 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-DAUG: Generative Data Augmentation for Commonsense Reasoning
Apr 24, 2020
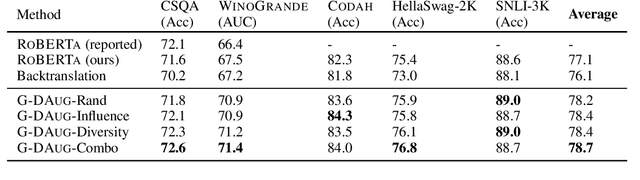
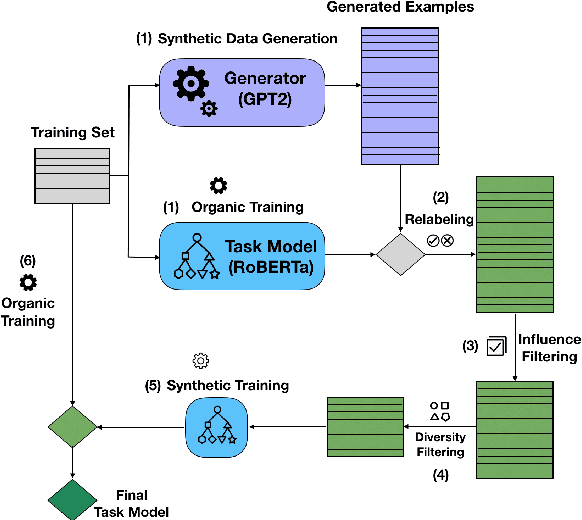
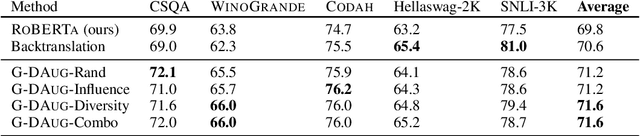
Recent advances in commonsense reasoning depend on large-scale human-annotated training data to achieve peak performance. However, manual curation of training examples is expensive and has been shown to introduce annotation artifacts that neural models can readily exploit and overfit on. We investigate G-DAUG, a novel generative data augmentation method that aims to achieve more accurate and robust learning in the low-resource setting. Our approach generates synthetic examples using pretrained language models, and selects the most informative and diverse set of examples for data augmentation. In experiments with multiple commonsense reasoning benchmarks, G-DAUG consistently outperforms existing data augmentation methods based on back-translation, and establishes a new state-of-the-art on WinoGrande, CODAH, and CommonsenseQA. Further, in addition to improvements in in-distribution accuracy, G-DAUG-augmented training also enhances out-of-distribution generalization, showing greater robustness against adversarial or perturbed examples. Our analysis demonstrates that G-DAUG produces a diverse set of fluent training examples, and that its selection and training approaches are important for performance. Our findings encourage future research toward generative data augmentation to enhance both in-distribution learning and out-of-distribution generalization.
