 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Benchmarks: Continuous Edge Inference for Fine-Grained Roadside Perception
Jun 15, 2026Continuous AI inference on resource-constrained edge hardware introduces deployment effects that are largely invisible to conventional benchmark evaluation, including temporal instability in streaming video, thermal throttling under sustained load, and workload-dependent performance variability. We present Edge-TSR, a deployment-oriented continuous edge inference system for sustained roadside perception on the NVIDIA Jetson Orin Nano. Edge-TSR integrates detection, tracking, fine-grained classification, and a lightweight track-aware temporal stabilization mechanism that improves streaming inference consistency with negligible computational overhead. Our central finding is that benchmark-centric evaluation systematically overstates deployed edge inference performance. Across three state-of-the-art baselines, we observe consistent 20-30% relative degradation when transitioning from static-image evaluation to real-world streaming deployment. Edge-TSR addresses this gap through temporal inference stabilization, recovering up to 10.16% classification accuracy over per-frame inference baselines while maintaining sustained real-time performance under continuous operation. We evaluate the complete system under diverse real-world deployment conditions, jointly characterizing inference quality, latency, throughput, and thermal behavior during long-duration operation. A 55-minute vehicular deployment over a 26 km route demonstrates sustained operation at 16.18 FPS within safe thermal limits on a single embedded device without cloud offload. Our findings show that deployment-aware evaluation and temporal inference stabilization are necessary components of continuously operating edge AI systems intended for real-world sensing deployments. We release a sample annotated streaming video evaluation dataset and full system implementation to support reproducible deployment-centric evaluation.
A Tensor-Based Compiler and a Runtime for Neuron-Level DNN Certifier Specifications
Jul 26, 2025



The uninterpretability of DNNs has led to the adoption of abstract interpretation-based certification as a practical means to establish trust in real-world systems that rely on DNNs. However, the current landscape supports only a limited set of certifiers, and developing new ones or modifying existing ones for different applications remains difficult. This is because the mathematical design of certifiers is expressed at the neuron level, while their implementations are optimized and executed at the tensor level. This mismatch creates a semantic gap between design and implementation, making manual bridging both complex and expertise-intensive -- requiring deep knowledge in formal methods, high-performance computing, etc. We propose a compiler framework that automatically translates neuron-level specifications of DNN certifiers into tensor-based, layer-level implementations. This is enabled by two key innovations: a novel stack-based intermediate representation (IR) and a shape analysis that infers the implicit tensor operations needed to simulate the neuron-level semantics. During lifting, the shape analysis creates tensors in the minimal shape required to perform the corresponding operations. The IR also enables domain-specific optimizations as rewrites. At runtime, the resulting tensor computations exhibit sparsity tied to the DNN architecture. This sparsity does not align well with existing formats. To address this, we introduce g-BCSR, a double-compression format that represents tensors as collections of blocks of varying sizes, each possibly internally sparse. Using our compiler and g-BCSR, we make it easy to develop new certifiers and analyze their utility across diverse DNNs. Despite its flexibility, the compiler achieves performance comparable to hand-optimized implementations.
RiM: Record, Improve and Maintain Physical Well-being using Federated Learning
May 09, 2025In academic settings, the demanding environment often forces students to prioritize academic performance over their physical well-being. Moreover, privacy concerns and the inherent risk of data breaches hinder the deployment of traditional machine learning techniques for addressing these health challenges. In this study, we introduce RiM: Record, Improve, and Maintain, a mobile application which incorporates a novel personalized machine learning framework that leverages federated learning to enhance students' physical well-being by analyzing their lifestyle habits. Our approach involves pre-training a multilayer perceptron (MLP) model on a large-scale simulated dataset to generate personalized recommendations. Subsequently, we employ federated learning to fine-tune the model using data from IISER Bhopal students, thereby ensuring its applicability in real-world scenarios. The federated learning approach guarantees differential privacy by exclusively sharing model weights rather than raw data. Experimental results show that the FedAvg-based RiM model achieves an average accuracy of 60.71% and a mean absolute error of 0.91--outperforming the FedPer variant (average accuracy 46.34%, MAE 1.19)--thereby demonstrating its efficacy in predicting lifestyle deficits under privacy-preserving constraints.
Patent Novelty Assessment Accelerating Innovation and Patent Prosecution
Jan 12, 2025


In the rapidly evolving landscape of technological innovation, safeguarding intellectual property rights through patents is crucial for fostering progress and stimulating research and development investments. This report introduces a ground-breaking Patent Novelty Assessment and Claim Generation System, meticulously crafted to dissect the inventive aspects of intellectual property and simplify access to extensive patent claim data. Addressing a crucial gap in academic institutions, our system provides college students and researchers with an intuitive platform to navigate and grasp the intricacies of patent claims, particularly tailored for the nuances of Chinese patents. Unlike conventional analysis systems, our initiative harnesses a proprietary Chinese API to ensure unparalleled precision and relevance. The primary challenge lies in the complexity of accessing and comprehending diverse patent claims, inhibiting effective innovation upon existing ideas. Our solution aims to overcome these barriers by offering a bespoke approach that seamlessly retrieves comprehensive claim information, finely tuned to the specifics of the Chinese patent landscape. By equipping users with efficient access to comprehensive patent claim information, our transformative platform seeks to ignite informed exploration and innovation in the ever-evolving domain of intellectual property. Its envisioned impact transcends individual colleges, nurturing an environment conducive to research and development while deepening the understanding of patented concepts within the academic community.
Towards Infusing Auxiliary Knowledge for Distracted Driver Detection
Aug 29, 2024



