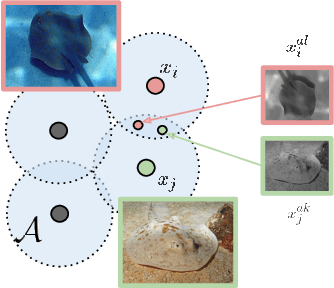
Self-supervised learning has emerged as a strategy to reduce the reliance on costly supervised signal by pretraining representations only using unlabeled data. These methods combine heuristic proxy classification tasks with data augmentations and have achieved significant success, but our theoretical understanding of this success remains limited. In this paper we analyze self-supervised representation learning using a causal framework. We show how data augmentations can be more effectively utilized through explicit invariance constraints on the proxy classifiers employed during pretraining. Based on this, we propose a novel self-supervised objective, Representation Learning via Invariant Causal Mechanisms (ReLIC), that enforces invariant prediction of proxy targets across augmentations through an invariance regularizer which yields improved generalization guarantees. Further, using causality we generalize contrastive learning, a particular kind of self-supervised method, and provide an alternative theoretical explanation for the success of these methods. Empirically, ReLIC significantly outperforms competing methods in terms of robustness and out-of-distribution generalization on ImageNet, while also significantly outperforming these methods on Atari achieving above human-level performance on $51$ out of $57$ games.
Object Files and Schemata: Factorizing Declarative and Procedural Knowledge in Dynamical Systems
Jun 30, 2020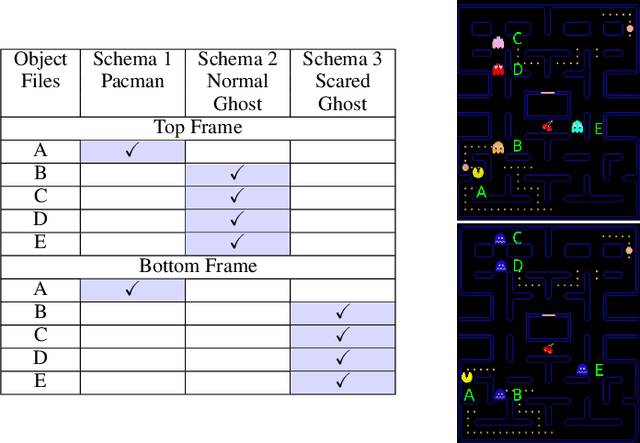
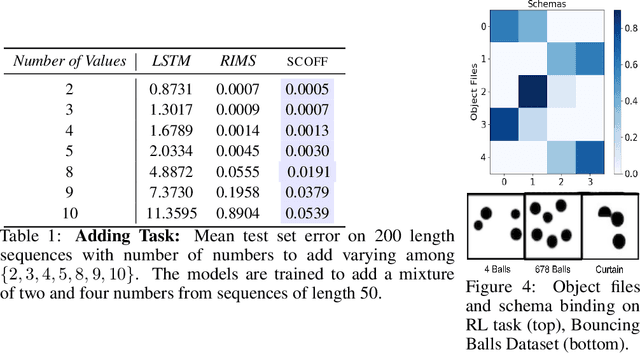
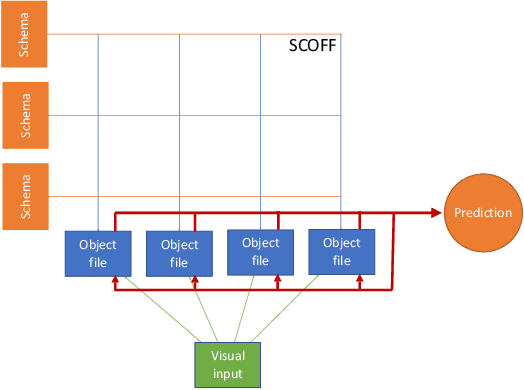

Modeling a structured, dynamic environment like a video game requires keeping track of the objects and their states (\emph{declarative} knowledge) as well as predicting how objects behave (\emph{procedural} knowledge). Black-box models with a monolithic hidden state often lack \emph{systematicity}: they fail to apply procedural knowledge consistently and uniformly. For example, in a video game, correct prediction of one enemy's trajectory does not ensure correct prediction of another's. We address this issue via an architecture that factorizes declarative and procedural knowledge and that imposes modularity within each form of knowledge. The architecture consists of active modules called \emph{object files} that maintain the state of a single object and invoke passive external knowledge sources called \emph{schemata} that prescribe state updates. To use a video game as an illustration, two enemies of the same type will share schemata but will each have their own object file to encode their distinct state (e.g., health, position). We propose to use attention to control the determination of which object files to update, the selection of schemata, and the propagation of information between object files. The resulting architecture is a drop-in replacement conforming to the same input-output interface as normal recurrent networks (e.g., LSTM, GRU) yet achieves substantially better generalization on environments that have factorized declarative and procedural knowledge, including a challenging intuitive physics benchmark.