Visual Commonsense Graphs: Reasoning about the Dynamic Context of a Still Image
Apr 22, 2020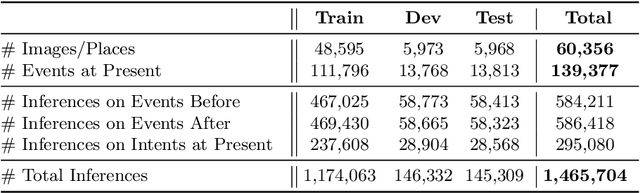
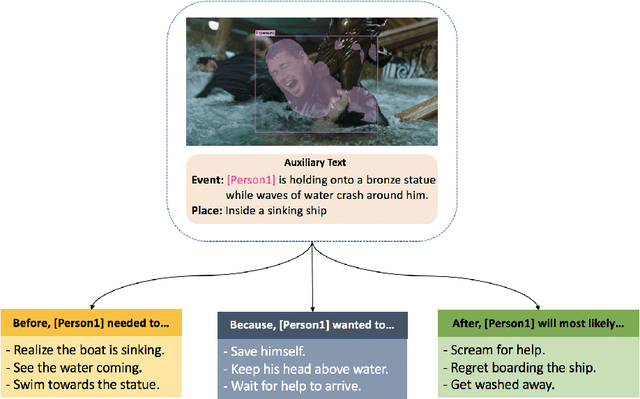
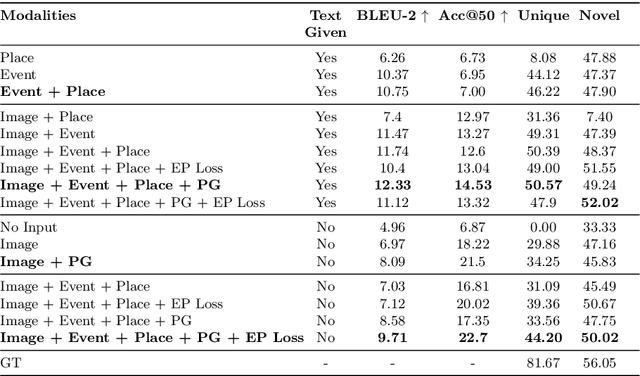

Even from a single frame of a still image, people can reason about the dynamic story of the image before, after, and beyond the frame. For example, given an image of a man struggling to stay afloat in water, we can reason that the man fell into the water sometime in the past, the intent of that man at the moment is to stay alive, and he will need help in the near future or else he will get washed away. We propose VisualComet, the novel framework of visual commonsense reasoning tasks to predict events that might have happened before, events that might happen next, and the intents of the people at present. To support research toward visual commonsense reasoning, we introduce the first large-scale repository of Visual Commonsense Graphs that consists of over 1.4 million textual descriptions of visual commonsense inferences carefully annotated over a diverse set of 60,000 images, each paired with short video summaries of before and after. In addition, we provide person-grounding (i.e., co-reference links) between people appearing in the image and people mentioned in the textual commonsense descriptions, allowing for tighter integration between images and text. We establish strong baseline performances on this task and demonstrate that integration between visual and textual commonsense reasoning is the key and wins over non-integrative alternatives.
Unsupervised Commonsense Question Answering with Self-Talk
Apr 11, 2020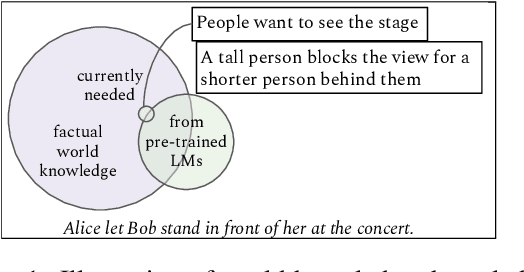

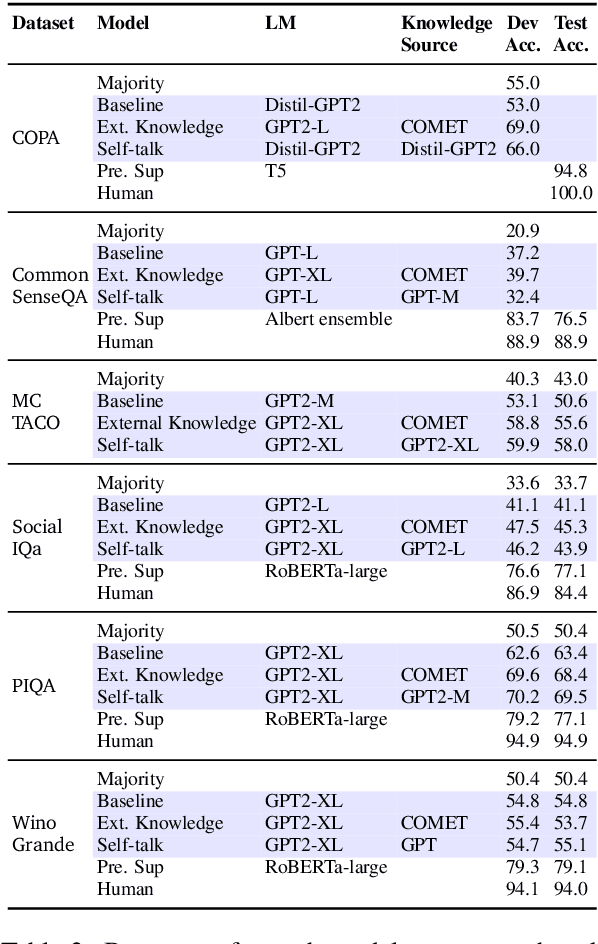
Natural language understanding involves reading between the lines with implicit background knowledge. Current systems either rely on pre-trained language models as the sole implicit source of world knowledge, or resort to external knowledge bases (KBs) to incorporate additional relevant knowledge. We propose an unsupervised framework based on \emph{self-talk} as a novel alternative to multiple-choice commonsense tasks. Inspired by inquiry-based discovery learning (Bruner, 1961), our approach inquires language models with a number of information seeking questions such as "$\textit{what is the definition of ...}$" to discover additional background knowledge. Empirical results demonstrate that the self-talk procedure substantially improves the performance of zero-shot language model baselines on four out of six commonsense benchmarks, and competes with models that obtain knowledge from external KBs. While our approach improves performance on several benchmarks, the self-talk induced knowledge even when leading to correct answers is not always seen as useful by human judges, raising interesting questions about the inner-workings of pre-trained language models for commonsense reasoning.