Distracted driving is a leading cause of road accidents globally. Identification of distracted driving involves reliably detecting and classifying various forms of driver distraction (e.g., texting, eating, or using in-car devices) from in-vehicle camera feeds to enhance road safety. This task is challenging due to the need for robust models that can generalize to a diverse set of driver behaviors without requiring extensive annotated datasets. In this paper, we propose KiD3, a novel method for distracted driver detection (DDD) by infusing auxiliary knowledge about semantic relations between entities in a scene and the structural configuration of the driver's pose. Specifically, we construct a unified framework that integrates the scene graphs, and driver pose information with the visual cues in video frames to create a holistic representation of the driver's actions.Our results indicate that KiD3 achieves a 13.64% accuracy improvement over the vision-only baseline by incorporating such auxiliary knowledge with visual information.
DECODE: Data-driven Energy Consumption Prediction leveraging Historical Data and Environmental Factors in Buildings
Sep 06, 2023



Energy prediction in buildings plays a crucial role in effective energy management. Precise predictions are essential for achieving optimal energy consumption and distribution within the grid. This paper introduces a Long Short-Term Memory (LSTM) model designed to forecast building energy consumption using historical energy data, occupancy patterns, and weather conditions. The LSTM model provides accurate short, medium, and long-term energy predictions for residential and commercial buildings compared to existing prediction models. We compare our LSTM model with established prediction methods, including linear regression, decision trees, and random forest. Encouragingly, the proposed LSTM model emerges as the superior performer across all metrics. It demonstrates exceptional prediction accuracy, boasting the highest R2 score of 0.97 and the most favorable mean absolute error (MAE) of 0.007. An additional advantage of our developed model is its capacity to achieve efficient energy consumption forecasts even when trained on a limited dataset. We address concerns about overfitting (variance) and underfitting (bias) through rigorous training and evaluation on real-world data. In summary, our research contributes to energy prediction by offering a robust LSTM model that outperforms alternative methods and operates with remarkable efficiency, generalizability, and reliability.
Using LSTM for the Prediction of Disruption in ADITYA Tokamak
Jul 13, 2020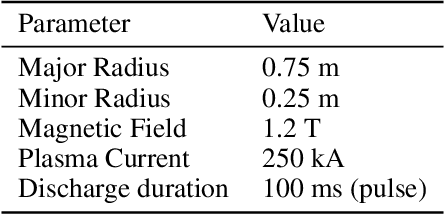
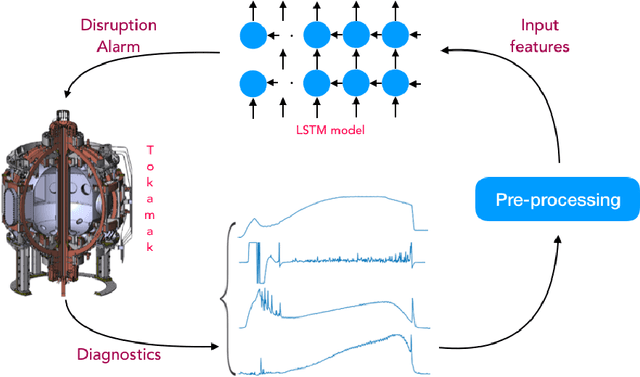
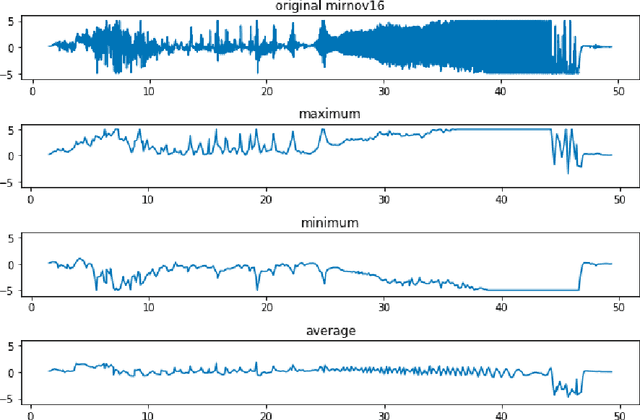
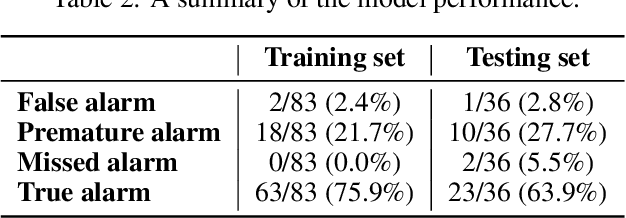
Major disruptions in tokamak pose a serious threat to the vessel and its surrounding pieces of equipment. The ability of the systems to detect any behavior that can lead to disruption can help in alerting the system beforehand and prevent its harmful effects. Many machine learning techniques have already been in use at large tokamaks like JET and ASDEX, but are not suitable for ADITYA, which is comparatively small. Through this work, we discuss a new real-time approach to predict the time of disruption in ADITYA tokamak and validate the results on an experimental dataset. The system uses selected diagnostics from the tokamak and after some pre-processing steps, sends them to a time-sequence Long Short-Term Memory (LSTM) network. The model can make the predictions 12 ms in advance at less computation cost that is quick enough to be deployed in real-time applications.