Pointer Graph Networks
Jun 11, 2020


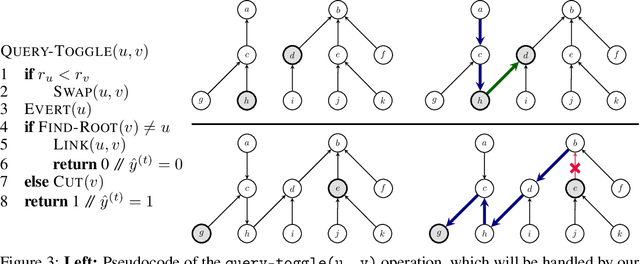
Graph neural networks (GNNs) are typically applied to static graphs that are assumed to be known upfront. This static input structure is often informed purely by insight of the machine learning practitioner, and might not be optimal for the actual task the GNN is solving. In absence of reliable domain expertise, one might resort to inferring the latent graph structure, which is often difficult due to the vast search space of possible graphs. Here we introduce Pointer Graph Networks (PGNs) which augment sets or graphs with additional inferred edges for improved model expressivity. PGNs allow each node to dynamically point to another node, followed by message passing over these pointers. The sparsity of this adaptable graph structure makes learning tractable while still being sufficiently expressive to simulate complex algorithms. Critically, the pointing mechanism is directly supervised to model long-term sequences of operations on classical data structures, incorporating useful structural inductive biases from theoretical computer science. Qualitatively, we demonstrate that PGNs can learn parallelisable variants of pointer-based data structures, namely disjoint set unions and link/cut trees. PGNs generalise out-of-distribution to 5x larger test inputs on dynamic graph connectivity tasks, outperforming unrestricted GNNs and Deep Sets.
Agent57: Outperforming the Atari Human Benchmark
Mar 30, 2020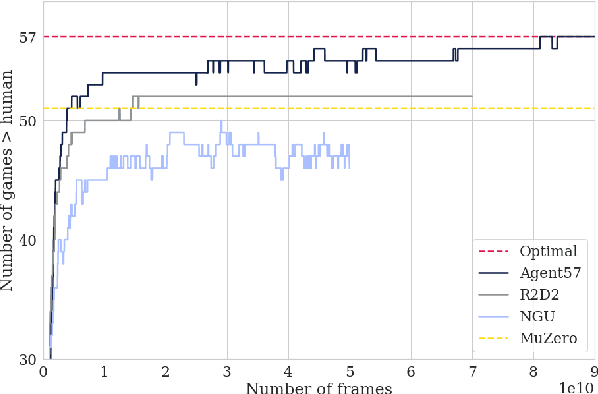
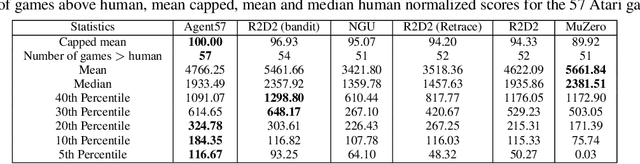
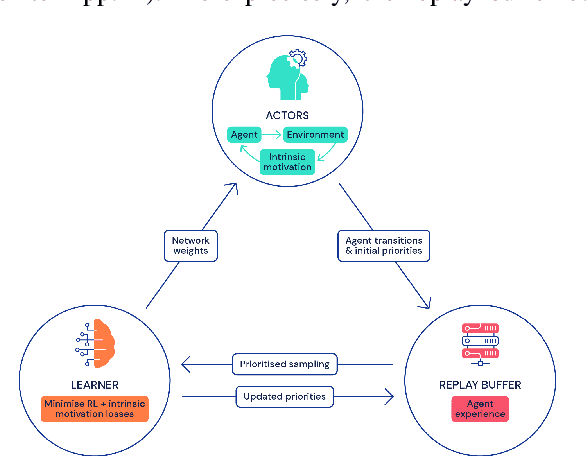

Atari games have been a long-standing benchmark in the reinforcement learning (RL) community for the past decade. This benchmark was proposed to test general competency of RL algorithms. Previous work has achieved good average performance by doing outstandingly well on many games of the set, but very poorly in several of the most challenging games. We propose Agent57, the first deep RL agent that outperforms the standard human benchmark on all 57 Atari games. To achieve this result, we train a neural network which parameterizes a family of policies ranging from very exploratory to purely exploitative. We propose an adaptive mechanism to choose which policy to prioritize throughout the training process. Additionally, we utilize a novel parameterization of the architecture that allows for more consistent and stable learning.