Adversarial Filters of Dataset Biases
Feb 20, 2020
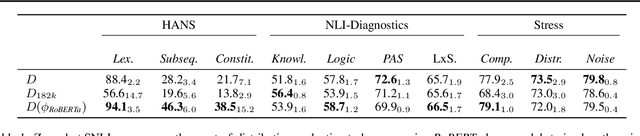

Large neural models have demonstrated human-level performance on language and vision benchmarks such as ImageNet and Stanford Natural Language Inference (SNLI). Yet, their performance degrades considerably when tested on adversarial or out-of-distribution samples. This raises the question of whether these models have learned to solve a dataset rather than the underlying task by overfitting on spurious dataset biases. We investigate one recently proposed approach, AFLite, which adversarially filters such dataset biases, as a means to mitigate the prevalent overestimation of machine performance. We provide a theoretical understanding for AFLite, by situating it in the generalized framework for optimum bias reduction. Our experiments show that as a result of the substantial reduction of these biases, models trained on the filtered datasets yield better generalization to out-of-distribution tasks, especially when the benchmarks used for training are over-populated with biased samples. We show that AFLite is broadly applicable to a variety of both real and synthetic datasets for reduction of measurable dataset biases and provide extensive supporting analyses. Finally, filtering results in a large drop in model performance (e.g., from 92% to 63% for SNLI), while human performance still remains high. Our work thus shows that such filtered datasets can pose new research challenges for robust generalization by serving as upgraded benchmarks.
Exploiting Structural and Semantic Context for Commonsense Knowledge Base Completion
Oct 07, 2019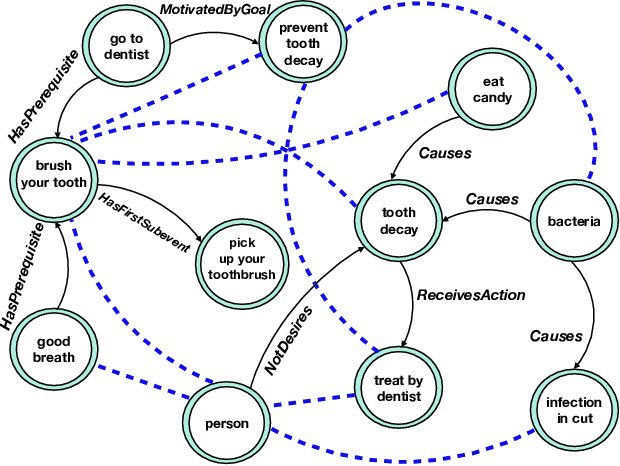

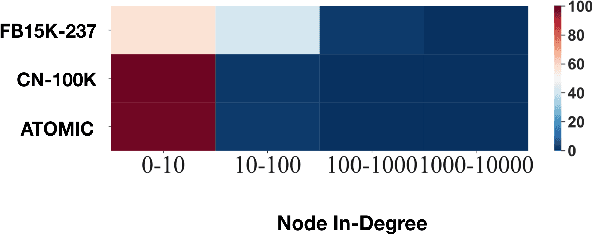
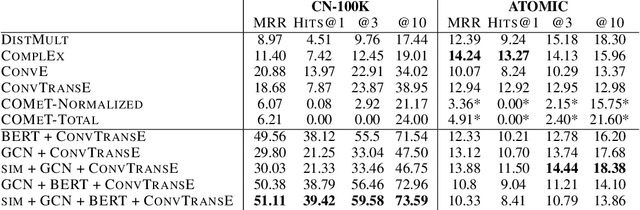
Automatic KB completion for commonsense knowledge graphs (e.g., ATOMIC and ConceptNet) poses unique challenges compared to the much studied conventional knowledge bases (e.g., Freebase). Commonsense knowledge graphs use free-form text to represent nodes, resulting in orders of magnitude more nodes compared to conventional KBs (18x more nodes in ATOMIC compared to Freebase (FB15K-237)). Importantly, this implies significantly sparser graph structures - a major challenge for existing KB completion methods that assume densely connected graphs over a