 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRCL: Probabilistic Representation Contrastive Learning for Semi-Supervised Semantic Segmentation
Feb 28, 2024



Tremendous breakthroughs have been developed in Semi-Supervised Semantic Segmentation (S4) through contrastive learning. However, due to limited annotations, the guidance on unlabeled images is generated by the model itself, which inevitably exists noise and disturbs the unsupervised training process. To address this issue, we propose a robust contrastive-based S4 framework, termed the Probabilistic Representation Contrastive Learning (PRCL) framework to enhance the robustness of the unsupervised training process. We model the pixel-wise representation as Probabilistic Representations (PR) via multivariate Gaussian distribution and tune the contribution of the ambiguous representations to tolerate the risk of inaccurate guidance in contrastive learning. Furthermore, we introduce Global Distribution Prototypes (GDP) by gathering all PRs throughout the whole training process. Since the GDP contains the information of all representations with the same class, it is robust from the instant noise in representations and bears the intra-class variance of representations. In addition, we generate Virtual Negatives (VNs) based on GDP to involve the contrastive learning process. Extensive experiments on two public benchmarks demonstrate the superiority of our PRCL framework.
Space Engage: Collaborative Space Supervision for Contrastive-based Semi-Supervised Semantic Segmentation
Jul 19, 2023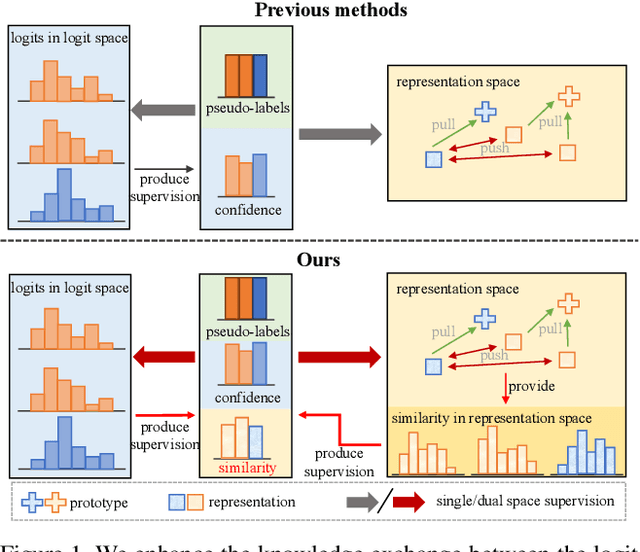



Semi-Supervised Semantic Segmentation (S4) aims to train a segmentation model with limited labeled images and a substantial volume of unlabeled images. To improve the robustness of representations, powerful methods introduce a pixel-wise contrastive learning approach in latent space (i.e., representation space) that aggregates the representations to their prototypes in a fully supervised manner. However, previous contrastive-based S4 methods merely rely on the supervision from the model's output (logits) in logit space during unlabeled training. In contrast, we utilize the outputs in both logit space and representation space to obtain supervision in a collaborative way. The supervision from two spaces plays two roles: 1) reduces the risk of over-fitting to incorrect semantic information in logits with the help of representations; 2) enhances the knowledge exchange between the two spaces. Furthermore, unlike previous approaches, we use the similarity between representations and prototypes as a new indicator to tilt training those under-performing representations and achieve a more efficient contrastive learning process. Results on two public benchmarks demonstrate the competitive performance of our method compared with state-of-the-art methods.
Boosting Semi-Supervised Semantic Segmentation with Probabilistic Representations
Oct 26, 2022



Recent breakthroughs in semi-supervised semantic segmentation have been developed through contrastive learning. In prevalent pixel-wise contrastive learning solutions, the model maps pixels to deterministic representations and regularizes them in the latent space. However, there exist inaccurate pseudo-labels which map the ambiguous representations of pixels to the wrong classes due to the limited cognitive ability of the model. In this paper, we define pixel-wise representations from a new perspective of probability theory and propose a Probabilistic Representation Contrastive Learning (PRCL) framework that improves representation quality by taking its probability into consideration. Through modeling the mapping from pixels to representations as the probability via multivariate Gaussian distributions, we can tune the contribution of the ambiguous representations to tolerate the risk of inaccurate pseudo-labels. Furthermore, we define prototypes in the form of distributions, which indicates the confidence of a class, while the point prototype cannot. Moreover, we propose to regularize the distribution variance to enhance the reliability of representations. Taking advantage of these benefits, high-quality feature representations can be derived in the latent space, thereby the performance of semantic segmentation can be further improved. We conduct sufficient experiment to evaluate PRCL on Pascal VOC and CityScapes. The comparisons with state-of-the-art approaches demonstrate the superiority of proposed PRCL.