Never Give Up: Learning Directed Exploration Strategies
Feb 14, 2020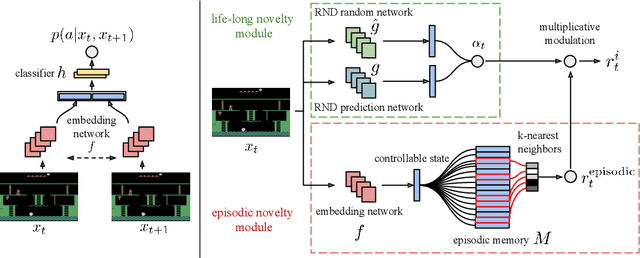
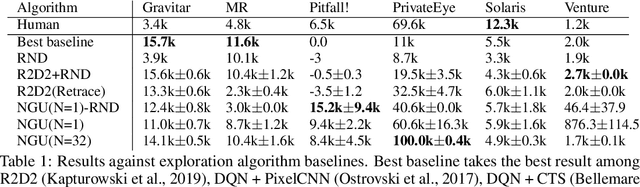
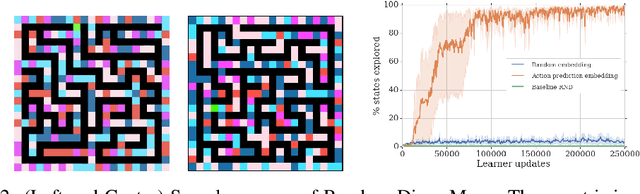
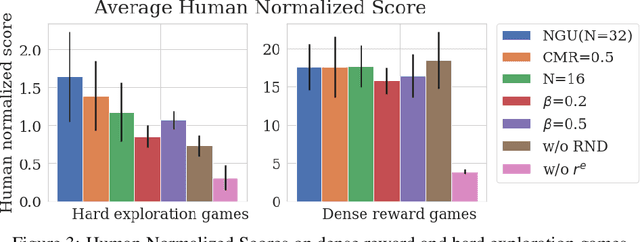
We propose a reinforcement learning agent to solve hard exploration games by learning a range of directed exploratory policies. We construct an episodic memory-based intrinsic reward using k-nearest neighbors over the agent's recent experience to train the directed exploratory policies, thereby encouraging the agent to repeatedly revisit all states in its environment. A self-supervised inverse dynamics model is used to train the embeddings of the nearest neighbour lookup, biasing the novelty signal towards what the agent can control. We employ the framework of Universal Value Function Approximators (UVFA) to simultaneously learn many directed exploration policies with the same neural network, with different trade-offs between exploration and exploitation. By using the same neural network for different degrees of exploration/exploitation, transfer is demonstrated from predominantly exploratory policies yielding effective exploitative policies. The proposed method can be incorporated to run with modern distributed RL agents that collect large amounts of experience from many actors running in parallel on separate environment instances. Our method doubles the performance of the base agent in all hard exploration in the Atari-57 suite while maintaining a very high score across the remaining games, obtaining a median human normalised score of 1344.0%. Notably, the proposed method is the first algorithm to achieve non-zero rewards (with a mean score of 8,400) in the game of Pitfall! without using demonstrations or hand-crafted features.