relatively smaller set of nodes. In this paper, we present novel KB completion models that can address these challenges by exploiting the structural and semantic context of nodes. Specifically, we investigate two key ideas: (1) learning from local graph structure, using graph convolutional networks and automatic graph densification and (2) transfer learning from pre-trained language models to knowledge graphs for enhanced contextual representation of knowledge. We describe our method to incorporate information from both these sources in a joint model and provide the first empirical results for KB completion on ATOMIC and evaluation with ranking metrics on ConceptNet. Our results demonstrate the effectiveness of language model representations in boosting link prediction performance and the advantages of learning from local graph structure (+1.5 points in MRR for ConceptNet) when training on subgraphs for computational efficiency. Further analysis on model predictions shines light on the types of commonsense knowledge that language models capture well.
Counterfactual Story Reasoning and Generation
Sep 12, 2019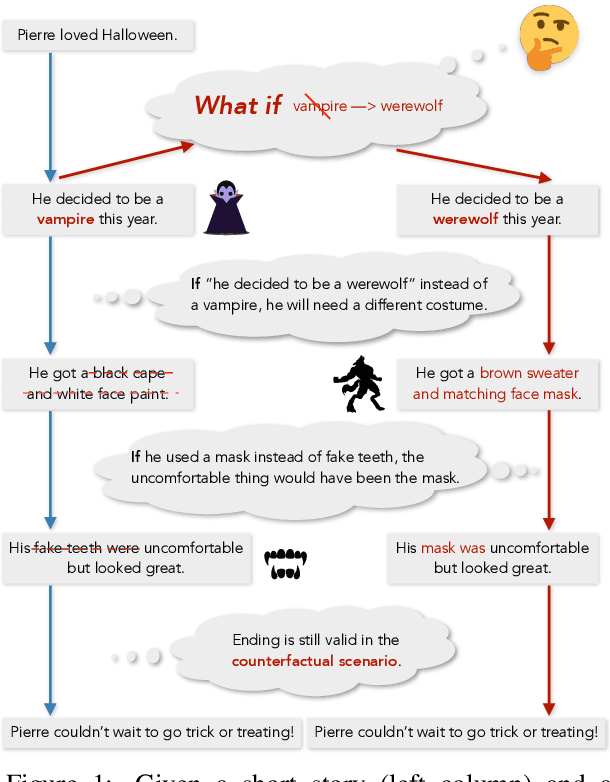


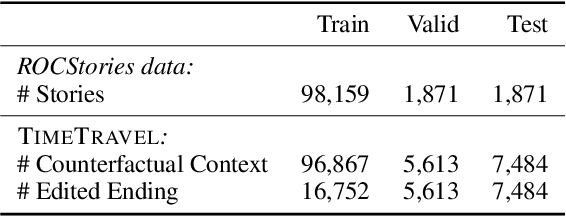
Counterfactual reasoning requires predicting how alternative events, contrary to what actually happened, might have resulted in different outcomes. Despite being considered a necessary component of AI-complete systems, few resources have been developed for evaluating counterfactual reasoning in narratives. In this paper, we propose Counterfactual Story Rewriting: given an original story and an intervening counterfactual event, the task is to minimally revise the story to make it compatible with the given counterfactual event. Solving this task will require deep understanding of causal narrative chains and counterfactual invariance, and integration of such story reasoning capabilities into conditional language generation models. We present TimeTravel, a new dataset of 29,849 counterfactual rewritings, each with the original story, a counterfactual event, and human-generated revision of the original story compatible with the counterfactual event. Additionally, we include 80,115 counterfactual "branches" without a rewritten storyline to support future work on semi- or un-supervised approaches to counterfactual story rewriting. Finally, we evaluate the counterfactual rewriting capacities of several competitive baselines based on pretrained language models, and assess whether common overlap and model-based automatic metrics for text generation correlate well with human scores for counterfactual rewriting.
Cosmos QA: Machine Reading Comprehension with Contextual Commonsense Reasoning
Sep 06, 2019
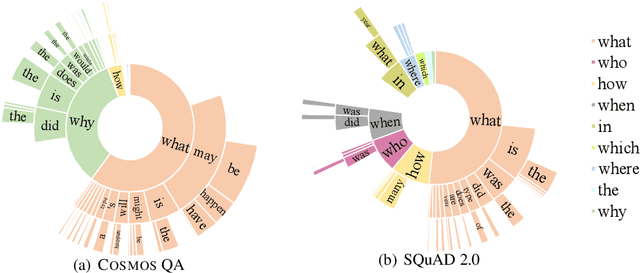
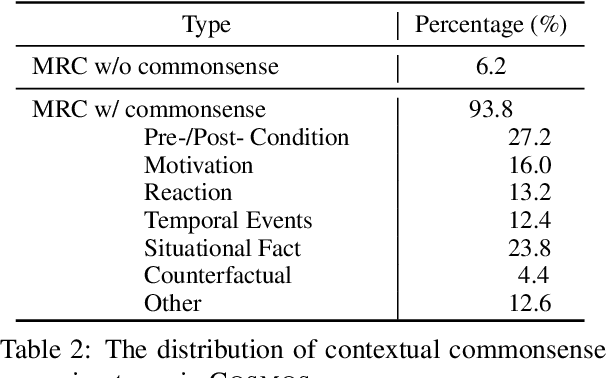
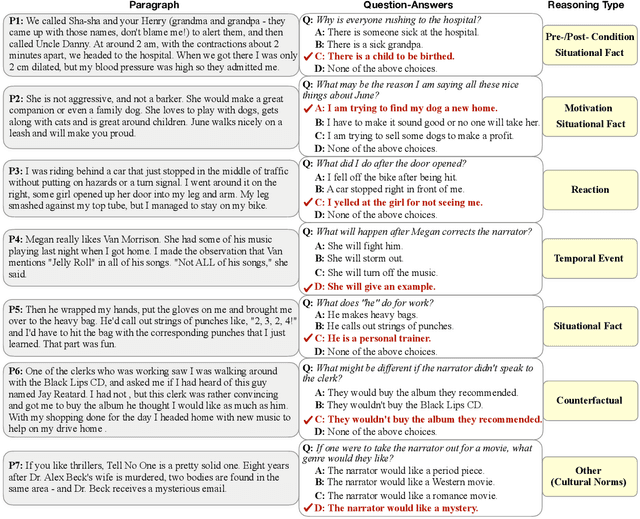
Understanding narratives requires reading between the lines, which in turn, requires interpreting the likely causes and effects of events, even when they are not mentioned explicitly. In this paper, we introduce Cosmos QA, a large-scale dataset of 35,600 problems that require commonsense-based reading comprehension, formulated as multiple-choice questions. In stark contrast to most existing reading comprehension datasets where the questions focus on factual and literal understanding of the context paragraph, our dataset focuses on reading between the lines over a diverse collection of people's everyday narratives, asking such questions as "what might be the possible reason of ...?", or "what would have happened if ..." that require reasoning beyond the exact text spans in the context. To establish baseline performances on Cosmos QA, we experiment with several state-of-the-art neural architectures for reading comprehension, and also propose a new architecture that improves over the competitive baselines. Experimental results demonstrate a significant gap between machine (68.4%) and human performance (94%), pointing to avenues for future research on commonsense machine comprehension. Dataset, code and leaderboard is publicly available at https://wilburone.github.io/cosmos.