Targeted free energy estimation via learned mappings
Feb 12, 2020
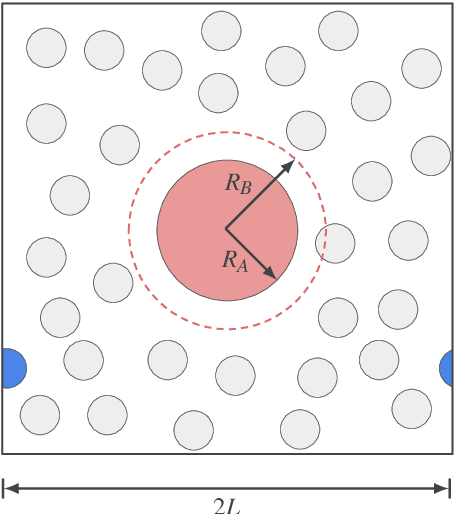
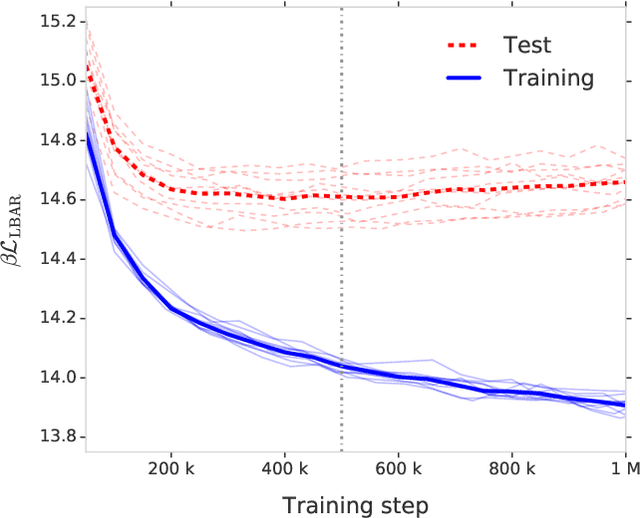
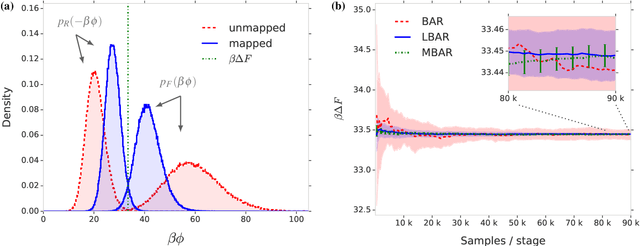
Free energy perturbation (FEP) was proposed by Zwanzig more than six decades ago as a method to estimate free energy differences, and has since inspired a huge body of related methods that use it as an integral building block. Being an importance sampling based estimator, however, FEP suffers from a severe limitation: the requirement of sufficient overlap between distributions. One strategy to mitigate this problem, called Targeted Free Energy Perturbation, uses a high-dimensional mapping in configuration space to increase overlap of the underlying distributions. Despite its potential, this method has attracted only limited attention due to the formidable challenge of formulating a tractable mapping. Here, we cast Targeted FEP as a machine learning (ML) problem in which the mapping is parameterized as a neural network that is optimized so as to increase overlap. We test our method on a fully-periodic solvation system, with a model that respects the inherent permutational and periodic symmetries of the problem. We demonstrate that our method leads to a substantial variance reduction in free energy estimates when compared against baselines.
MEMO: A Deep Network for Flexible Combination of Episodic Memories
Jan 29, 2020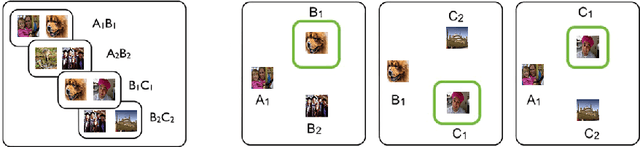
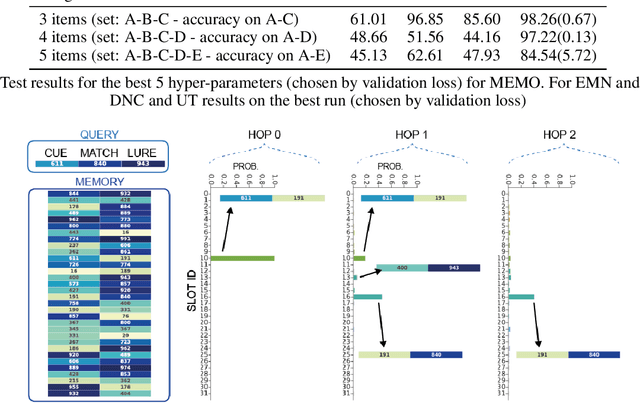
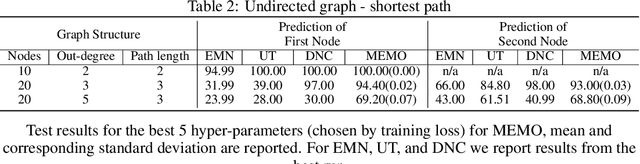

Recent research developing neural network architectures with external memory have often used the benchmark bAbI question and answering dataset which provides a challenging number of tasks requiring reasoning. Here we employed a classic associative inference task from the memory-based reasoning neuroscience literature in order to more carefully probe the reasoning capacity of existing memory-augmented architectures. This task is thought to capture the essence of reasoning -- the appreciation of distant relationships among elements distributed across multiple facts or memories. Surprisingly, we found that current architectures struggle to reason over long distance associations. Similar results were obtained on a more complex task involving finding the shortest path between nodes in a path. We therefore developed MEMO, an architecture endowed with the capacity to reason over longer distances. This was accomplished with the addition of two novel components. First, it introduces a separation between memories (facts) stored in external memory and the items that comprise these facts in external memory. Second, it makes use of an adaptive retrieval mechanism, allowing a variable number of "memory hops" before the answer is produced. MEMO is capable of solving our novel reasoning tasks, as well as match state of the art results in bAbI.
Shaping representations through communication: community size effect in artificial learning systems
Dec 12, 2019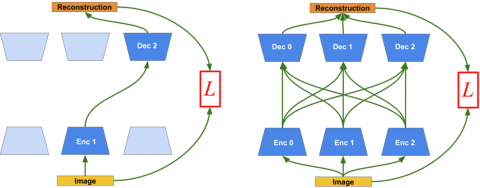
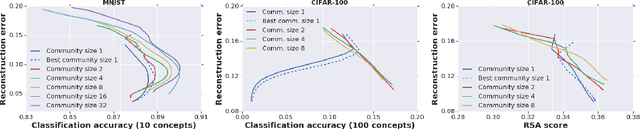
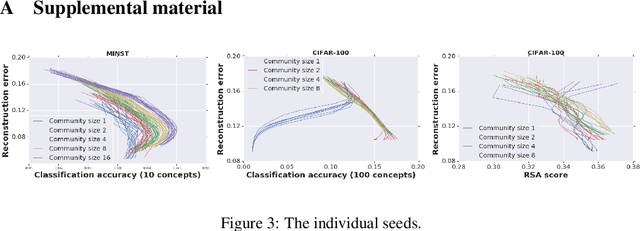
Motivated by theories of language and communication that explain why communities with large numbers of speakers have, on average, simpler languages with more regularity, we cast the representation learning problem in terms of learning to communicate. Our starting point sees the traditional autoencoder setup as a single encoder with a fixed decoder partner that must learn to communicate. Generalizing from there, we introduce community-based autoencoders in which multiple encoders and decoders collectively learn representations by being randomly paired up on successive training iterations. We find that increasing community sizes reduce idiosyncrasies in the learned codes, resulting in representations that better encode concept categories and correlate with human feature norms.
Generalization of Reinforcement Learners with Working and Episodic Memory
Oct 29, 2019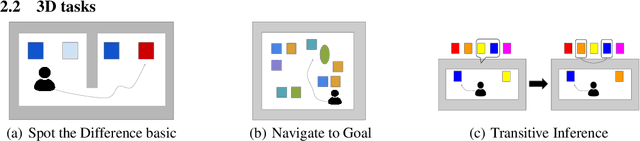
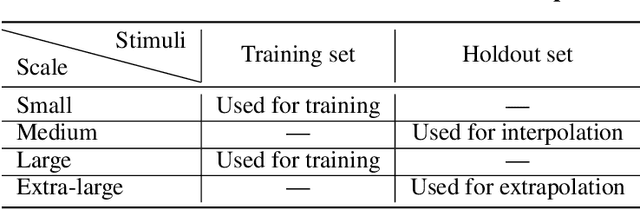
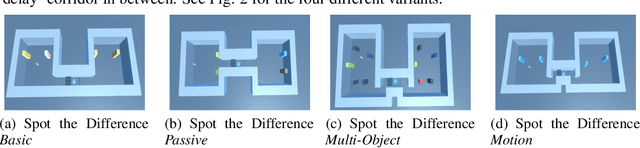
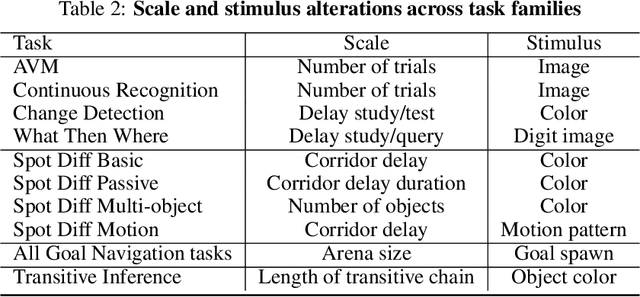
Memory is an important aspect of intelligence and plays a role in many deep reinforcement learning models. However, little progress has been made in understanding when specific memory systems help more than others and how well they generalize. The field also has yet to see a prevalent consistent and rigorous approach for evaluating agent performance on holdout data. In this paper, we aim to develop a comprehensive methodology to test different kinds of memory in an agent and assess how well the agent can apply what it learns in training to a holdout set that differs from the training set along dimensions that we suggest are relevant for evaluating memory-specific generalization. To that end, we first construct a diverse set of memory tasks that allow us to evaluate test-time generalization across multiple dimensions. Second, we develop and perform multiple ablations on an agent architecture that combines multiple memory systems, observe its baseline models, and investigate its performance against the task suite.