Abductive Commonsense Reasoning
Aug 15, 2019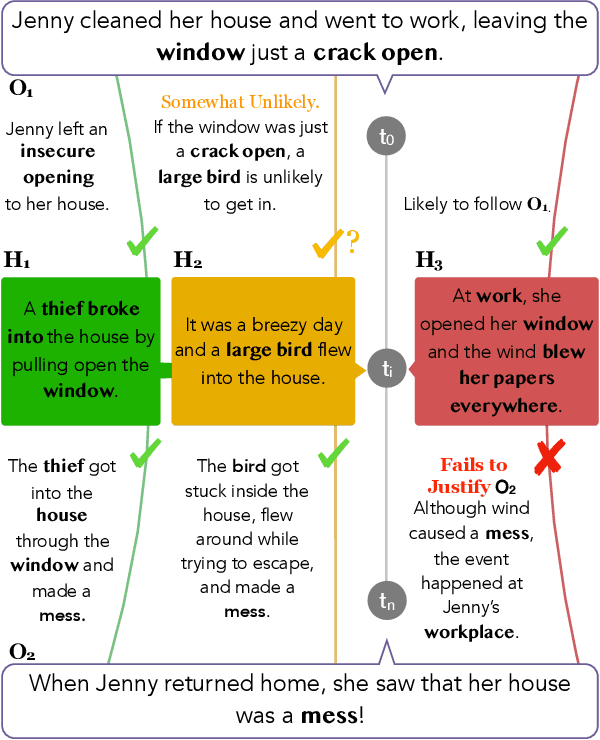
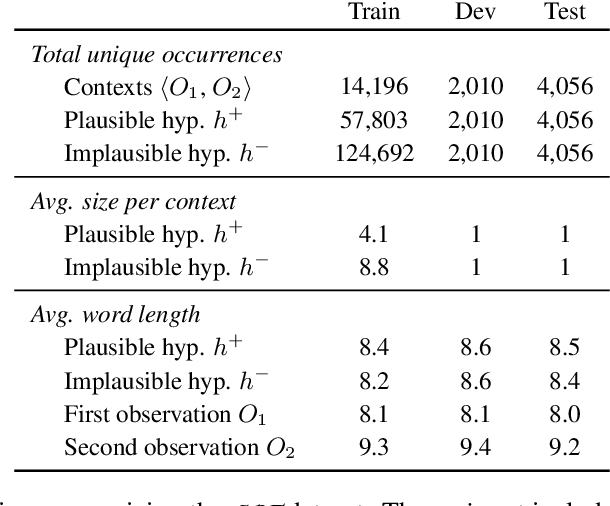
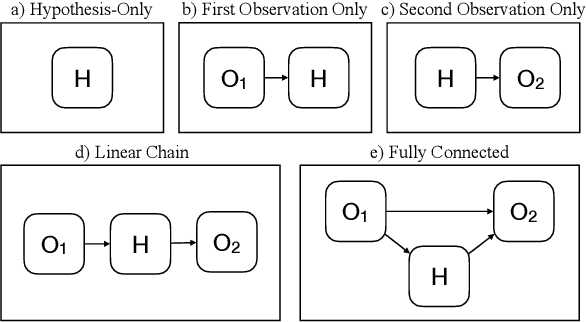
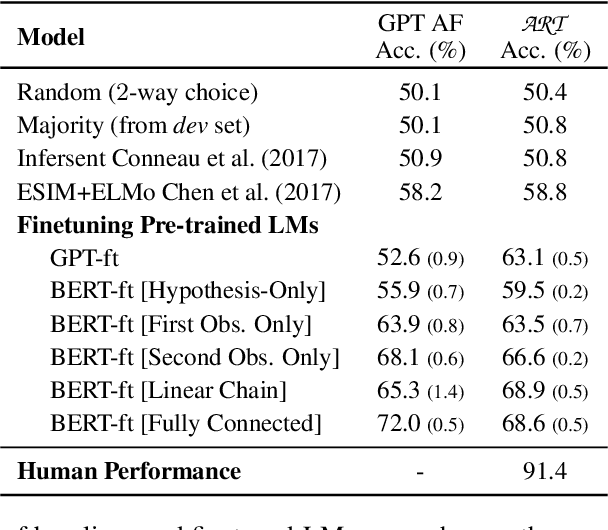
Abductive reasoning is inference to the most plausible explanation. For example, if Jenny finds her house in a mess when she returns from work, and remembers that she left a window open, she can hypothesize that a thief broke into her house and caused the mess, as the most plausible explanation. While abduction has long been considered to be at the core of how people interpret and read between the lines in natural language (Hobbs et al. (1988)), there has been relatively little NLP research in support of abductive natural language inference. We present the first study that investigates the viability of language-based abductive reasoning. We conceptualize a new task of Abductive NLI and introduce a challenge dataset, ART, that consists of over 20k commonsense narrative contexts and 200k explanations, formulated as multiple choice questions for easy automatic evaluation. We establish comprehensive baseline performance on this task based on state-of-the-art NLI and language models, which leads to 68.9% accuracy, well below human performance (91.4%). Our analysis leads to new insights into the types of reasoning that deep pre-trained language models fail to perform -- despite their strong performance on the related but fundamentally different task of entailment NLI -- pointing to interesting avenues for future research.
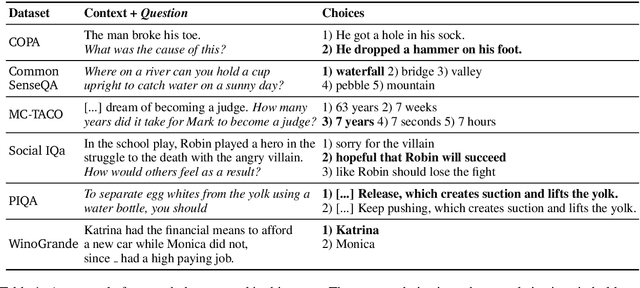
WINOGRANDE: An Adversarial Winograd Schema Challenge at Scale
Jul 24, 2019
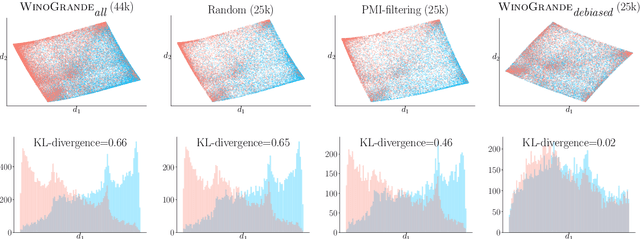
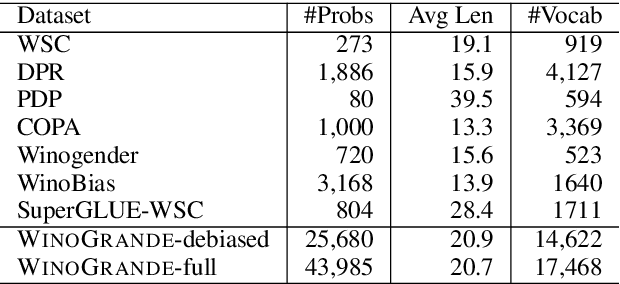

The Winograd Schema Challenge (WSC), proposed by Levesque et al. (2011) as an alternative to the Turing Test, was originally designed as a pronoun resolution problem that cannot be solved based on statistical patterns in large text corpora. However, recent studies suggest that current WSC datasets, even when composed carefully by experts, are still prone to such biases that statistical methods can exploit. We introduce WINOGRANDE, a new collection of WSC problems that are adversarially constructed to be robust against spurious statistical biases. While the original WSC dataset provided only 273 instances, WINOGRANDE includes 43,985 instances, half of which are determined as adversarial. Key to our approach is a novel adversarial filtering algorithm AFLITE for systematic bias reduction, combined with a careful crowdsourcing design. Despite the significant increase in training data, the performance of existing state-of-the-art methods remains modest (61.6%) and contrasts with high human performance (90.8%) for the binary questions. In addition, WINOGRANDE allows us to use transfer learning for achieving new state-of-the-art results on the original WSC and related datasets. Finally, we discuss how biases lead to overestimating the true capabilities of machine commonsense.
Claim Extraction in Biomedical Publications using Deep Discourse Model and Transfer Learning
Jul 01, 2019
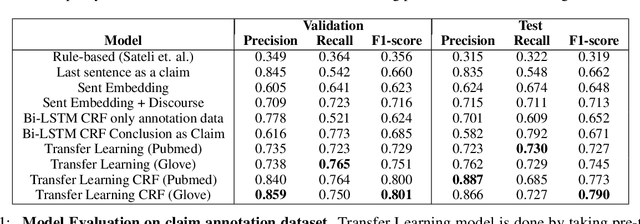
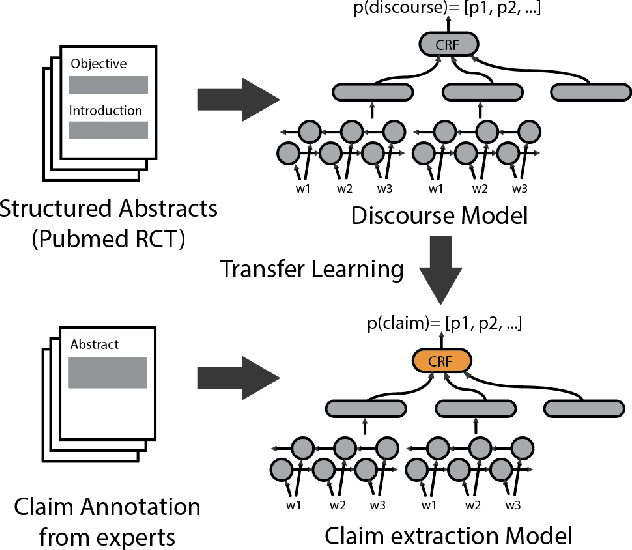
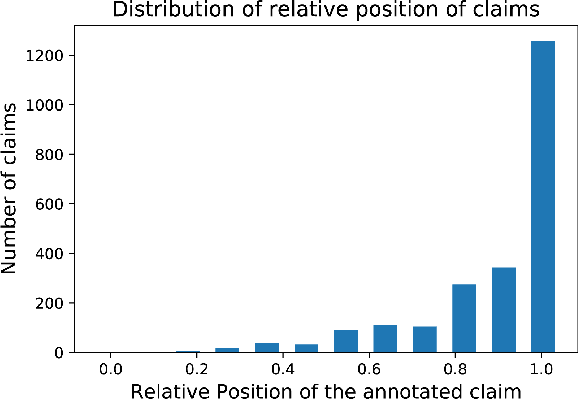
Claims are a fundamental unit of scientific discourse. The exponential growth in the number of scientific publications makes automatic claim extraction an important problem for researchers who are overwhelmed by this information overload. Such an automated claim extraction system is useful for both manual and programmatic exploration of scientific knowledge. In this paper, we introduce an online claim extraction system and a dataset of 1,500 scientific abstracts from the biomedical domain with expert annotations for each sentence indicating whether the sentence presents a scientific claim. We compare our proposed model with several baseline models including rule-based and deep learning techniques. Our transfer learning approach with a fine-tuning step allows us to bootstrap from a large discourse-annotated dataset (Pubmed-RCT) and obtains F1-score over 0.78 for claim detection while using a small annotated dataset of 750 papers. We show that using this pre-trained model based on the discourse prediction task improves F1-score by over 14 percent absolute points compared to a baseline model without discourse structure. We release a publicly accessible tool for discourse model, claim detection model, along with an annotation tool. We discuss further applications beyond Biomedical literature.